 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake News Detection in Spanish Using Deep Learning Techniques
Oct 13, 2021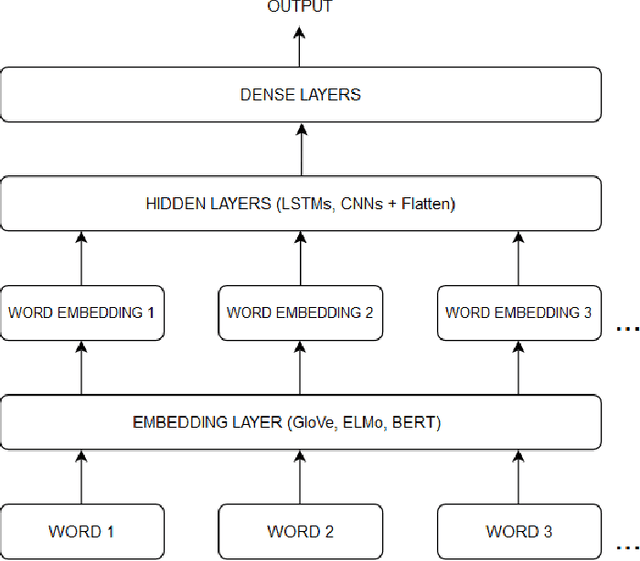

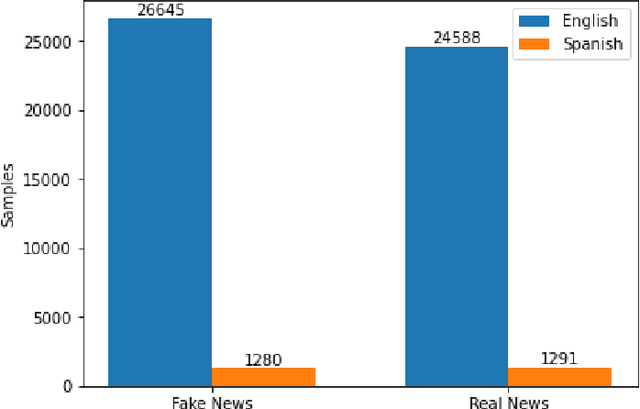
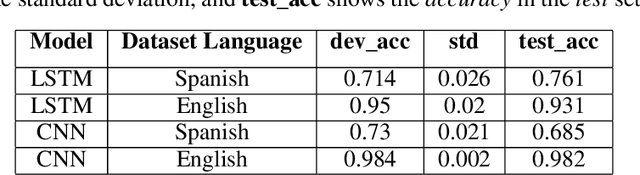
This paper addresses the problem of fake news detection in Spanish using Machine Learning techniques. It is fundamentally the same problem tackled for the English language; however, there is not a significant amount of publicly available and adequately labeled fake news in Spanish to effectively train a Machine Learning model, similarly to those proposed for the English language. Therefore, this work explores different training strategies and architectures to establish a baseline for further research in this area. Four datasets were used, two in English and two in Spanish, and four experimental schemes were tested, including a baseline with classical Machine Learning models, trained and validated using a small dataset in Spanish. The remaining schemes include state-of-the-art Deep Learning models trained (or fine-tuned) and validated in English, trained and validated in Spanish, and fitted in English and validated with automatic translated Spanish sentences. The Deep Learning architectures were built on top of different pre-trained Word Embedding representations, including GloVe, ELMo, BERT, and BETO (a BERT version trained on a large corpus in Spanish). According to the results, the best strategy was a combination of a pre-trained BETO model and a Recurrent Neural Network based on LSTM layers, yielding an accuracy of up to 80%; nonetheless, a baseline model using a Random Forest estimator obtained similar outcomes. Additionally, the translation strategy did not yield acceptable results because of the propagation error; there was also observed a significant difference in models performance when trained in English or Spanish, mainly attributable to the number of samples available for each language.