 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertificated Actor-Critic: Hierarchical Reinforcement Learning with Control Barrier Functions for Safe Navigation
Jan 29, 2025Control Barrier Functions (CBFs) have emerged as a prominent approach to designing safe navigation systems of robots. Despite their popularity, current CBF-based methods exhibit some limitations: optimization-based safe control techniques tend to be either myopic or computationally intensive, and they rely on simplified system models; conversely, the learning-based methods suffer from the lack of quantitative indication in terms of navigation performance and safety. In this paper, we present a new model-free reinforcement learning algorithm called Certificated Actor-Critic (CAC), which introduces a hierarchical reinforcement learning framework and well-defined reward functions derived from CBFs. We carry out theoretical analysis and proof of our algorithm, and propose several improvements in algorithm implementation. Our analysis is validated by two simulation experiments, showing the effectiveness of our proposed CAC algorithm.
Safety-critical Control with Control Barrier Functions: A Hierarchical Optimization Framework
Oct 21, 2024

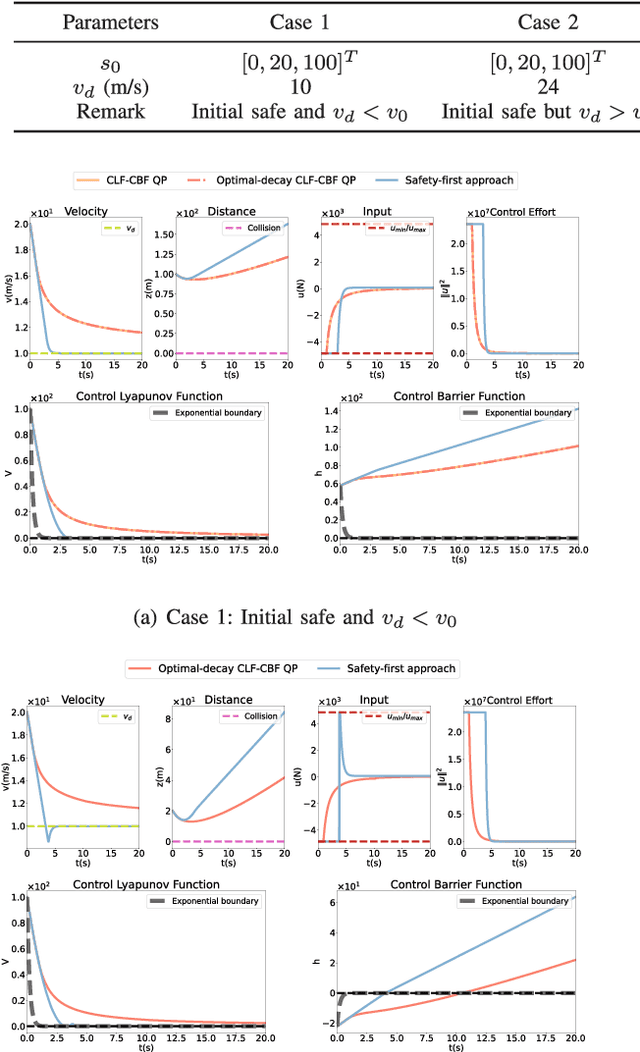
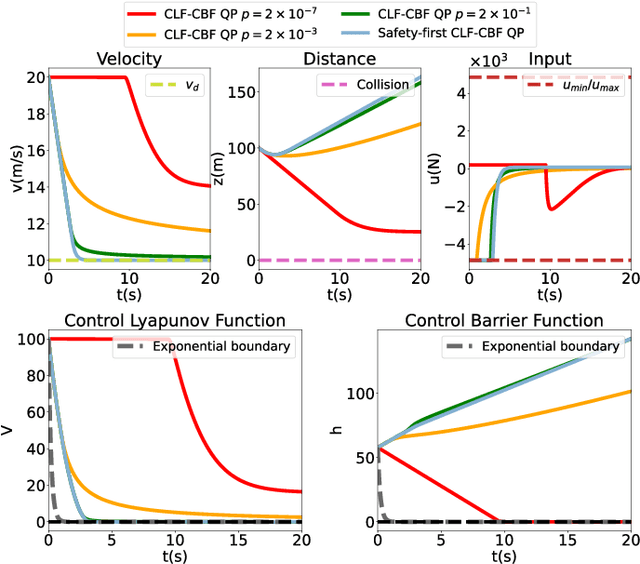
The control barrier function (CBF) has become a fundamental tool in safety-critical systems design since its invention. Typically, the quadratic optimization framework is employed to accommodate CBFs, control Lyapunov functions (CLFs), other constraints and nominal control design. However, the constrained optimization framework involves hyper-parameters to tradeoff different objectives and constraints, which, if not well-tuned beforehand, impact system performance and even lead to infeasibility. In this paper, we propose a hierarchical optimization framework that decomposes the multi-objective optimization problem into nested optimization sub-problems in a safety-first approach. The new framework addresses potential infeasibility on the premise of ensuring safety and performance as much as possible and applies easily in multi-certificate cases. With vivid visualization aids, we systematically analyze the advantages of our proposed method over existing QP-based ones in terms of safety, feasibility and convergence rates. Moreover, two numerical examples are provided that verify our analysis and show the superiority of our proposed method.