 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning assessment of breast terminal duct lobular unit involution: towards automated prediction of breast cancer risk
Oct 31, 2019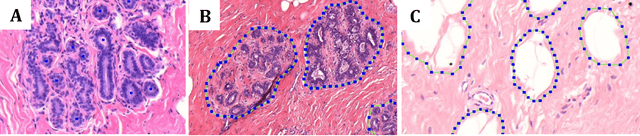
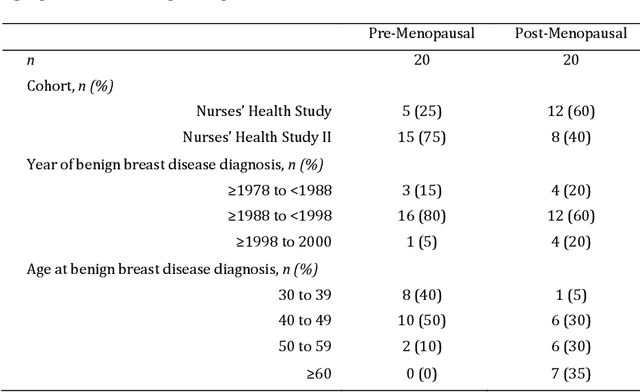
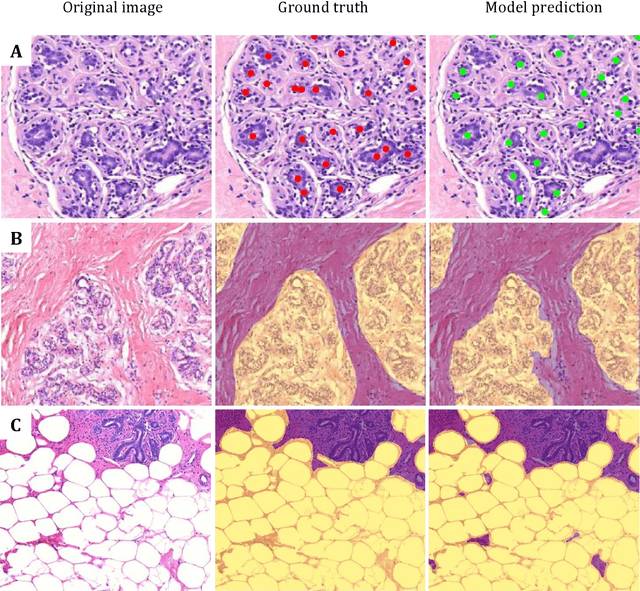

Terminal ductal lobular unit (TDLU) involution is the regression of milk-producing structures in the breast. Women with less TDLU involution are more likely to develop breast cancer. A major bottleneck in studying TDLU involution in large cohort studies is the need for labor-intensive manual assessment of TDLUs. We developed a computational pathology solution to automatically capture TDLU involution measures. Whole slide images (WSIs) of benign breast biopsies were obtained from the Nurses' Health Study (NHS). A first set of 92 WSIs was annotated for TDLUs, acini and adipose tissue to train deep convolutional neural network (CNN) models for detection of acini, and segmentation of TDLUs and adipose tissue. These networks were integrated into a single computational method to capture TDLU involution measures including number of TDLUs per tissue area, median TDLU span and median number of acini per TDLU. We validated our method on 40 additional WSIs by comparing with manually acquired measures. Our CNN models detected acini with an F1 score of 0.73$\pm$0.09, and segmented TDLUs and adipose tissue with Dice scores of 0.86$\pm$0.11 and 0.86$\pm$0.04, respectively. The inter-observer ICC scores for manual assessments on 40 WSIs of number of TDLUs per tissue area, median TDLU span, and median acini count per TDLU were 0.71, 95% CI [0.51, 0.83], 0.81, 95% CI [0.67, 0.90], and 0.73, 95% CI [0.54, 0.85], respectively. Intra-observer reliability was evaluated on 10/40 WSIs with ICC scores of >0.8. Inter-observer ICC scores between automated results and the mean of the two observers were: 0.80, 95% CI [0.63, 0.90] for number of TDLUs per tissue area, 0.57, 95% CI [0.19, 0.77] for median TDLU span, and 0.80, 95% CI [0.62, 0.89] for median acini count per TDLU. TDLU involution measures evaluated by manual and automated assessment were inversely associated with age and menopausal status.
Roto-Translation Covariant Convolutional Networks for Medical Image Analysis
Jun 11, 2018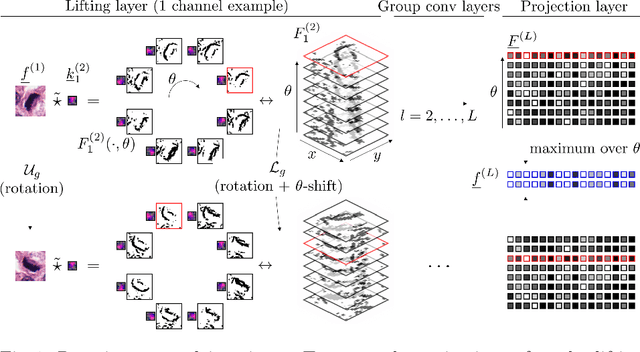
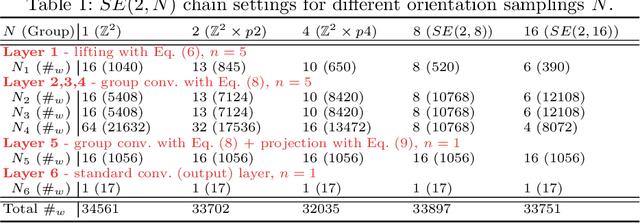
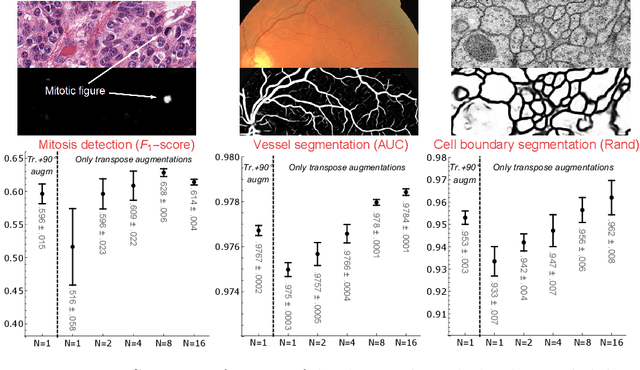
We propose a framework for rotation and translation covariant deep learning using $SE(2)$ group convolutions. The group product of the special Euclidean motion group $SE(2)$ describes how a concatenation of two roto-translations results in a net roto-translation. We encode this geometric structure into convolutional neural networks (CNNs) via $SE(2)$ group convolutional layers, which fit into the standard 2D CNN framework, and which allow to generically deal with rotated input samples without the need for data augmentation. We introduce three layers: a lifting layer which lifts a 2D (vector valued) image to an $SE(2)$-image, i.e., 3D (vector valued) data whose domain is $SE(2)$; a group convolution layer from and to an $SE(2)$-image; and a projection layer from an $SE(2)$-image to a 2D image. The lifting and group convolution layers are $SE(2)$ covariant (the output roto-translates with the input). The final projection layer, a maximum intensity projection over rotations, makes the full CNN rotation invariant. We show with three different problems in histopathology, retinal imaging, and electron microscopy that with the proposed group CNNs, state-of-the-art performance can be achieved, without the need for data augmentation by rotation and with increased performance compared to standard CNNs that do rely on augmentation.