 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Bayesian Deep Learning for Explainable Decision Support Systems Based on Medical Imaging
Feb 12, 2026In critical decision support systems based on medical imaging, the reliability of AI-assisted decision-making is as relevant as predictive accuracy. Although deep learning models have demonstrated significant accuracy, they frequently suffer from miscalibration, manifested as overconfidence in erroneous predictions. To facilitate clinical acceptance, it is imperative that models quantify uncertainty in a manner that correlates with prediction correctness, allowing clinicians to identify unreliable outputs for further review. In order to address this necessity, the present paper proposes a generalizable probabilistic optimization framework grounded in Bayesian deep learning. Specifically, a novel Confidence-Uncertainty Boundary Loss (CUB-Loss) is introduced that imposes penalties on high-certainty errors and low-certainty correct predictions, explicitly enforcing alignment between prediction correctness and uncertainty estimates. Complementing this training-time optimization, a Dual Temperature Scaling (DTS) strategy is devised for post-hoc calibration, further refining the posterior distribution to improve intuitive explainability. The proposed framework is validated on three distinct medical imaging tasks: automatic screening of pneumonia, diabetic retinopathy detection, and identification of skin lesions. Empirical results demonstrate that the proposed approach achieves consistent calibration improvements across diverse modalities, maintains robust performance in data-scarce scenarios, and remains effective on severely imbalanced datasets, underscoring its potential for real clinical deployment.
Radar Network for Gait Monitoring: Technology and Validation
Feb 18, 2025In recent years, radar-based devices have emerged as an alternative approach for gait monitoring. However, the radar configuration and the algorithms used to extract the gait parameters often differ between contributions, lacking a systematic evaluation of the most appropriate setup. Additionally, radar-based studies often exclude motorically impaired subjects, leaving it unclear whether the existing algorithms are applicable to such populations. In this paper, a radar network is developed and validated by monitoring the gait of five healthy individuals and three patients with Parkinson's disease. Six configurations and four algorithms were compared using Vicon as ground-truth to determine the most appropriate solution for gait monitoring. The best results were obtained using only three nodes: two oriented towards the feet and one towards the torso. The most accurate stride velocity and distance in the state of the art were obtained with this configuration. Moreover, we show that analyzing the feet velocity increases the reliability of the temporal parameters, especially with aged or motorically impaired subjects. The contribution is significant for the implementation of radar networks in clinical and domestic environments, as it addresses critical aspects concerning the radar network configuration and algorithms.
NeuroVoz: a Castillian Spanish corpus of parkinsonian speech
Mar 06, 2024The advancement of Parkinson's Disease (PD) diagnosis through speech analysis is hindered by a notable lack of publicly available, diverse language datasets, limiting the reproducibility and further exploration of existing research. In response to this gap, we introduce a comprehensive corpus from 108 native Castilian Spanish speakers, comprising 55 healthy controls and 53 individuals diagnosed with PD, all of whom were under pharmacological treatment and recorded in their medication-optimized state. This unique dataset features a wide array of speech tasks, including sustained phonation of the five Spanish vowels, diadochokinetic tests, 16 listen-and-repeat utterances, and free monologues. The dataset emphasizes accuracy and reliability through specialist manual transcriptions of the listen-and-repeat tasks and utilizes Whisper for automated monologue transcriptions, making it the most complete public corpus of Parkinsonian speech, and the first in Castillian Spanish. NeuroVoz is composed by 2,903 audio recordings averaging $26.88 \pm 3.35$ recordings per participant, offering a substantial resource for the scientific exploration of PD's impact on speech. This dataset has already underpinned several studies, achieving a benchmark accuracy of 89% in PD speech pattern identification, indicating marked speech alterations attributable to PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains an open area for future research. This contribution not only fills a critical void in PD speech analysis resources but also sets a new standard for the global research community in leveraging speech as a diagnostic tool for neurodegenerative diseases.
Artificial Intelligence applied to chest X-Ray images for the automatic detection of COVID-19. A thoughtful evaluation approach
Nov 29, 2020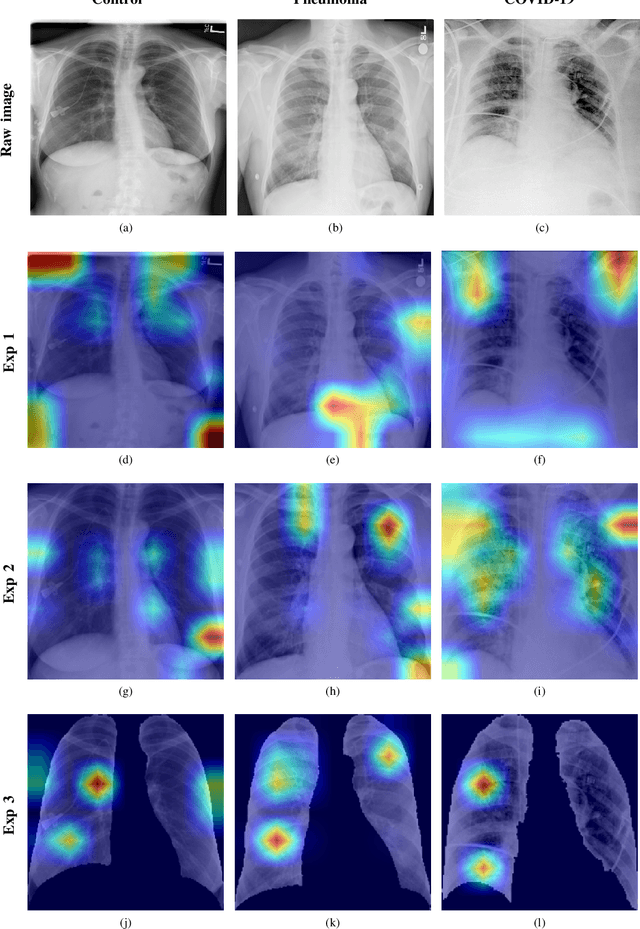
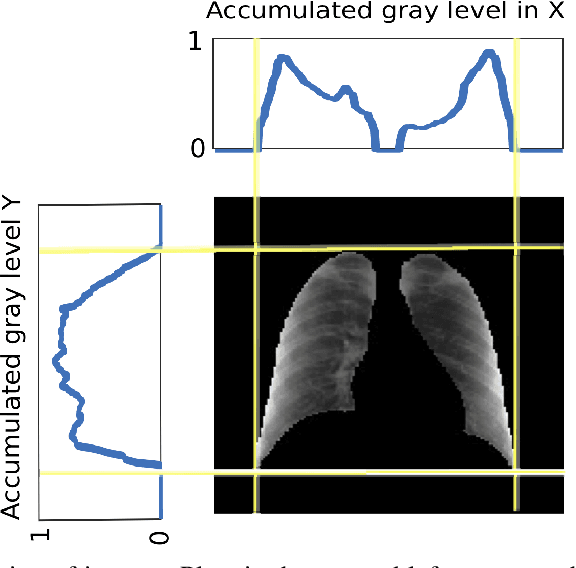
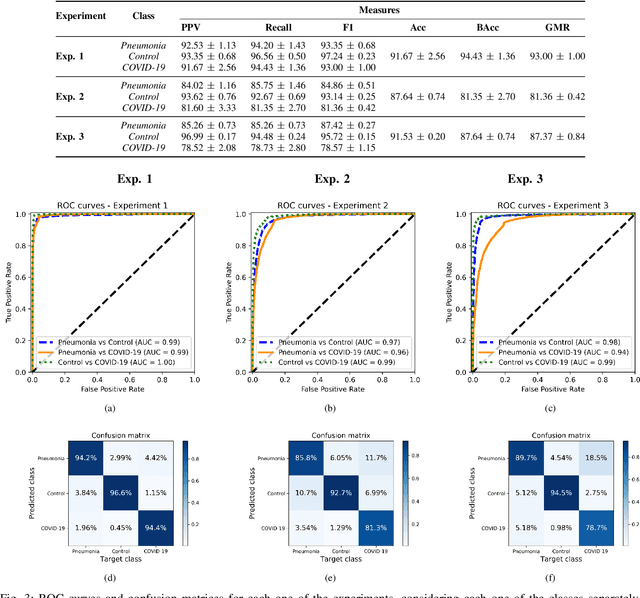
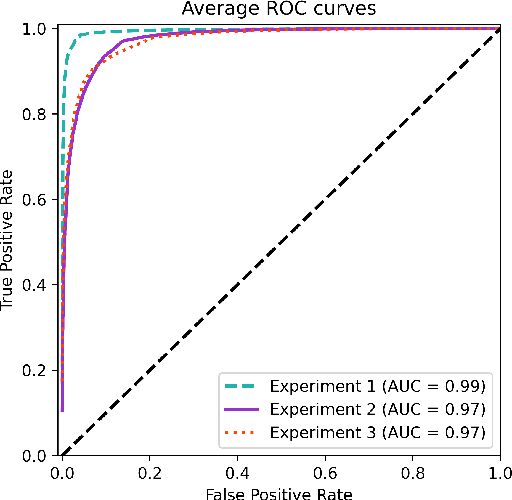
Current standard protocols used in the clinic for diagnosing COVID-19 include molecular or antigen tests, generally complemented by a plain chest X-Ray. The combined analysis aims to reduce the significant number of false negatives of these tests, but also to provide complementary evidence about the presence and severity of the disease. However, the procedure is not free of errors, and the interpretation of the chest X-Ray is only restricted to radiologists due to its complexity. With the long term goal to provide new evidence for the diagnosis, this paper presents an evaluation of different methods based on a deep neural network. These are the first steps to develop an automatic COVID-19 diagnosis tool using chest X-Ray images, that would additionally differentiate between controls, pneumonia or COVID-19 groups. The paper describes the process followed to train a Convolutional Neural Network with a dataset of more than 79,500 X-Ray images compiled from different sources, including more than 8,500 COVID-19 examples. For the sake of evaluation and comparison of the models developed, three different experiments were carried out following three preprocessing schemes. The aim is to evaluate how preprocessing the data affects the results and improves its explainability. Likewise, a critical analysis is carried out about different variability issues that might compromise the system and the effects on the performance. With the employed methodology, a 91.5% classification accuracy is obtained, with a 87.4% average recall for the worst but most explainable experiment, which requires a previous automatic segmentation of the lungs region.