 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object-Centric Representation via Reverse Hierarchy Guidance
May 17, 2024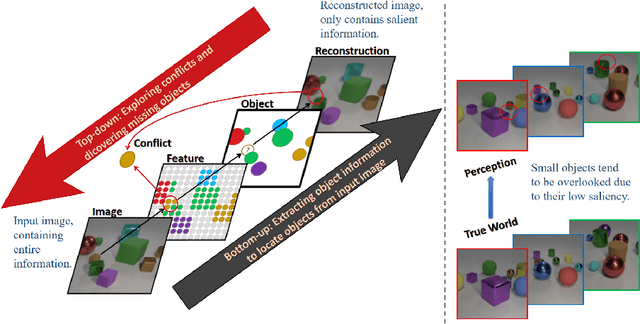
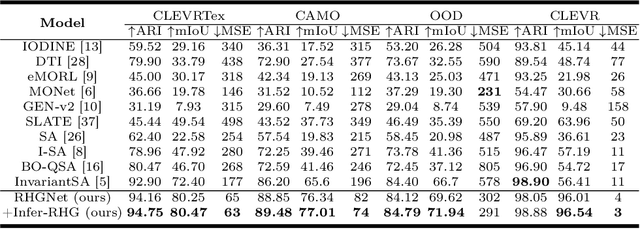
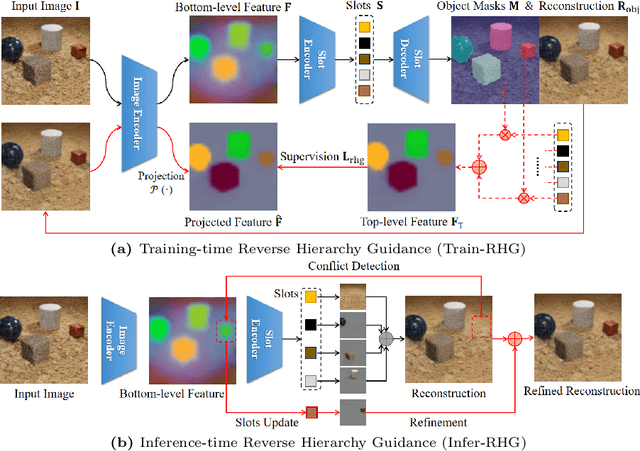
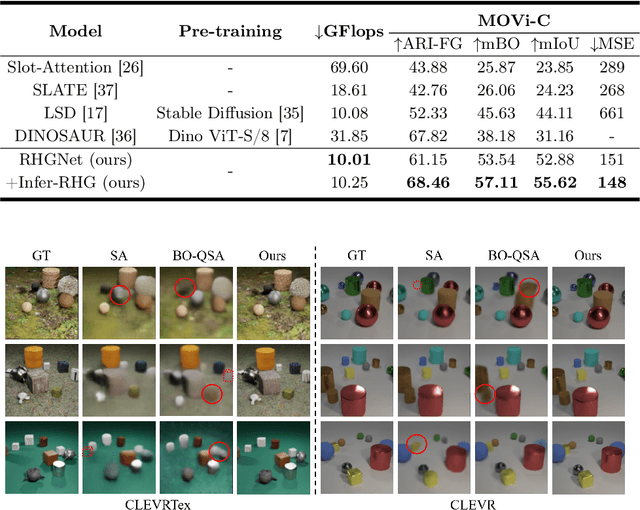
Object-Centric Learning (OCL) seeks to enable Neural Networks to identify individual objects in visual scenes, which is crucial for interpretable visual comprehension and reasoning. Most existing OCL models adopt auto-encoding structures and learn to decompose visual scenes through specially designed inductive bias, which causes the model to miss small objects during reconstruction. Reverse hierarchy theory proposes that human vision corrects perception errors through a top-down visual pathway that returns to bottom-level neurons and acquires more detailed information, inspired by which we propose Reverse Hierarchy Guided Network (RHGNet) that introduces a top-down pathway that works in different ways in the training and inference processes. This pathway allows for guiding bottom-level features with top-level object representations during training, as well as encompassing information from bottom-level features into perception during inference. Our model achieves SOTA performance on several commonly used datasets including CLEVR, CLEVRTex and MOVi-C. We demonstrate with experiments that our method promotes the discovery of small objects and also generalizes well on complex real-world scenes. Code will be available at https://anonymous.4open.science/r/RHGNet-6CEF.
Semantic Segmentation on VSPW Dataset through Aggregation of Transformer Models
Sep 03, 2021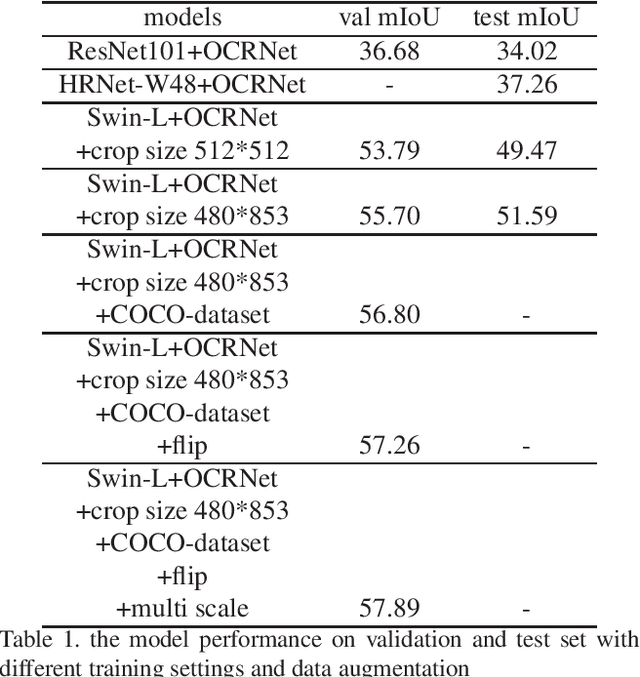
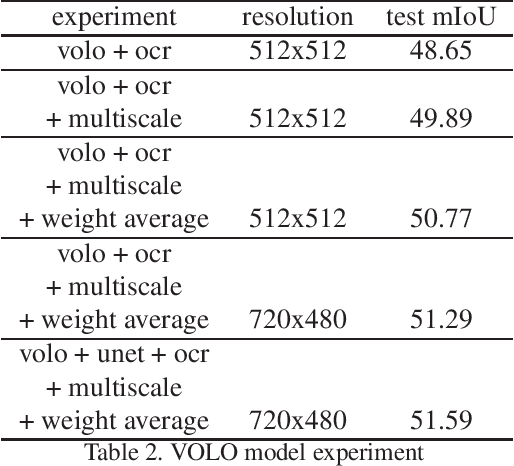
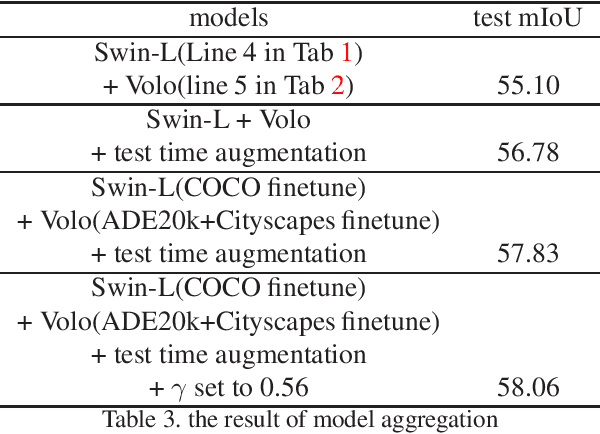
Semantic segmentation is an important task in computer vision, from which some important usage scenarios are derived, such as autonomous driving, scene parsing, etc. Due to the emphasis on the task of video semantic segmentation, we participated in this competition. In this report, we briefly introduce the solutions of team 'BetterThing' for the ICCV2021 - Video Scene Parsing in the Wild Challenge. Transformer is used as the backbone for extracting video frame features, and the final result is the aggregation of the output of two Transformer models, SWIN and VOLO. This solution achieves 57.3% mIoU, which is ranked 3rd place in the Video Scene Parsing in the Wild Challenge.