 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Bayesian Deep Learning for Explainable Decision Support Systems Based on Medical Imaging
Feb 12, 2026In critical decision support systems based on medical imaging, the reliability of AI-assisted decision-making is as relevant as predictive accuracy. Although deep learning models have demonstrated significant accuracy, they frequently suffer from miscalibration, manifested as overconfidence in erroneous predictions. To facilitate clinical acceptance, it is imperative that models quantify uncertainty in a manner that correlates with prediction correctness, allowing clinicians to identify unreliable outputs for further review. In order to address this necessity, the present paper proposes a generalizable probabilistic optimization framework grounded in Bayesian deep learning. Specifically, a novel Confidence-Uncertainty Boundary Loss (CUB-Loss) is introduced that imposes penalties on high-certainty errors and low-certainty correct predictions, explicitly enforcing alignment between prediction correctness and uncertainty estimates. Complementing this training-time optimization, a Dual Temperature Scaling (DTS) strategy is devised for post-hoc calibration, further refining the posterior distribution to improve intuitive explainability. The proposed framework is validated on three distinct medical imaging tasks: automatic screening of pneumonia, diabetic retinopathy detection, and identification of skin lesions. Empirical results demonstrate that the proposed approach achieves consistent calibration improvements across diverse modalities, maintains robust performance in data-scarce scenarios, and remains effective on severely imbalanced datasets, underscoring its potential for real clinical deployment.
NeuroVoz: a Castillian Spanish corpus of parkinsonian speech
Mar 06, 2024The advancement of Parkinson's Disease (PD) diagnosis through speech analysis is hindered by a notable lack of publicly available, diverse language datasets, limiting the reproducibility and further exploration of existing research. In response to this gap, we introduce a comprehensive corpus from 108 native Castilian Spanish speakers, comprising 55 healthy controls and 53 individuals diagnosed with PD, all of whom were under pharmacological treatment and recorded in their medication-optimized state. This unique dataset features a wide array of speech tasks, including sustained phonation of the five Spanish vowels, diadochokinetic tests, 16 listen-and-repeat utterances, and free monologues. The dataset emphasizes accuracy and reliability through specialist manual transcriptions of the listen-and-repeat tasks and utilizes Whisper for automated monologue transcriptions, making it the most complete public corpus of Parkinsonian speech, and the first in Castillian Spanish. NeuroVoz is composed by 2,903 audio recordings averaging $26.88 \pm 3.35$ recordings per participant, offering a substantial resource for the scientific exploration of PD's impact on speech. This dataset has already underpinned several studies, achieving a benchmark accuracy of 89% in PD speech pattern identification, indicating marked speech alterations attributable to PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains an open area for future research. This contribution not only fills a critical void in PD speech analysis resources but also sets a new standard for the global research community in leveraging speech as a diagnostic tool for neurodegenerative diseases.
An Instance Selection Algorithm for Big Data in High imbalanced datasets based on LSH
Oct 09, 2022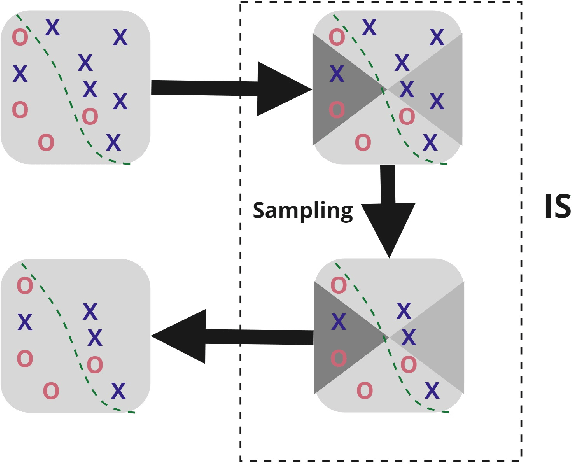
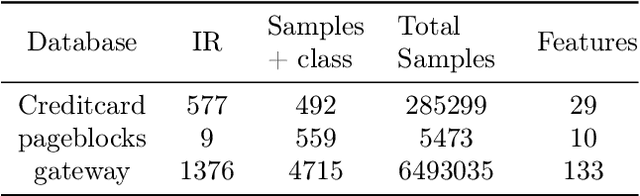
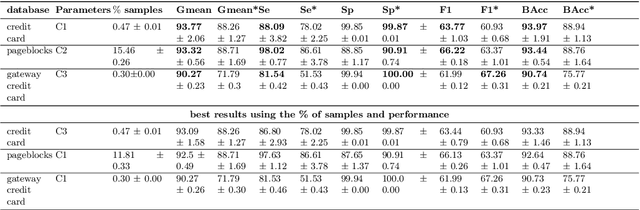
Training of Machine Learning (ML) models in real contexts often deals with big data sets and high-class imbalance samples where the class of interest is unrepresented (minority class). Practical solutions using classical ML models address the problem of large data sets using parallel/distributed implementations of training algorithms, approximate model-based solutions, or applying instance selection (IS) algorithms to eliminate redundant information. However, the combined problem of big and high imbalanced datasets has been less addressed. This work proposes three new methods for IS to be able to deal with large and imbalanced data sets. The proposed methods use Locality Sensitive Hashing (LSH) as a base clustering technique, and then three different sampling methods are applied on top of the clusters (or buckets) generated by LSH. The algorithms were developed in the Apache Spark framework, guaranteeing their scalability. The experiments carried out in three different datasets suggest that the proposed IS methods can improve the performance of a base ML model between 5% and 19% in terms of the geometric mean.
An enhanced Conv-TasNet model for speech separation using a speaker distance-based loss function
Jun 01, 2022
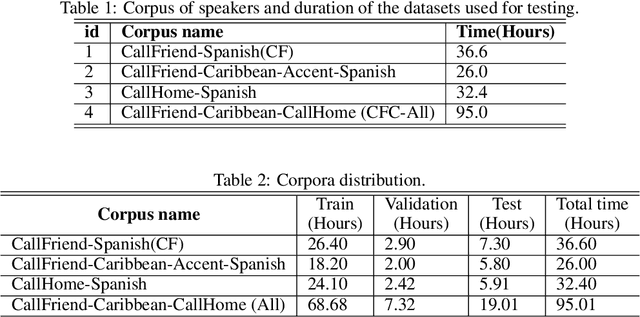
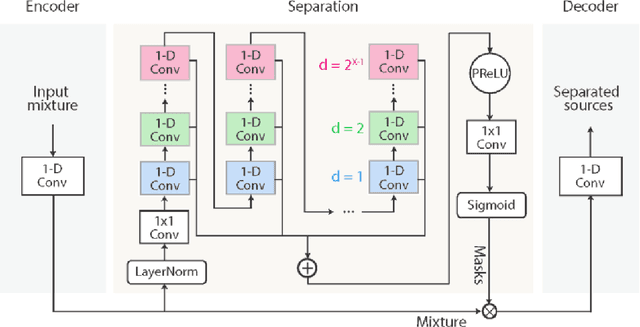
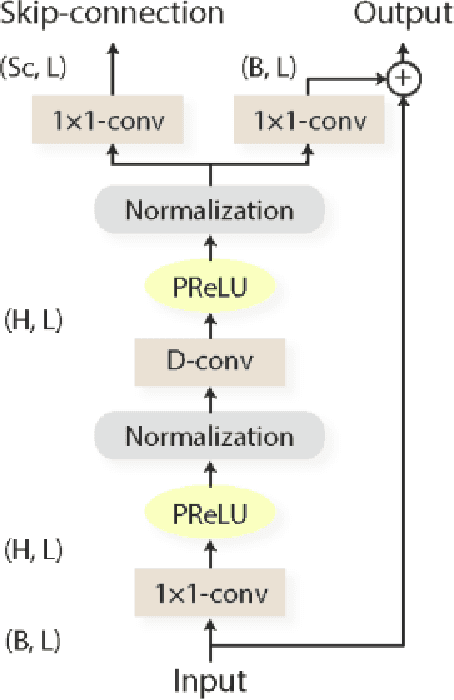
This work addresses the problem of speech separation in the Spanish Language using pre-trained deep learning models. As with many speech processing tasks, large databases in other languages different from English are scarce. Therefore this work explores different training strategies using the Conv-TasNet model as a benchmark. A scale-invariant signal distortion ratio (SI-SDR) metric value of 9.9 dB was achieved for the best training strategy. Then, experimentally, we identified an inverse relationship between the speakers' similarity and the model's performance, so an improved ConvTasNet architecture was proposed. The enhanced Conv-TasNet model uses pre-trained speech embeddings to add a between-speakers cosine similarity term in the cost function, yielding an SI-SDR of 10.6 dB. Lastly, some insights and drawbacks about the real-time deployment of the model.
Fake News Detection in Spanish Using Deep Learning Techniques
Oct 13, 2021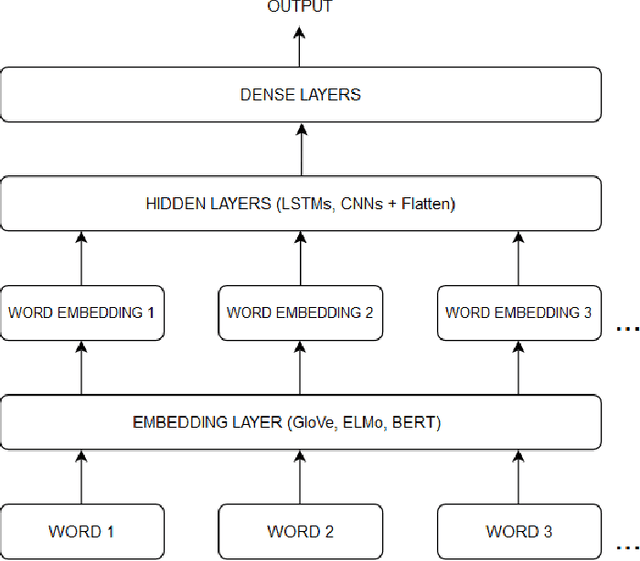

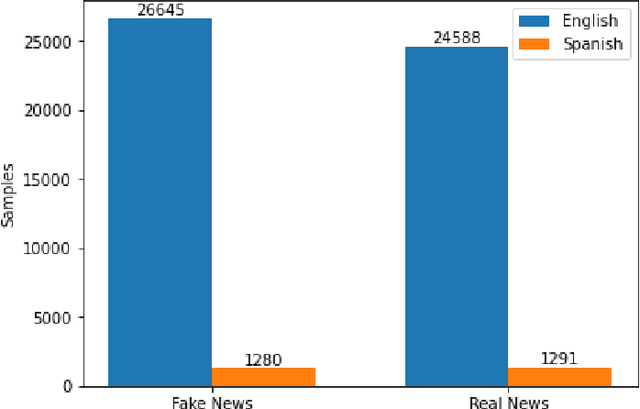
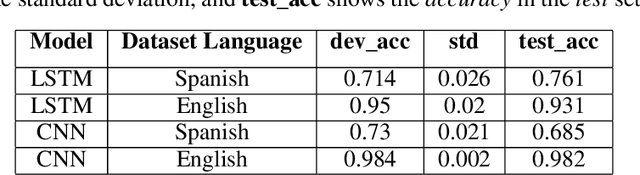
This paper addresses the problem of fake news detection in Spanish using Machine Learning techniques. It is fundamentally the same problem tackled for the English language; however, there is not a significant amount of publicly available and adequately labeled fake news in Spanish to effectively train a Machine Learning model, similarly to those proposed for the English language. Therefore, this work explores different training strategies and architectures to establish a baseline for further research in this area. Four datasets were used, two in English and two in Spanish, and four experimental schemes were tested, including a baseline with classical Machine Learning models, trained and validated using a small dataset in Spanish. The remaining schemes include state-of-the-art Deep Learning models trained (or fine-tuned) and validated in English, trained and validated in Spanish, and fitted in English and validated with automatic translated Spanish sentences. The Deep Learning architectures were built on top of different pre-trained Word Embedding representations, including GloVe, ELMo, BERT, and BETO (a BERT version trained on a large corpus in Spanish). According to the results, the best strategy was a combination of a pre-trained BETO model and a Recurrent Neural Network based on LSTM layers, yielding an accuracy of up to 80%; nonetheless, a baseline model using a Random Forest estimator obtained similar outcomes. Additionally, the translation strategy did not yield acceptable results because of the propagation error; there was also observed a significant difference in models performance when trained in English or Spanish, mainly attributable to the number of samples available for each language.