 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Convolutional Subspace Clustering Network
May 01, 2019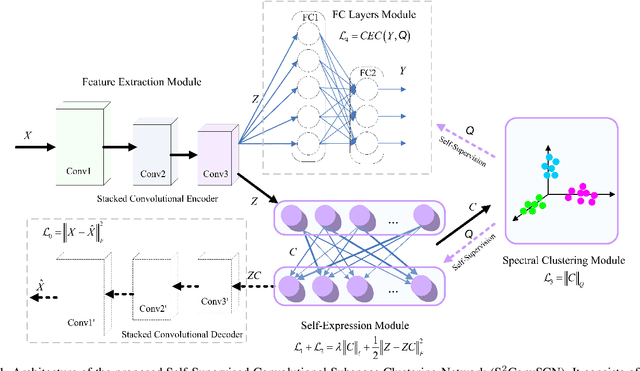
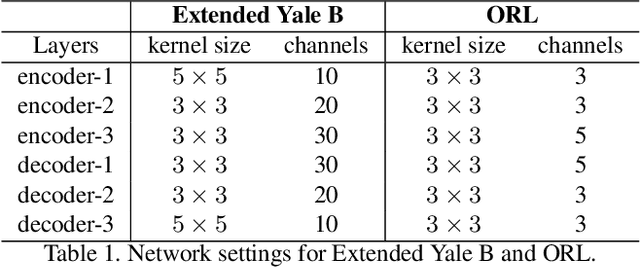
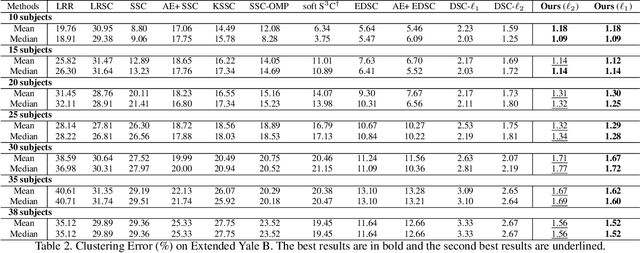
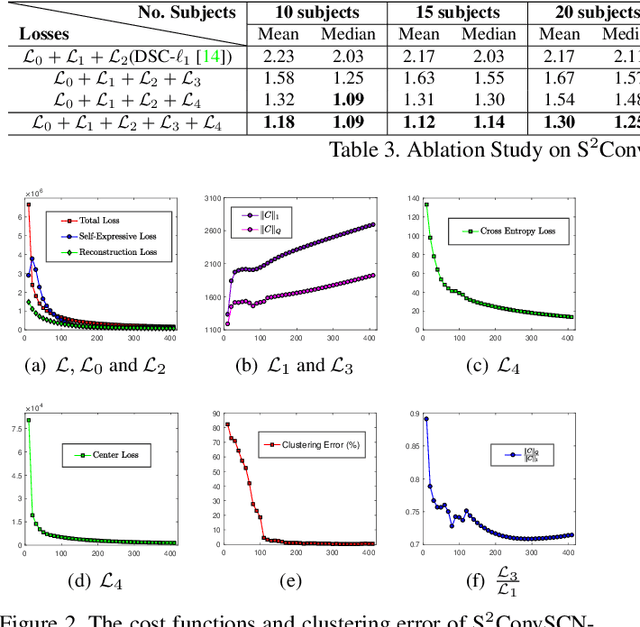
Subspace clustering methods based on data self-expression have become very popular for learning from data that lie in a union of low-dimensional linear subspaces. However, the applicability of subspace clustering has been limited because practical visual data in raw form do not necessarily lie in such linear subspaces. On the other hand, while Convolutional Neural Network (ConvNet) has been demonstrated to be a powerful tool for extracting discriminative features from visual data, training such a ConvNet usually requires a large amount of labeled data, which are unavailable in subspace clustering applications. To achieve simultaneous feature learning and subspace clustering, we propose an end-to-end trainable framework, called Self-Supervised Convolutional Subspace Clustering Network (S$^2$ConvSCN), that combines a ConvNet module (for feature learning), a self-expression module (for subspace clustering) and a spectral clustering module (for self-supervision) into a joint optimization framework. Particularly, we introduce a dual self-supervision that exploits the output of spectral clustering to supervise the training of the feature learning module (via a classification loss) and the self-expression module (via a spectral clustering loss). Our experiments on four benchmark datasets show the effectiveness of the dual self-supervision and demonstrate superior performance of our proposed approach.
Constrained Sparse Subspace Clustering with Side-Information
May 22, 2018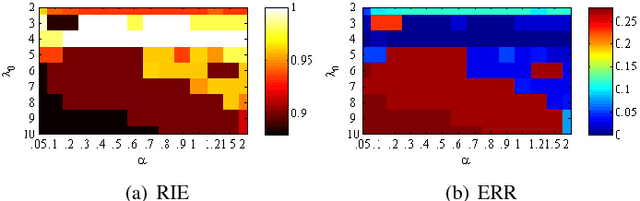
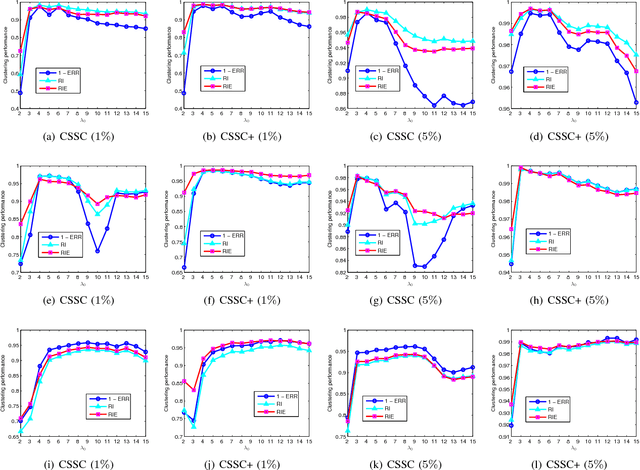

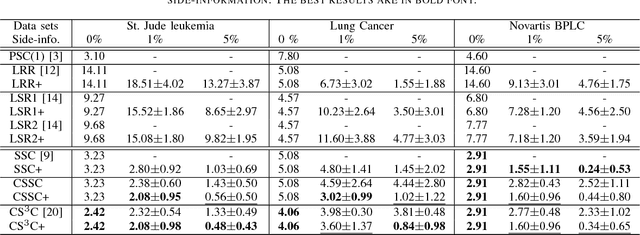
Subspace clustering refers to the problem of segmenting high dimensional data drawn from a union of subspaces into the respective subspaces. In some applications, partial side-information to indicate "must-link" or "cannot-link" in clustering is available. This leads to the task of subspace clustering with side-information. However, in prior work the supervision value of the side-information for subspace clustering has not been fully exploited. To this end, in this paper, we present an enhanced approach for constrained subspace clustering with side-information, termed Constrained Sparse Subspace Clustering plus (CSSC+), in which the side-information is used not only in the stage of learning an affinity matrix but also in the stage of spectral clustering. Moreover, we propose to estimate clustering accuracy based on the partial side-information and theoretically justify the connection to the ground-truth clustering accuracy in terms of the Rand index. We conduct experiments on three cancer gene expression datasets to validate the effectiveness of our proposals.