 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimation of $\text{MTP}_2$ Graphical Models
Oct 27, 2022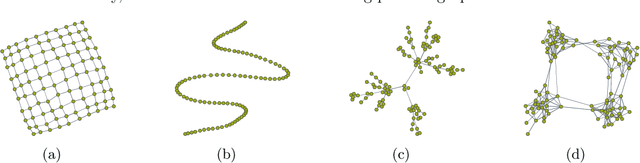
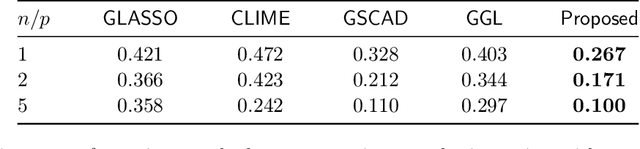
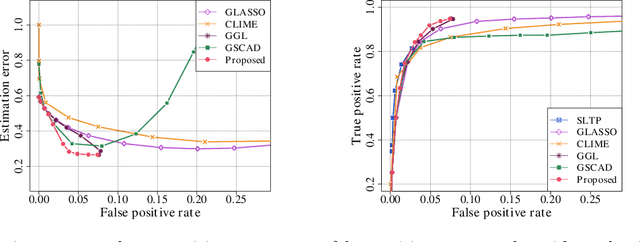

We consider the problem of estimating (diagonally dominant) M-matrices as precision matrices in Gaussian graphical models. Such models have received increasing attention in recent years, and have shown interesting properties, e.g., the maximum likelihood estimator exists with as little as two observations regardless of the underlying dimension. In this paper, we propose an adaptive estimation method, which consists of multiple stages: In the first stage, we solve an $\ell_1$-regularized maximum likelihood estimation problem, which leads to an initial estimate; in the subsequent stages, we iteratively refine the initial estimate by solving a sequence of weighted $\ell_1$-regularized problems. We further establish the theoretical guarantees on the estimation error, which consists of optimization error and statistical error. The optimization error decays to zero at a linear rate, indicating that the estimate is refined iteratively in subsequent stages, and the statistical error characterizes the statistical rate. The proposed method outperforms state-of-the-art methods in estimating precision matrices and identifying graph edges, as evidenced by synthetic and financial time-series data sets.
Fast Projected Newton-like Method for Precision Matrix Estimation with Nonnegative Partial Correlations
Dec 12, 2021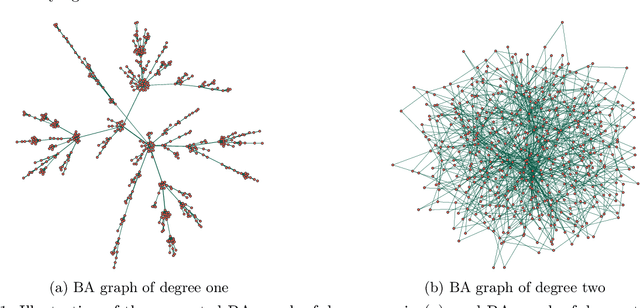
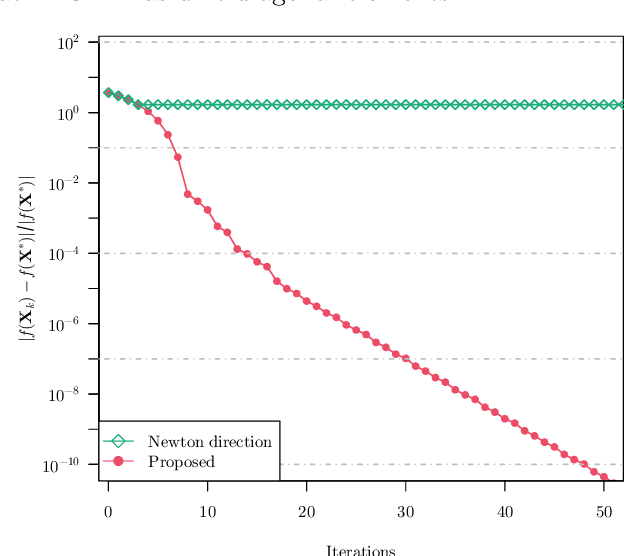
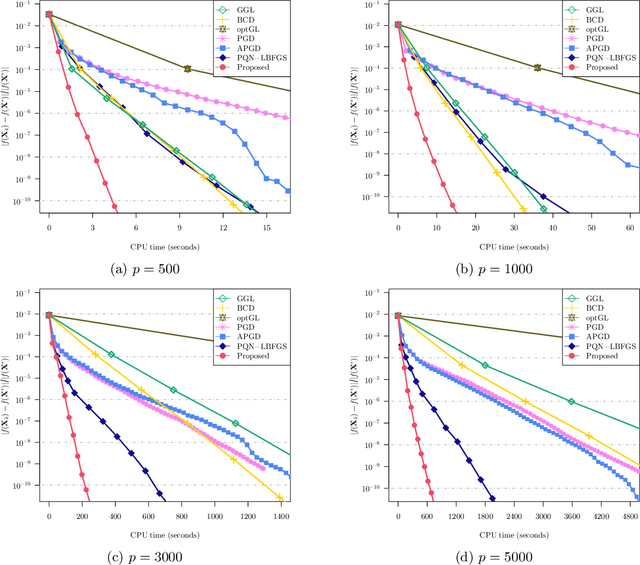
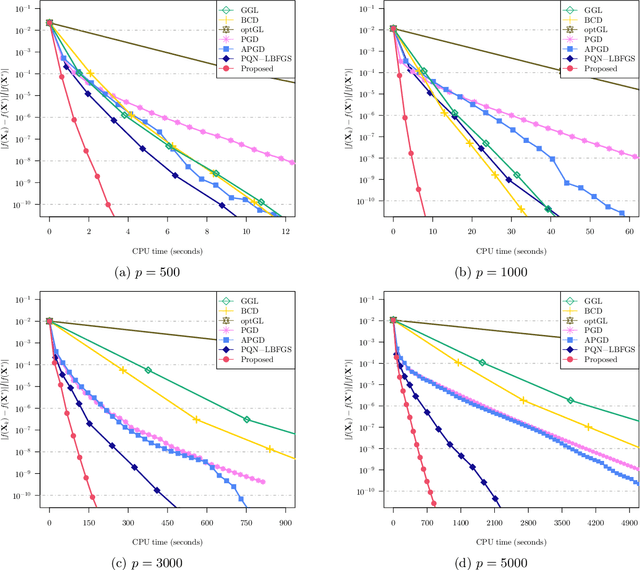
We study the problem of estimating precision matrices in multivariate Gaussian distributions where all partial correlations are nonnegative, also known as multivariate totally positive of order two ($\mathrm{MTP}_2$). Such models have received significant attention in recent years, primarily due to interesting properties, e.g., the maximum likelihood estimator exists with as few as two observations regardless of the underlying dimension. We formulate this problem as a weighted $\ell_1$-norm regularized Gaussian maximum likelihood estimation under $\mathrm{MTP}_2$ constraints. On this direction, we propose a novel projected Newton-like algorithm that incorporates a well-designed approximate Newton direction, which results in our algorithm having the same orders of computation and memory costs as those of first-order methods. We prove that the proposed projected Newton-like algorithm converges to the minimizer of the problem. We further show, both theoretically and experimentally, that the minimizer of our formulation using the weighted $\ell_1$-norm is able to recover the support of the underlying precision matrix correctly without requiring the incoherence condition present in $\ell_1$-norm based methods. Experiments involving synthetic and real-world data demonstrate that our proposed algorithm is significantly more efficient, from a computational time perspective, than the state-of-the-art methods. Finally, we apply our method in financial time-series data, which are well-known for displaying positive dependencies, where we observe a significant performance in terms of modularity value on the learned financial networks.
Does the $\ell_1$-norm Learn a Sparse Graph under Laplacian Constrained Graphical Models?
Jun 26, 2020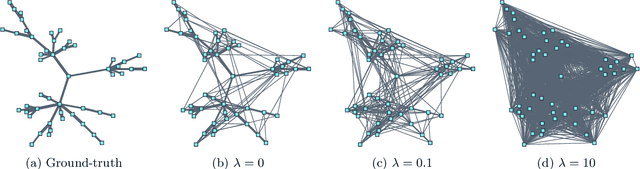
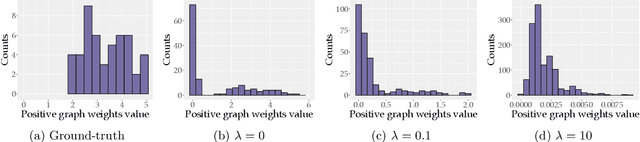
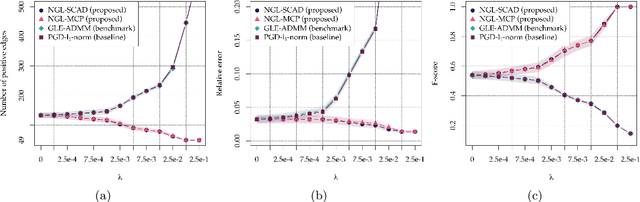
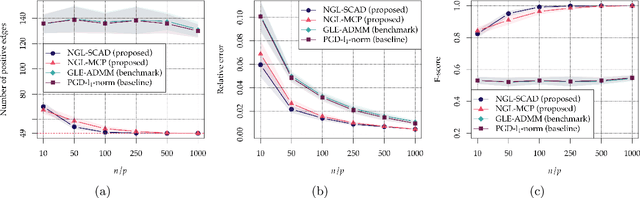
We consider the problem of learning a sparse graph under Laplacian constrained Gaussian graphical models. This problem can be formulated as a penalized maximum likelihood estimation of the precision matrix under Laplacian structural constraints. Like in the classical graphical lasso problem, recent works made use of the $\ell_1$-norm regularization with the goal of promoting sparsity in Laplacian structural precision matrix estimation. However, we find that the widely used $\ell_1$-norm is not effective in imposing a sparse solution in this problem. Through empirical evidence, we observe that the number of nonzero graph weights grows with the increase of the regularization parameter. From a theoretical perspective, we prove that a large regularization parameter will surprisingly lead to a fully connected graph. To address this issue, we propose a nonconvex estimation method by solving a sequence of weighted $\ell_1$-norm penalized sub-problems and prove that the statistical error of the proposed estimator matches the minimax lower bound. To solve each sub-problem, we develop a projected gradient descent algorithm that enjoys a linear convergence rate. Numerical experiments involving synthetic and real-world data sets from the recent COVID-19 pandemic and financial stock markets demonstrate the effectiveness of the proposed method. An open source $\mathsf{R}$ package containing the code for all the experiments is available at https://github.com/mirca/sparseGraph.
A Unified Framework for Structured Graph Learning via Spectral Constraints
Apr 22, 2019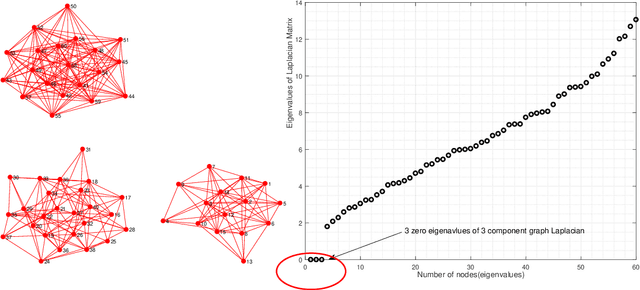
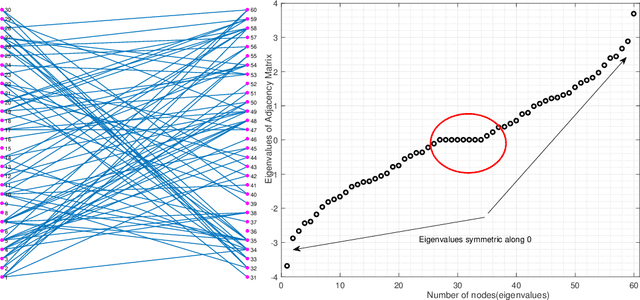
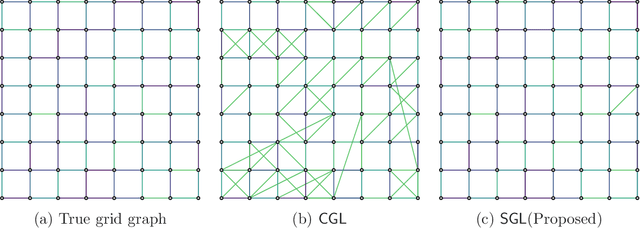
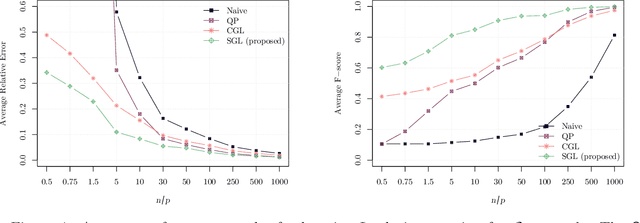
Graph learning from data represents a canonical problem that has received substantial attention in the literature. However, insufficient work has been done in incorporating prior structural knowledge onto the learning of underlying graphical models from data. Learning a graph with a specific structure is essential for interpretability and identification of the relationships among data. Useful structured graphs include the multi-component graph, bipartite graph, connected graph, sparse graph, and regular graph. In general, structured graph learning is an NP-hard combinatorial problem, therefore, designing a general tractable optimization method is extremely challenging. In this paper, we introduce a unified graph learning framework lying at the integration of Gaussian graphical models and spectral graph theory. To impose a particular structure on a graph, we first show how to formulate the combinatorial constraints as an analytical property of the graph matrix. Then we develop an optimization framework that leverages graph learning with specific structures via spectral constraints on graph matrices. The proposed algorithms are provably convergent, computationally efficient, and practically amenable for numerous graph-based tasks. Extensive numerical experiments with both synthetic and real data sets illustrate the effectiveness of the proposed algorithms. The code for all the simulations is made available as an open source repository.