 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
Stereo Superpixel Segmentation Via Decoupled Dynamic Spatial-Embedding Fusion Network
Aug 17, 2022



Stereo superpixel segmentation aims at grouping the discretizing pixels into perceptual regions through left and right views more collaboratively and efficiently. Existing superpixel segmentation algorithms mostly utilize color and spatial features as input, which may impose strong constraints on spatial information while utilizing the disparity information in terms of stereo image pairs. To alleviate this issue, we propose a stereo superpixel segmentation method with a decoupling mechanism of spatial information in this work. To decouple stereo disparity information and spatial information, the spatial information is temporarily removed before fusing the features of stereo image pairs, and a decoupled stereo fusion module (DSFM) is proposed to handle the stereo features alignment as well as occlusion problems. Moreover, since the spatial information is vital to superpixel segmentation, we further design a dynamic spatiality embedding module (DSEM) to re-add spatial information, and the weights of spatial information will be adaptively adjusted through the dynamic fusion (DF) mechanism in DSEM for achieving a finer segmentation. Comprehensive experimental results demonstrate that our method can achieve the state-of-the-art performance on the KITTI2015 and Cityscapes datasets, and also verify the efficiency when applied in salient object detection on NJU2K dataset. The source code will be available publicly after paper is accepted.
Spot the Difference by Object Detection
Jan 03, 2018
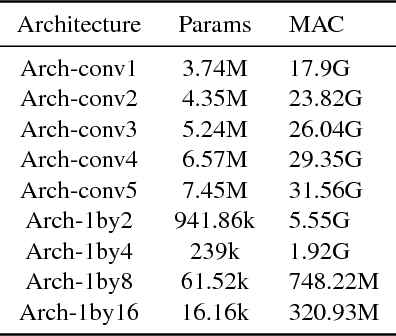
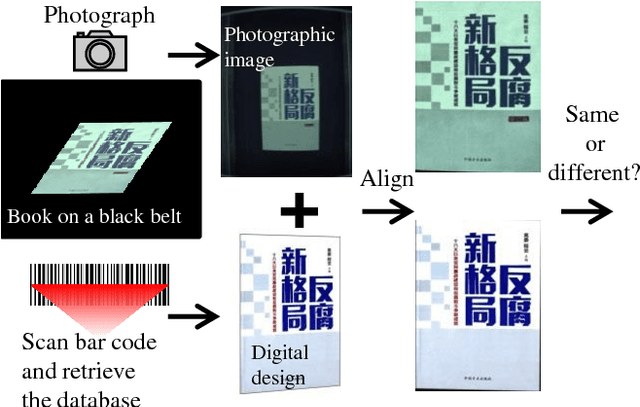
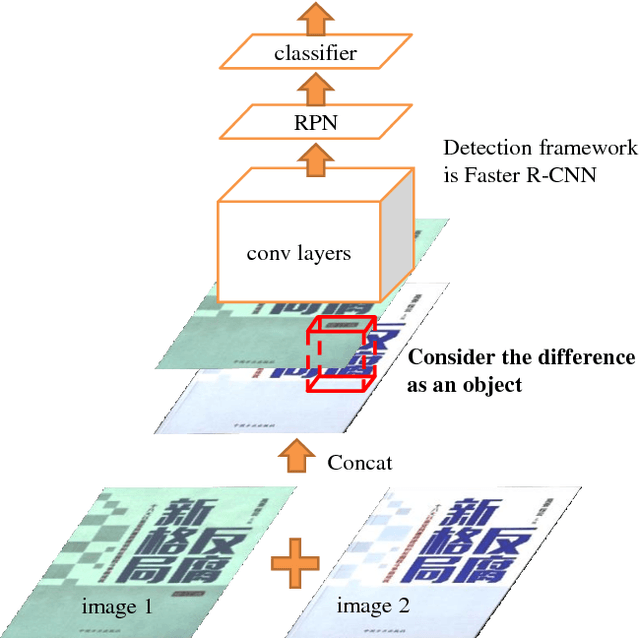
In this paper, we propose a simple yet effective solution to a change detection task that detects the difference between two images, which we call "spot the difference". Our approach uses CNN-based object detection by stacking two aligned images as input and considering the differences between the two images as objects to detect. An early-merging architecture is used as the backbone network. Our method is accurate, fast and robust while using very cheap annotation. We verify the proposed method on the task of change detection between the digital design and its photographic image of a book. Compared to verification based methods, our object detection based method outperforms other methods by a large margin and gives extra information of location. We compress the network and achieve 24 times acceleration while keeping the accuracy. Besides, as we synthesize the training data for detection using weakly labeled images, our method does not need expensive bounding box annotation.