 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Instance Selection Algorithm for Big Data in High imbalanced datasets based on LSH
Oct 09, 2022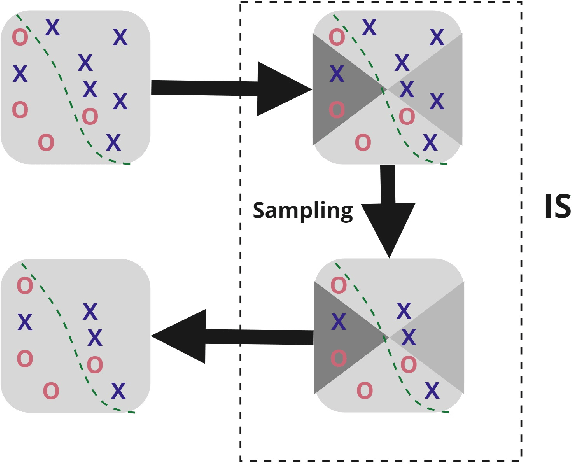
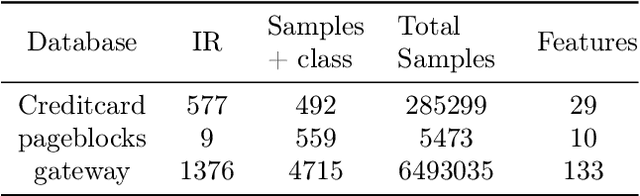
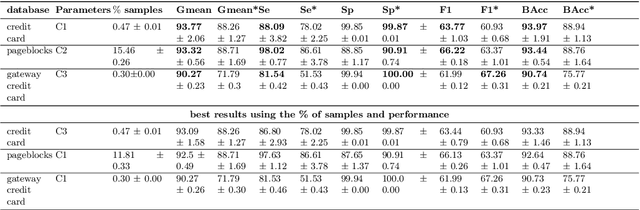
Training of Machine Learning (ML) models in real contexts often deals with big data sets and high-class imbalance samples where the class of interest is unrepresented (minority class). Practical solutions using classical ML models address the problem of large data sets using parallel/distributed implementations of training algorithms, approximate model-based solutions, or applying instance selection (IS) algorithms to eliminate redundant information. However, the combined problem of big and high imbalanced datasets has been less addressed. This work proposes three new methods for IS to be able to deal with large and imbalanced data sets. The proposed methods use Locality Sensitive Hashing (LSH) as a base clustering technique, and then three different sampling methods are applied on top of the clusters (or buckets) generated by LSH. The algorithms were developed in the Apache Spark framework, guaranteeing their scalability. The experiments carried out in three different datasets suggest that the proposed IS methods can improve the performance of a base ML model between 5% and 19% in terms of the geometric mean.