 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Aware Transformer: Is Attention All Graphs Need?
Jun 09, 2020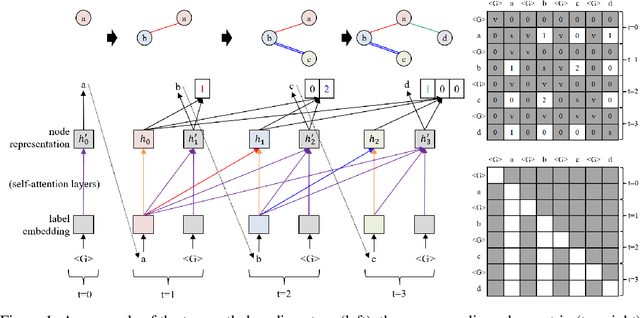

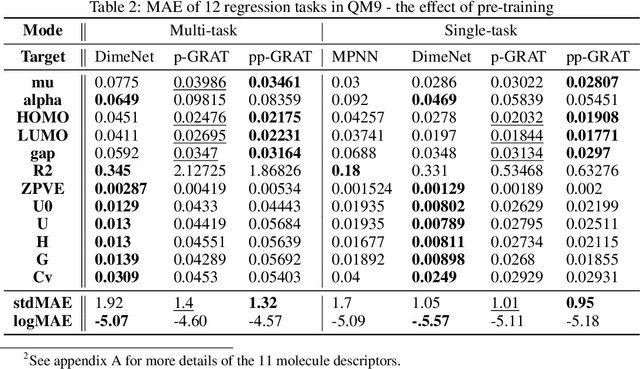
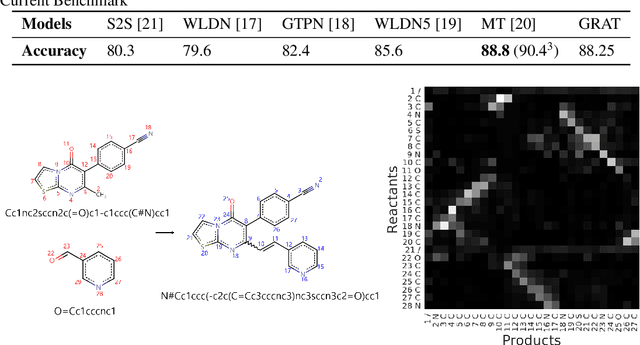
Graphs are the natural data structure to represent relational and structural information in many domains. To cover the broad range of graph-data applications including graph classification as well as graph generation, it is desirable to have a general and flexible model consisting of an encoder and a decoder that can handle graph data. Although the representative encoder-decoder model, Transformer, shows superior performance in various tasks especially of natural language processing, it is not immediately available for graphs due to their non-sequential characteristics. To tackle this incompatibility, we propose GRaph-Aware Transformer (GRAT), the first Transformer-based model which can encode and decode whole graphs in end-to-end fashion. GRAT is featured with a self-attention mechanism adaptive to the edge information and an auto-regressive decoding mechanism based on the two-path approach consisting of sub-graph encoding path and node-and-edge generation path for each decoding step. We empirically evaluated GRAT on multiple setups including encoder-based tasks such as molecule property predictions on QM9 datasets and encoder-decoder-based tasks such as molecule graph generation in the organic molecule synthesis domain. GRAT has shown very promising results including state-of-the-art performance on 4 regression tasks in QM9 benchmark.
Neural Sentence Embedding using Only In-domain Sentences for Out-of-domain Sentence Detection in Dialog Systems
Jul 27, 2018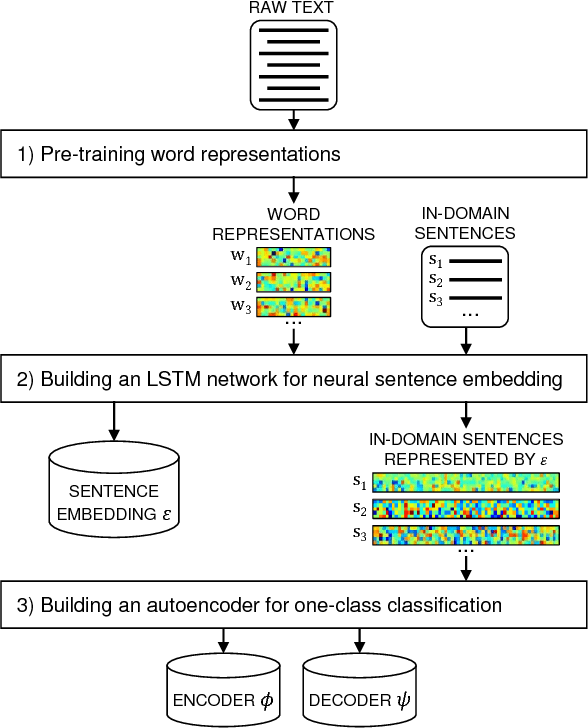
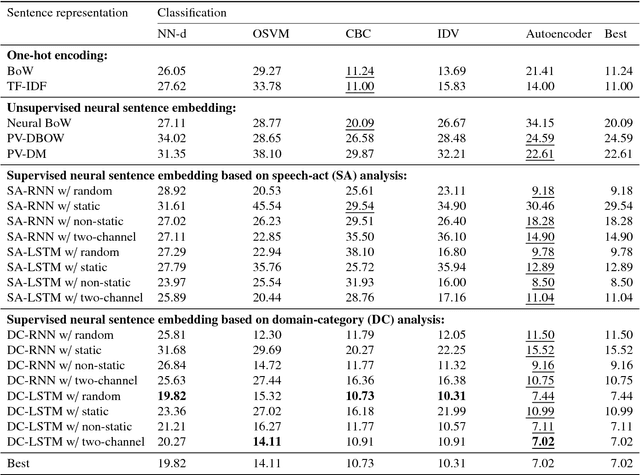


To ensure satisfactory user experience, dialog systems must be able to determine whether an input sentence is in-domain (ID) or out-of-domain (OOD). We assume that only ID sentences are available as training data because collecting enough OOD sentences in an unbiased way is a laborious and time-consuming job. This paper proposes a novel neural sentence embedding method that represents sentences in a low-dimensional continuous vector space that emphasizes aspects that distinguish ID cases from OOD cases. We first used a large set of unlabeled text to pre-train word representations that are used to initialize neural sentence embedding. Then we used domain-category analysis as an auxiliary task to train neural sentence embedding for OOD sentence detection. After the sentence representations were learned, we used them to train an autoencoder aimed at OOD sentence detection. We evaluated our method by experimentally comparing it to the state-of-the-art methods in an eight-domain dialog system; our proposed method achieved the highest accuracy in all tests.