 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient-Centered Summarization Framework for AI Clinical Summarization: A Mixed-Methods Design
Oct 31, 2025Large Language Models (LLMs) are increasingly demonstrating the potential to reach human-level performance in generating clinical summaries from patient-clinician conversations. However, these summaries often focus on patients' biology rather than their preferences, values, wishes, and concerns. To achieve patient-centered care, we propose a new standard for Artificial Intelligence (AI) clinical summarization tasks: Patient-Centered Summaries (PCS). Our objective was to develop a framework to generate PCS that capture patient values and ensure clinical utility and to assess whether current open-source LLMs can achieve human-level performance in this task. We used a mixed-methods process. Two Patient and Public Involvement groups (10 patients and 8 clinicians) in the United Kingdom participated in semi-structured interviews exploring what personal and contextual information should be included in clinical summaries and how it should be structured for clinical use. Findings informed annotation guidelines used by eight clinicians to create gold-standard PCS from 88 atrial fibrillation consultations. Sixteen consultations were used to refine a prompt aligned with the guidelines. Five open-source LLMs (Llama-3.2-3B, Llama-3.1-8B, Mistral-8B, Gemma-3-4B, and Qwen3-8B) generated summaries for 72 consultations using zero-shot and few-shot prompting, evaluated with ROUGE-L, BERTScore, and qualitative metrics. Patients emphasized lifestyle routines, social support, recent stressors, and care values. Clinicians sought concise functional, psychosocial, and emotional context. The best zero-shot performance was achieved by Mistral-8B (ROUGE-L 0.189) and Llama-3.1-8B (BERTScore 0.673); the best few-shot by Llama-3.1-8B (ROUGE-L 0.206, BERTScore 0.683). Completeness and fluency were similar between experts and models, while correctness and patient-centeredness favored human PCS.
Artificial Intelligence-Enabled Analysis of Radiology Reports: Epidemiology and Consequences of Incidental Thyroid Findings
Oct 30, 2025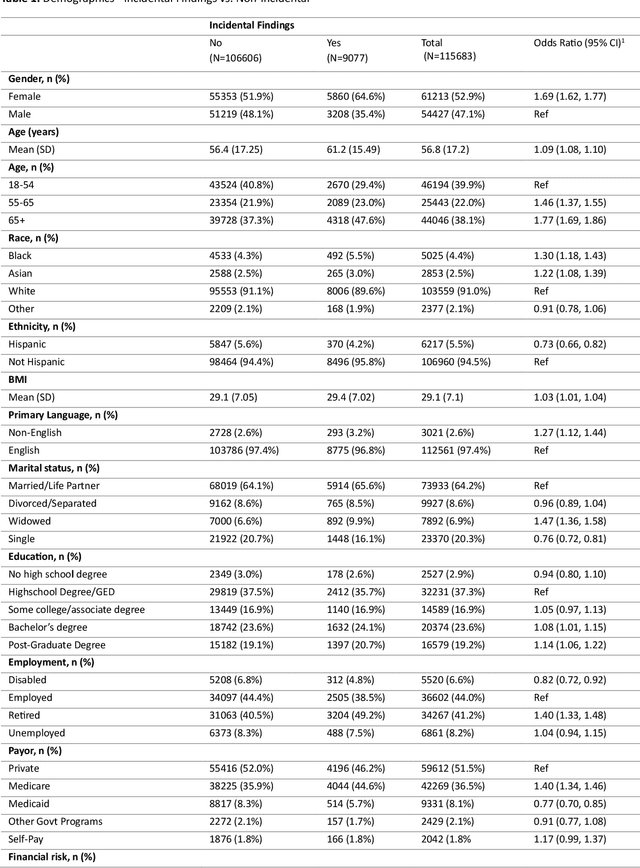
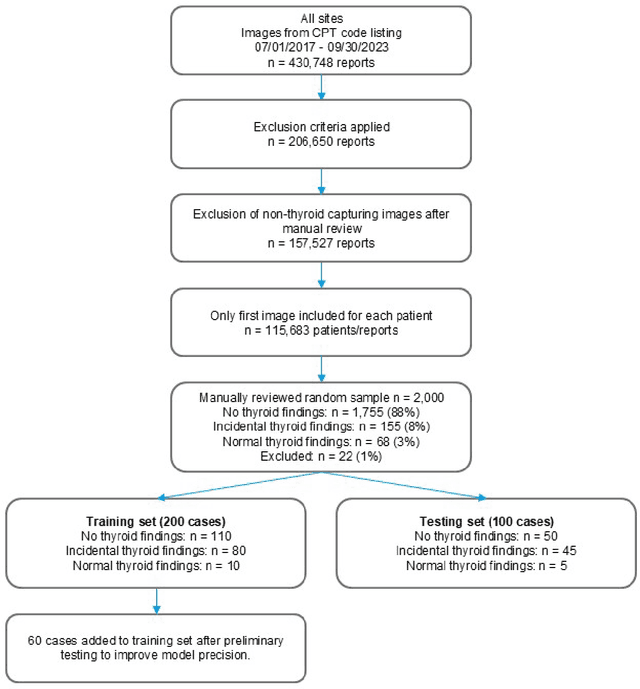
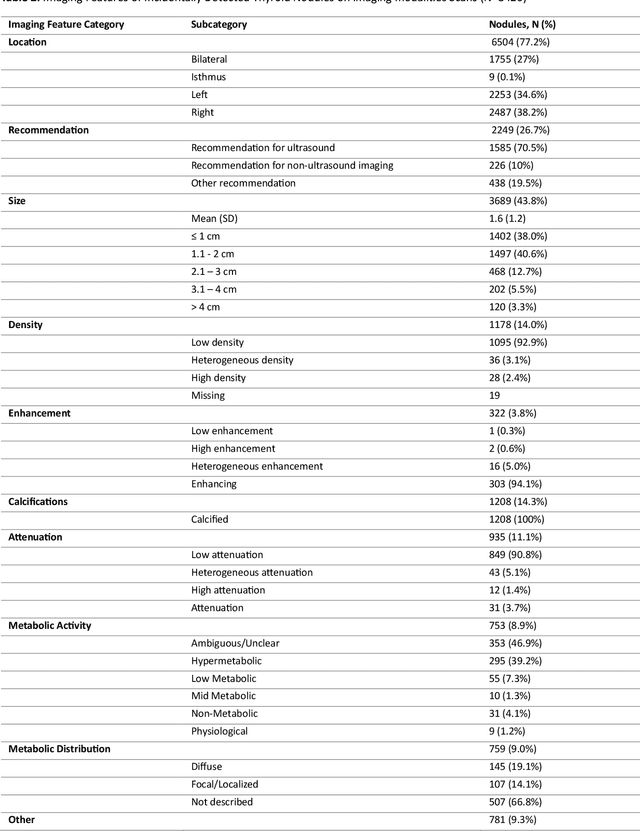
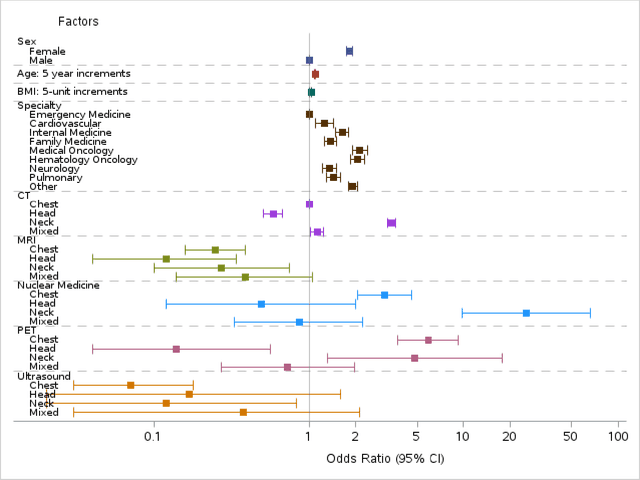
Importance Incidental thyroid findings (ITFs) are increasingly detected on imaging performed for non-thyroid indications. Their prevalence, features, and clinical consequences remain undefined. Objective To develop, validate, and deploy a natural language processing (NLP) pipeline to identify ITFs in radiology reports and assess their prevalence, features, and clinical outcomes. Design, Setting, and Participants Retrospective cohort of adults without prior thyroid disease undergoing thyroid-capturing imaging at Mayo Clinic sites from July 1, 2017, to September 30, 2023. A transformer-based NLP pipeline identified ITFs and extracted nodule characteristics from image reports from multiple modalities and body regions. Main Outcomes and Measures Prevalence of ITFs, downstream thyroid ultrasound, biopsy, thyroidectomy, and thyroid cancer diagnosis. Logistic regression identified demographic and imaging-related factors. Results Among 115,683 patients (mean age, 56.8 [SD 17.2] years; 52.9% women), 9,077 (7.8%) had an ITF, of which 92.9% were nodules. ITFs were more likely in women, older adults, those with higher BMI, and when imaging was ordered by oncology or internal medicine. Compared with chest CT, ITFs were more likely via neck CT, PET, and nuclear medicine scans. Nodule characteristics were poorly documented, with size reported in 44% and other features in fewer than 15% (e.g. calcifications). Compared with patients without ITFs, those with ITFs had higher odds of thyroid nodule diagnosis, biopsy, thyroidectomy and thyroid cancer diagnosis. Most cancers were papillary, and larger when detected after ITFs vs no ITF. Conclusions ITFs were common and strongly associated with cascades leading to the detection of small, low-risk cancers. These findings underscore the role of ITFs in thyroid cancer overdiagnosis and the need for standardized reporting and more selective follow-up.
Use of natural language processing to extract and classify papillary thyroid cancer features from surgical pathology reports
May 22, 2024



Background We aim to use Natural Language Processing (NLP) to automate the extraction and classification of thyroid cancer risk factors from pathology reports. Methods We analyzed 1,410 surgical pathology reports from adult papillary thyroid cancer patients at Mayo Clinic, Rochester, MN, from 2010 to 2019. Structured and non-structured reports were used to create a consensus-based ground truth dictionary and categorized them into modified recurrence risk levels. Non-structured reports were narrative, while structured reports followed standardized formats. We then developed ThyroPath, a rule-based NLP pipeline, to extract and classify thyroid cancer features into risk categories. Training involved 225 reports (150 structured, 75 unstructured), with testing on 170 reports (120 structured, 50 unstructured) for evaluation. The pipeline's performance was assessed using both strict and lenient criteria for accuracy, precision, recall, and F1-score. Results In extraction tasks, ThyroPath achieved overall strict F-1 scores of 93% for structured reports and 90 for unstructured reports, covering 18 thyroid cancer pathology features. In classification tasks, ThyroPath-extracted information demonstrated an overall accuracy of 93% in categorizing reports based on their corresponding guideline-based risk of recurrence: 76.9% for high-risk, 86.8% for intermediate risk, and 100% for both low and very low-risk cases. However, ThyroPath achieved 100% accuracy across all thyroid cancer risk categories with human-extracted pathology information. Conclusions ThyroPath shows promise in automating the extraction and risk recurrence classification of thyroid pathology reports at large scale. It offers a solution to laborious manual reviews and advancing virtual registries. However, it requires further validation before implementation.
Extracting Thyroid Nodules Characteristics from Ultrasound Reports Using Transformer-based Natural Language Processing Methods
Mar 31, 2023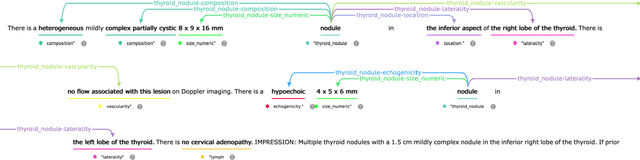

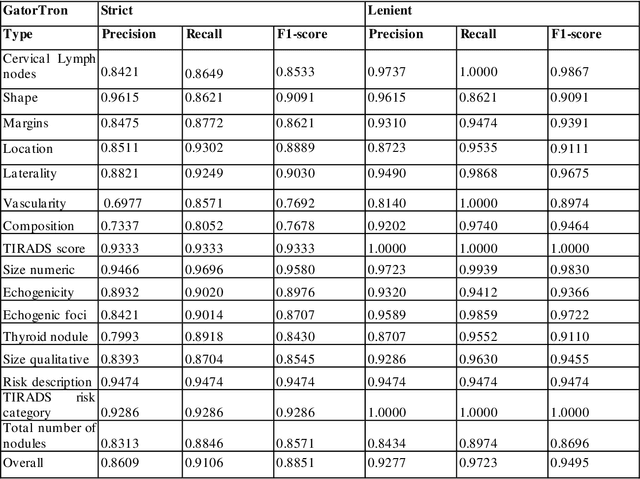
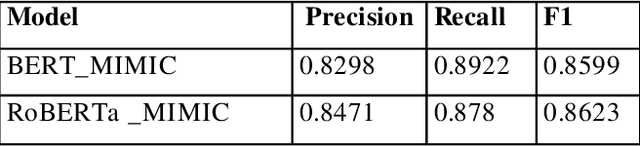
The ultrasound characteristics of thyroid nodules guide the evaluation of thyroid cancer in patients with thyroid nodules. However, the characteristics of thyroid nodules are often documented in clinical narratives such as ultrasound reports. Previous studies have examined natural language processing (NLP) methods in extracting a limited number of characteristics (<9) using rule-based NLP systems. In this study, a multidisciplinary team of NLP experts and thyroid specialists, identified thyroid nodule characteristics that are important for clinical care, composed annotation guidelines, developed a corpus, and compared 5 state-of-the-art transformer-based NLP methods, including BERT, RoBERTa, LongFormer, DeBERTa, and GatorTron, for extraction of thyroid nodule characteristics from ultrasound reports. Our GatorTron model, a transformer-based large language model trained using over 90 billion words of text, achieved the best strict and lenient F1-score of 0.8851 and 0.9495 for the extraction of a total number of 16 thyroid nodule characteristics, and 0.9321 for linking characteristics to nodules, outperforming other clinical transformer models. To the best of our knowledge, this is the first study to systematically categorize and apply transformer-based NLP models to extract a large number of clinical relevant thyroid nodule characteristics from ultrasound reports. This study lays ground for assessing the documentation quality of thyroid ultrasound reports and examining outcomes of patients with thyroid nodules using electronic health records.