 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer for Cross-Domain Reinforcement Learning: A Systematic Review
Apr 26, 2024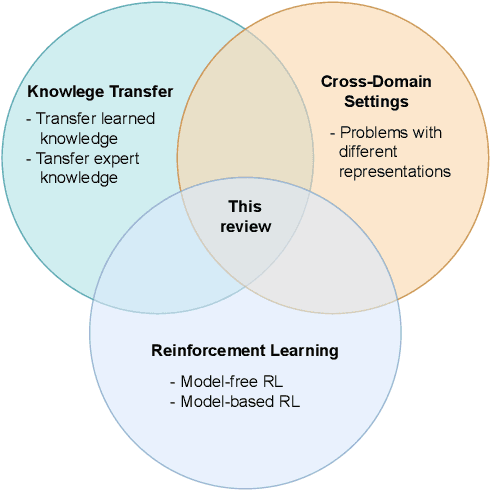
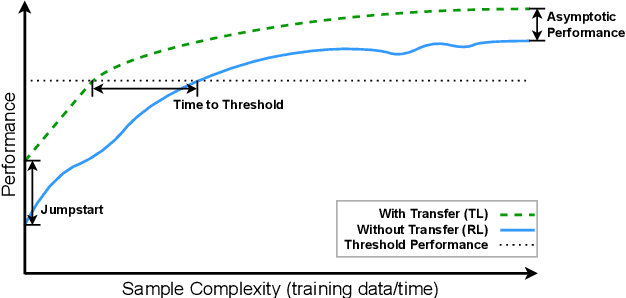

Reinforcement Learning (RL) provides a framework in which agents can be trained, via trial and error, to solve complex decision-making problems. Learning with little supervision causes RL methods to require large amounts of data, which renders them too expensive for many applications (e.g. robotics). By reusing knowledge from a different task, knowledge transfer methods present an alternative to reduce the training time in RL. Given how severe data scarcity can be, there has been a growing interest for methods capable of transferring knowledge across different domains (i.e. problems with different representation) due to the flexibility they offer. This review presents a unifying analysis of methods focused on transferring knowledge across different domains. Through a taxonomy based on a transfer-approach categorization, and a characterization of works based on their data-assumption requirements, the objectives of this article are to 1) provide a comprehensive and systematic revision of knowledge transfer methods for the cross-domain RL setting, 2) categorize and characterize these methods to provide an analysis based on relevant features such as their transfer approach and data requirements, and 3) discuss the main challenges regarding cross-domain knowledge transfer, as well as ideas of future directions worth exploring to address these problems.
Similarity-based Knowledge Transfer for Cross-Domain Reinforcement Learning
Dec 05, 2023Transferring knowledge in cross-domain reinforcement learning is a challenging setting in which learning is accelerated by reusing knowledge from a task with different observation and/or action space. However, it is often necessary to carefully select the source of knowledge for the receiving end to benefit from the transfer process. In this article, we study how to measure the similarity between cross-domain reinforcement learning tasks to select a source of knowledge that will improve the performance of the learning agent. We developed a semi-supervised alignment loss to match different spaces with a set of encoder-decoders, and use them to measure similarity and transfer policies across tasks. In comparison to prior works, our method does not require data to be aligned, paired or collected by expert policies. Experimental results, on a set of varied Mujoco control tasks, show the robustness of our method in effectively selecting and transferring knowledge, without the supervision of a tailored set of source tasks.
Knowledge-Based Hierarchical POMDPs for Task Planning
Apr 09, 2021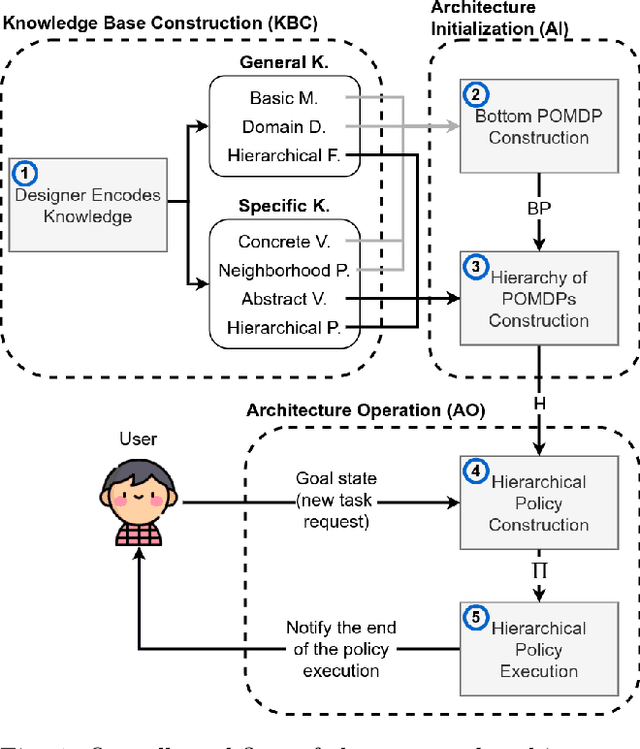

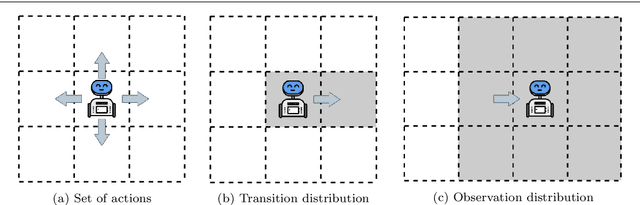
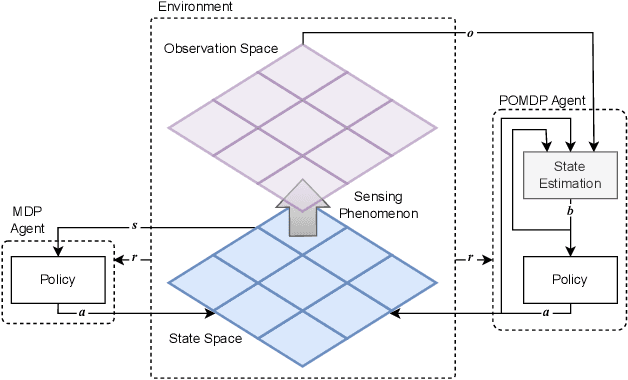
The main goal in task planning is to build a sequence of actions that takes an agent from an initial state to a goal state. In robotics, this is particularly difficult because actions usually have several possible results, and sensors are prone to produce measurements with error. Partially observable Markov decision processes (POMDPs) are commonly employed, thanks to their capacity to model the uncertainty of actions that modify and monitor the state of a system. However, since solving a POMDP is computationally expensive, their usage becomes prohibitive for most robotic applications. In this paper, we propose a task planning architecture for service robotics. In the context of service robot design, we present a scheme to encode knowledge about the robot and its environment, that promotes the modularity and reuse of information. Also, we introduce a new recursive definition of a POMDP that enables our architecture to autonomously build a hierarchy of POMDPs, so that it can be used to generate and execute plans that solve the task at hand. Experimental results show that, in comparison to baseline methods, by following a recursive hierarchical approach the architecture is able to significantly reduce the planning time, while maintaining (or even improving) the robustness under several scenarios that vary in uncertainty and size.