 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Vibration Forecasting for Advancing Rail Safety and Maintenance 4.0
Jan 20, 2025
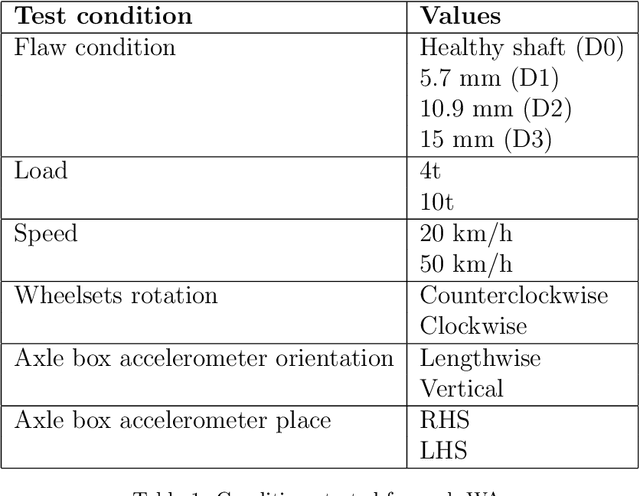
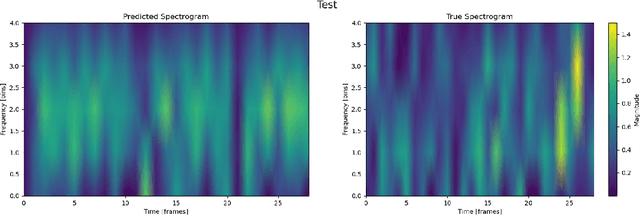
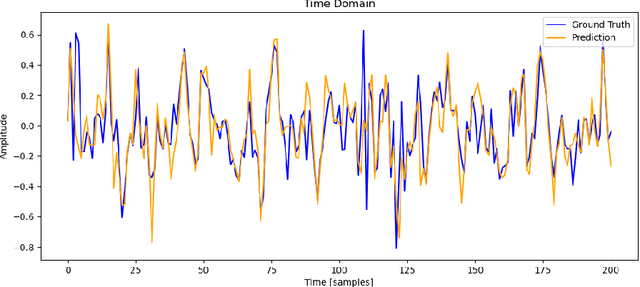
Maintaining railway axles is critical to preventing severe accidents and financial losses. The railway industry is increasingly interested in advanced condition monitoring techniques to enhance safety and efficiency, moving beyond traditional periodic inspections toward Maintenance 4.0. This study introduces a robust Deep Autoregressive solution that integrates seamlessly with existing systems to avert mechanical failures. Our approach simulates and predicts vibration signals under various conditions and fault scenarios, improving dataset robustness for more effective detection systems. These systems can alert maintenance needs, preventing accidents preemptively. We use experimental vibration signals from accelerometers on train axles. Our primary contributions include a transformer model, ShaftFormer, designed for processing time series data, and an alternative model incorporating spectral methods and enhanced observation models. Simulating vibration signals under diverse conditions mitigates the high cost of obtaining experimental signals for all scenarios. Given the non-stationary nature of railway vibration signals, influenced by speed and load changes, our models address these complexities, offering a powerful tool for predictive maintenance in the rail industry.
NeuroVoz: a Castillian Spanish corpus of parkinsonian speech
Mar 06, 2024The advancement of Parkinson's Disease (PD) diagnosis through speech analysis is hindered by a notable lack of publicly available, diverse language datasets, limiting the reproducibility and further exploration of existing research. In response to this gap, we introduce a comprehensive corpus from 108 native Castilian Spanish speakers, comprising 55 healthy controls and 53 individuals diagnosed with PD, all of whom were under pharmacological treatment and recorded in their medication-optimized state. This unique dataset features a wide array of speech tasks, including sustained phonation of the five Spanish vowels, diadochokinetic tests, 16 listen-and-repeat utterances, and free monologues. The dataset emphasizes accuracy and reliability through specialist manual transcriptions of the listen-and-repeat tasks and utilizes Whisper for automated monologue transcriptions, making it the most complete public corpus of Parkinsonian speech, and the first in Castillian Spanish. NeuroVoz is composed by 2,903 audio recordings averaging $26.88 \pm 3.35$ recordings per participant, offering a substantial resource for the scientific exploration of PD's impact on speech. This dataset has already underpinned several studies, achieving a benchmark accuracy of 89% in PD speech pattern identification, indicating marked speech alterations attributable to PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains an open area for future research. This contribution not only fills a critical void in PD speech analysis resources but also sets a new standard for the global research community in leveraging speech as a diagnostic tool for neurodegenerative diseases.
Detecting train driveshaft damages using accelerometer signals and Differential Convolutional Neural Networks
Nov 15, 2022Railway axle maintenance is critical to avoid catastrophic failures. Nowadays, condition monitoring techniques are becoming more prominent in the industry to prevent enormous costs and damage to human lives. This paper proposes the development of a railway axle condition monitoring system based on advanced 2D-Convolutional Neural Network (CNN) architectures applied to time-frequency representations of vibration signals. For this purpose, several preprocessing steps and different types of Deep Learning (DL) and Machine Learning (ML) architectures are discussed to design an accurate classification system. The resultant system converts the railway axle vibration signals into time-frequency domain representations, i.e., spectrograms, and, thus, trains a two-dimensional CNN to classify them depending on their cracks. The results showed that the proposed approach outperforms several alternative methods tested. The CNN architecture has been tested in 3 different wheelset assemblies, achieving AUC scores of 0.93, 0.86, and 0.75 outperforming any other architecture and showing a high level of reliability when classifying 4 different levels of defects.
Multi-view hierarchical Variational AutoEncoders with Factor Analysis latent space
Jul 19, 2022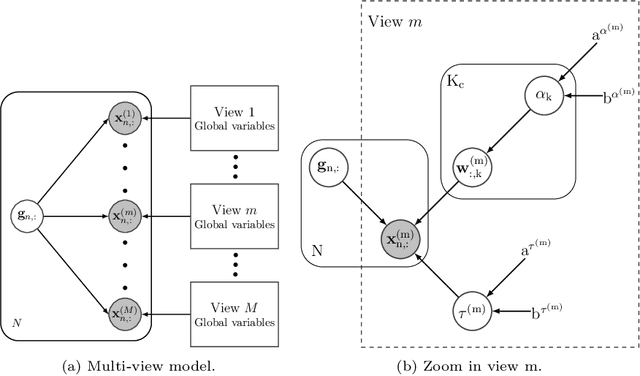


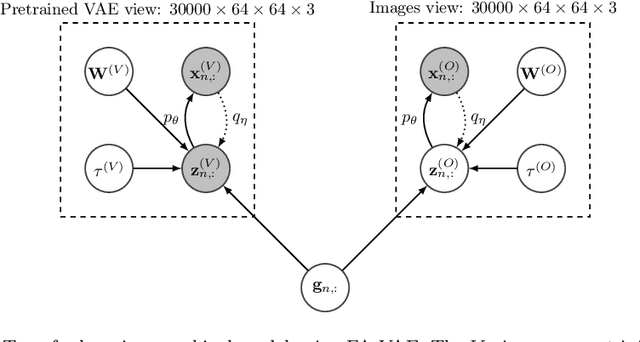
Real-world databases are complex, they usually present redundancy and shared correlations between heterogeneous and multiple representations of the same data. Thus, exploiting and disentangling shared information between views is critical. For this purpose, recent studies often fuse all views into a shared nonlinear complex latent space but they lose the interpretability. To overcome this limitation, here we propose a novel method to combine multiple Variational AutoEncoders (VAE) architectures with a Factor Analysis latent space (FA-VAE). Concretely, we use a VAE to learn a private representation of each heterogeneous view in a continuous latent space. Then, we model the shared latent space by projecting every private variable to a low-dimensional latent space using a linear projection matrix. Thus, we create an interpretable hierarchical dependency between private and shared information. This way, the novel model is able to simultaneously: (i) learn from multiple heterogeneous views, (ii) obtain an interpretable hierarchical shared space, and, (iii) perform transfer learning between generative models.
Bayesian Sparse Factor Analysis with Kernelized Observations
Jun 10, 2020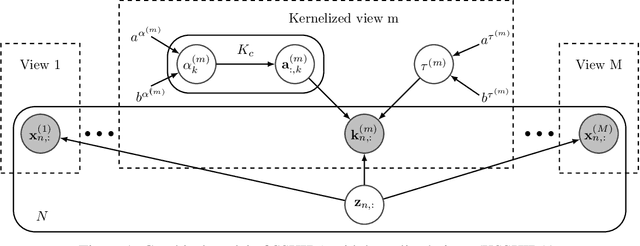
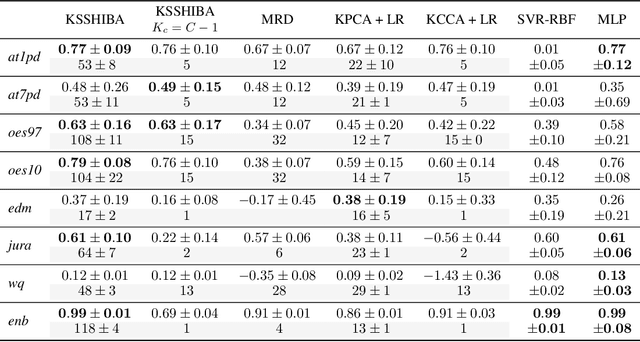
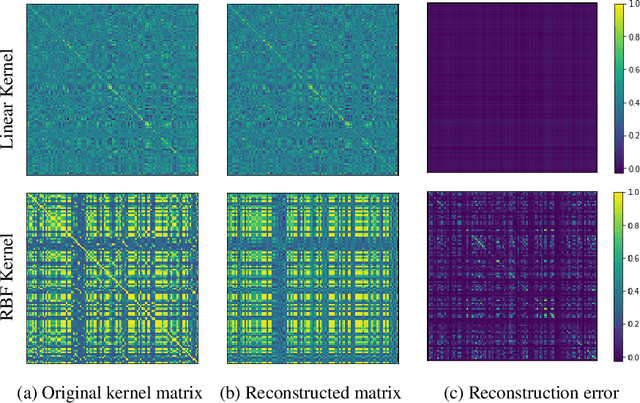
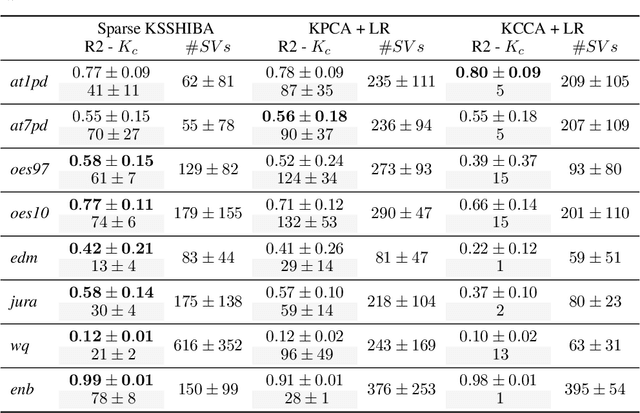
Latent variable models for multi-view learning attempt to find low-dimensional projections that fairly capture the correlations among multiple views that characterise each datum. High-dimensional views in medium-sized datasets and non-linear problems are traditionally handled by kernel methods, inducing a (non)-linear function between the latent projection and the data itself. However, they usually come with scalability issues and exposition to overfitting. To overcome these limitations, instead of imposing a kernel function, here we propose an alternative method. In particular, we combine probabilistic factor analysis with what we refer to as kernelized observations, in which the model focuses on reconstructing not the data itself, but its correlation with other data points measured by a kernel function. This model can combine several types of views (kernelized or not), can handle heterogeneous data and work in semi-supervised settings. Additionally, by including adequate priors, it can provide compact solutions for the kernelized observations (based in a automatic selection of bayesian support vectors) and can include feature selection capabilities. Using several public databases, we demonstrate the potential of our approach (and its extensions) w.r.t. common multi-view learning models such as kernel canonical correlation analysis or manifold relevance determination gaussian processes latent variable models.