 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartMix: Regularization Strategy to Learn Part Discovery for Visible-Infrared Person Re-identification
Apr 04, 2023Modern data augmentation using a mixture-based technique can regularize the models from overfitting to the training data in various computer vision applications, but a proper data augmentation technique tailored for the part-based Visible-Infrared person Re-IDentification (VI-ReID) models remains unexplored. In this paper, we present a novel data augmentation technique, dubbed PartMix, that synthesizes the augmented samples by mixing the part descriptors across the modalities to improve the performance of part-based VI-ReID models. Especially, we synthesize the positive and negative samples within the same and across different identities and regularize the backbone model through contrastive learning. In addition, we also present an entropy-based mining strategy to weaken the adverse impact of unreliable positive and negative samples. When incorporated into existing part-based VI-ReID model, PartMix consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our PartMix over the existing VI-ReID methods and provide ablation studies.
Cross-Domain Grouping and Alignment for Domain Adaptive Semantic Segmentation
Dec 17, 2020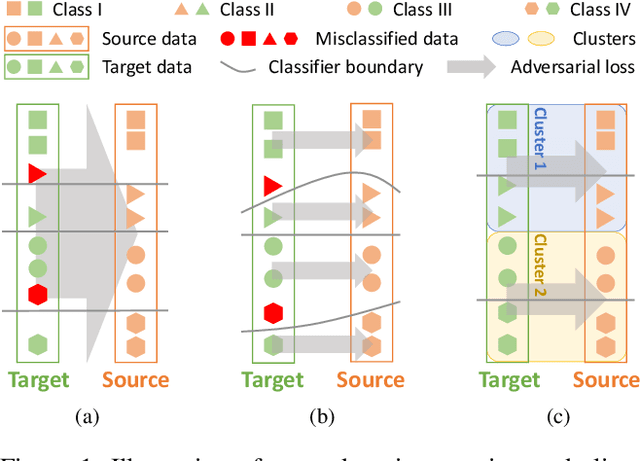
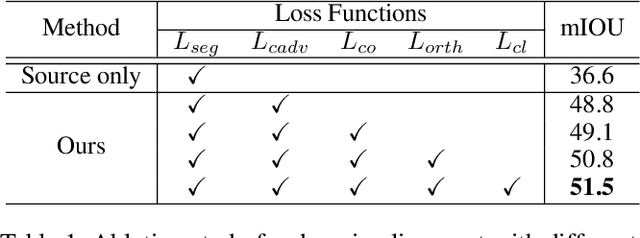

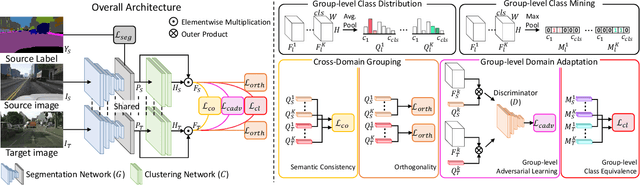
Existing techniques to adapt semantic segmentation networks across the source and target domains within deep convolutional neural networks (CNNs) deal with all the samples from the two domains in a global or category-aware manner. They do not consider an inter-class variation within the target domain itself or estimated category, providing the limitation to encode the domains having a multi-modal data distribution. To overcome this limitation, we introduce a learnable clustering module, and a novel domain adaptation framework called cross-domain grouping and alignment. To cluster the samples across domains with an aim to maximize the domain alignment without forgetting precise segmentation ability on the source domain, we present two loss functions, in particular, for encouraging semantic consistency and orthogonality among the clusters. We also present a loss so as to solve a class imbalance problem, which is the other limitation of the previous methods. Our experiments show that our method consistently boosts the adaptation performance in semantic segmentation, outperforming the state-of-the-arts on various domain adaptation settings.