 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Category-Level Manipulation Tasks from Point Clouds with Dynamic Graph CNNs
Sep 13, 2022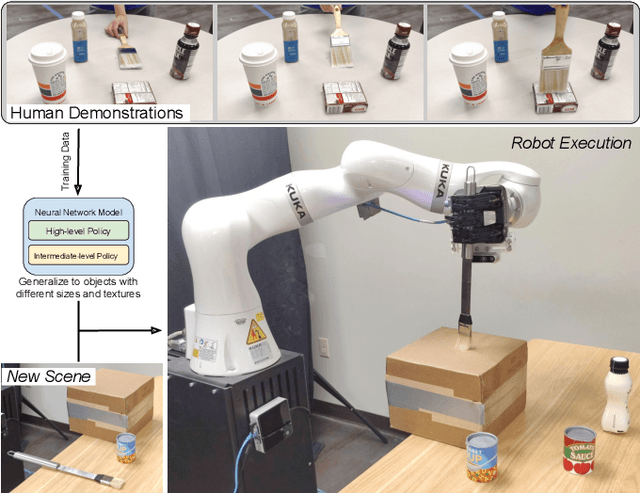
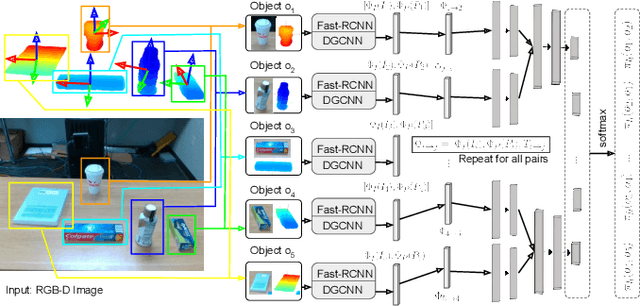
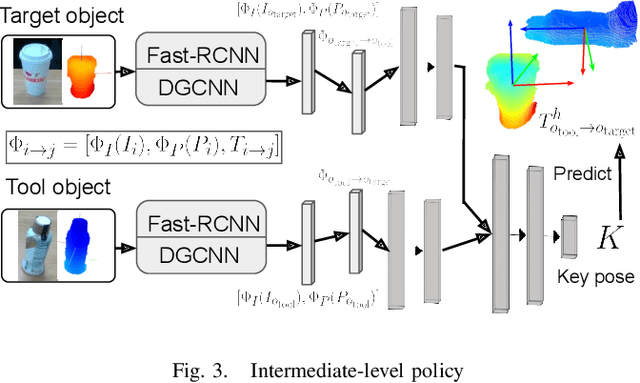

This paper presents a new technique for learning category-level manipulation from raw RGB-D videos of task demonstrations, with no manual labels or annotations. Category-level learning aims to acquire skills that can be generalized to new objects, with geometries and textures that are different from the ones of the objects used in the demonstrations. We address this problem by first viewing both grasping and manipulation as special cases of tool use, where a tool object is moved to a sequence of key-poses defined in a frame of reference of a target object. Tool and target objects, along with their key-poses, are predicted using a dynamic graph convolutional neural network that takes as input an automatically segmented depth and color image of the entire scene. Empirical results on object manipulation tasks with a real robotic arm show that the proposed network can efficiently learn from real visual demonstrations to perform the tasks on novel objects within the same category, and outperforms alternative approaches.
Learning Sensorimotor Primitives of Sequential Manipulation Tasks from Visual Demonstrations
Mar 08, 2022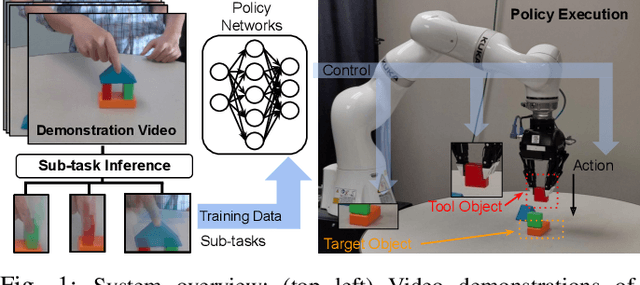
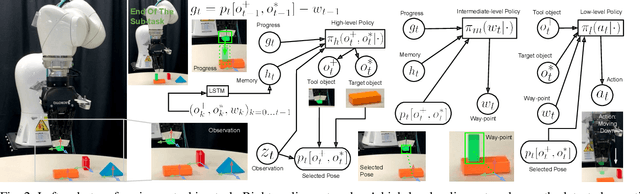

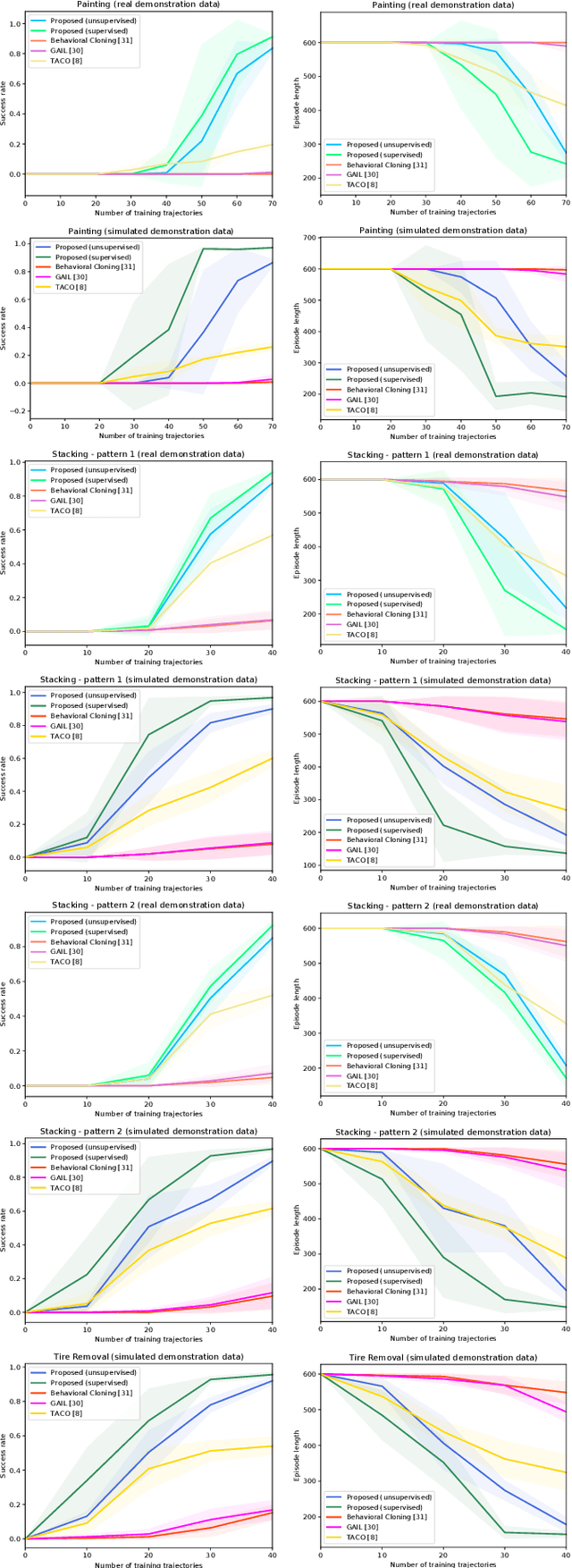
This work aims to learn how to perform complex robot manipulation tasks that are composed of several, consecutively executed low-level sub-tasks, given as input a few visual demonstrations of the tasks performed by a person. The sub-tasks consist of moving the robot's end-effector until it reaches a sub-goal region in the task space, performing an action, and triggering the next sub-task when a pre-condition is met. Most prior work in this domain has been concerned with learning only low-level tasks, such as hitting a ball or reaching an object and grasping it. This paper describes a new neural network-based framework for learning simultaneously low-level policies as well as high-level policies, such as deciding which object to pick next or where to place it relative to other objects in the scene. A key feature of the proposed approach is that the policies are learned directly from raw videos of task demonstrations, without any manual annotation or post-processing of the data. Empirical results on object manipulation tasks with a robotic arm show that the proposed network can efficiently learn from real visual demonstrations to perform the tasks, and outperforms popular imitation learning algorithms.
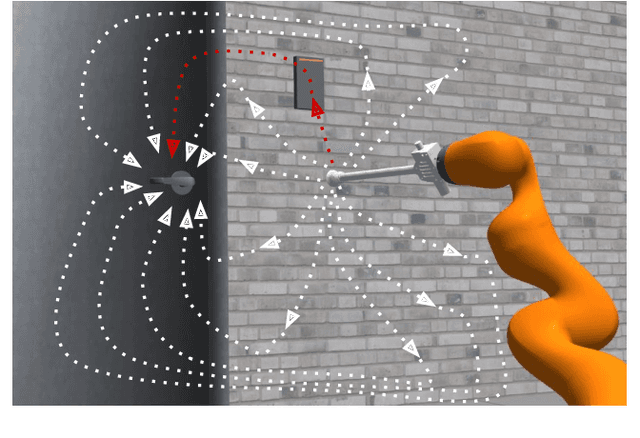
Vision-driven Compliant Manipulation for Reliable, High-Precision Assembly Tasks
Jun 26, 2021
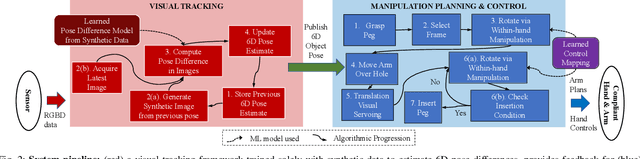
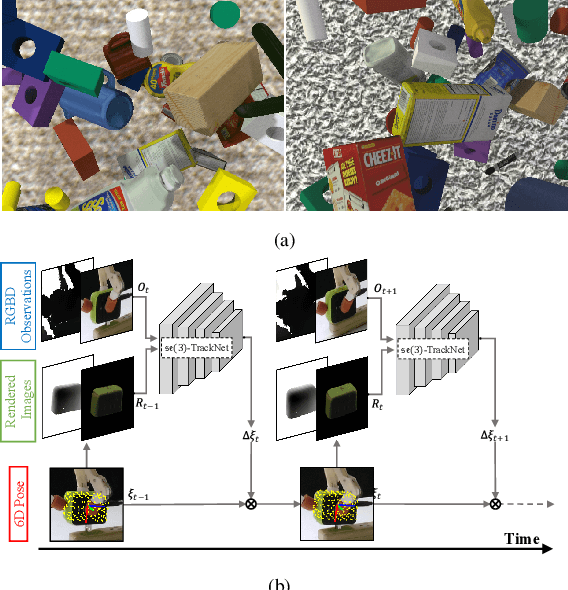
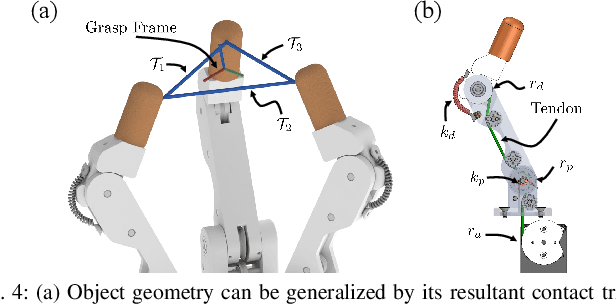
Highly constrained manipulation tasks continue to be challenging for autonomous robots as they require high levels of precision, typically less than 1mm, which is often incompatible with what can be achieved by traditional perception systems. This paper demonstrates that the combination of state-of-the-art object tracking with passively adaptive mechanical hardware can be leveraged to complete precision manipulation tasks with tight, industrially-relevant tolerances (0.25mm). The proposed control method closes the loop through vision by tracking the relative 6D pose of objects in the relevant workspace. It adjusts the control reference of both the compliant manipulator and the hand to complete object insertion tasks via within-hand manipulation. Contrary to previous efforts for insertion, our method does not require expensive force sensors, precision manipulators, or time-consuming, online learning, which is data hungry. Instead, this effort leverages mechanical compliance and utilizes an object agnostic manipulation model of the hand learned offline, off-the-shelf motion planning, and an RGBD-based object tracker trained solely with synthetic data. These features allow the proposed system to easily generalize and transfer to new tasks and environments. This paper describes in detail the system components and showcases its efficacy with extensive experiments involving tight tolerance peg-in-hole insertion tasks of various geometries as well as open-world constrained placement tasks.
Learning Transition Models with Time-delayed Causal Relations
Aug 04, 2020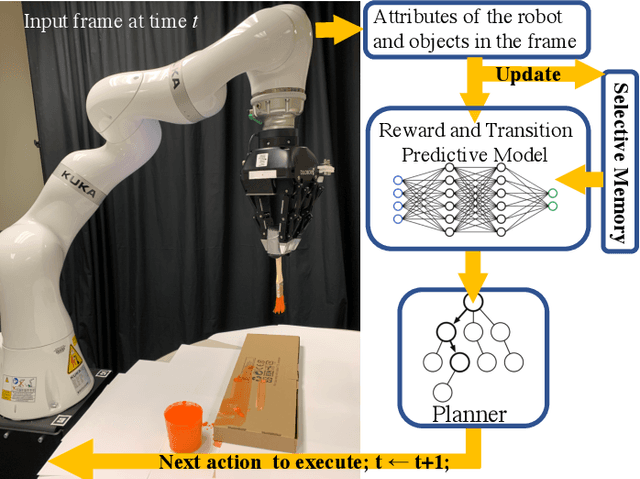
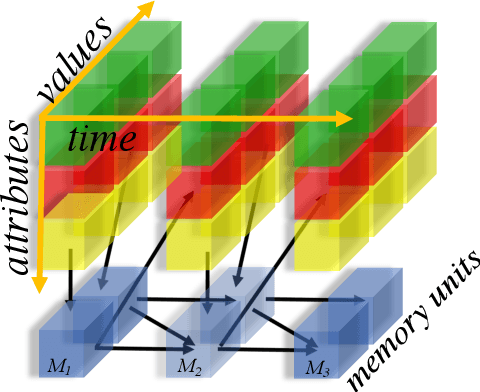

This paper introduces an algorithm for discovering implicit and delayed causal relations between events observed by a robot at arbitrary times, with the objective of improving data-efficiency and interpretability of model-based reinforcement learning (RL) techniques. The proposed algorithm initially predicts observations with the Markov assumption, and incrementally introduces new hidden variables to explain and reduce the stochasticity of the observations. The hidden variables are memory units that keep track of pertinent past events. Such events are systematically identified by their information gains. The learned transition and reward models are then used for planning. Experiments on simulated and real robotic tasks show that this method significantly improves over current RL techniques.
Task-Relevant Object Discovery and Categorization for Playing First-person Shooter Games
Jun 17, 2018
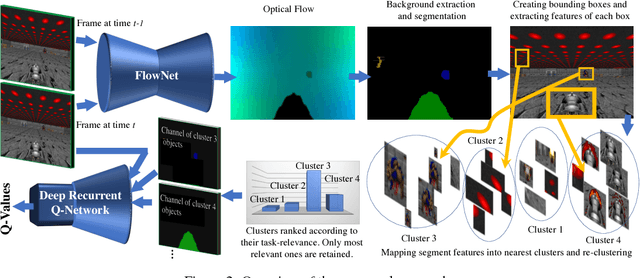
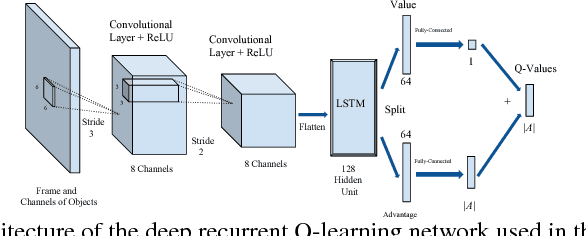
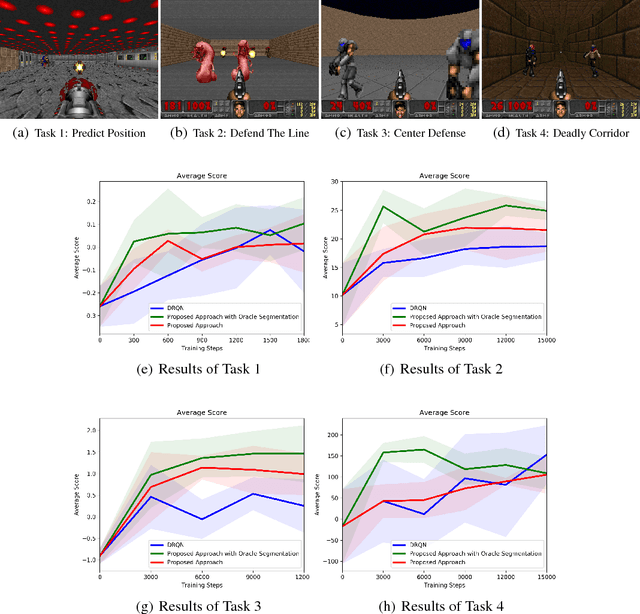
We consider the problem of learning to play first-person shooter (FPS) video games using raw screen images as observations and keyboard inputs as actions. The high-dimensionality of the observations in this type of applications leads to prohibitive needs of training data for model-free methods, such as the deep Q-network (DQN), and its recurrent variant DRQN. Thus, recent works focused on learning low-dimensional representations that may reduce the need for data. This paper presents a new and efficient method for learning such representations. Salient segments of consecutive frames are detected from their optical flow, and clustered based on their feature descriptors. The clusters typically correspond to different discovered categories of objects. Segments detected in new frames are then classified based on their nearest clusters. Because only a few categories are relevant to a given task, the importance of a category is defined as the correlation between its occurrence and the agent's performance. The result is encoded as a vector indicating objects that are in the frame and their locations, and used as a side input to DRQN. Experiments on the game Doom provide a good evidence for the benefit of this approach.