 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical analysis of Biding Precedent efficiency in the Brazilian Supreme Court via Similar Case Retrieval
Jul 09, 2024Binding precedents (S\'umulas Vinculantes) constitute a juridical instrument unique to the Brazilian legal system and whose objectives include the protection of the Federal Supreme Court against repetitive demands. Studies of the effectiveness of these instruments in decreasing the Court's exposure to similar cases, however, indicate that they tend to fail in such a direction, with some of the binding precedents seemingly creating new demands. We empirically assess the legal impact of five binding precedents, 11, 14, 17, 26 and 37, at the highest court level through their effects on the legal subjects they address. This analysis is only possible through the comparison of the Court's ruling about the precedents' themes before they are created, which means that these decisions should be detected through techniques of Similar Case Retrieval. The contributions of this article are therefore twofold: on the mathematical side, we compare the uses of different methods of Natural Language Processing -- TF-IDF, LSTM, BERT, and regex -- for Similar Case Retrieval, whereas on the legal side, we contrast the inefficiency of these binding precedents with a set of hypotheses that may justify their repeated usage. We observe that the deep learning models performed significantly worse in the specific Similar Case Retrieval task and that the reasons for binding precedents to fail in responding to repetitive demand are heterogeneous and case-dependent, making it impossible to single out a specific cause.
Exploring the Trade-off Between Model Performance and Explanation Plausibility of Text Classifiers Using Human Rationales
Apr 03, 2024Saliency post-hoc explainability methods are important tools for understanding increasingly complex NLP models. While these methods can reflect the model's reasoning, they may not align with human intuition, making the explanations not plausible. In this work, we present a methodology for incorporating rationales, which are text annotations explaining human decisions, into text classification models. This incorporation enhances the plausibility of post-hoc explanations while preserving their faithfulness. Our approach is agnostic to model architectures and explainability methods. We introduce the rationales during model training by augmenting the standard cross-entropy loss with a novel loss function inspired by contrastive learning. By leveraging a multi-objective optimization algorithm, we explore the trade-off between the two loss functions and generate a Pareto-optimal frontier of models that balance performance and plausibility. Through extensive experiments involving diverse models, datasets, and explainability methods, we demonstrate that our approach significantly enhances the quality of model explanations without causing substantial (sometimes negligible) degradation in the original model's performance.
Granularity at Scale: Estimating Neighborhood Well-Being from High-Resolution Orthographic Imagery and Hybrid Learning
Sep 28, 2023



Many areas of the world are without basic information on the well-being of the residing population due to limitations in existing data collection methods. Overhead images obtained remotely, such as from satellite or aircraft, can help serve as windows into the state of life on the ground and help "fill in the gaps" where community information is sparse, with estimates at smaller geographic scales requiring higher resolution sensors. Concurrent with improved sensor resolutions, recent advancements in machine learning and computer vision have made it possible to quickly extract features from and detect patterns in image data, in the process correlating these features with other information. In this work, we explore how well two approaches, a supervised convolutional neural network and semi-supervised clustering based on bag-of-visual-words, estimate population density, median household income, and educational attainment of individual neighborhoods from publicly available high-resolution imagery of cities throughout the United States. Results and analyses indicate that features extracted from the imagery can accurately estimate the density (R$^2$ up to 0.81) of neighborhoods, with the supervised approach able to explain about half the variation in a population's income and education. In addition to the presented approaches serving as a basis for further geographic generalization, the novel semi-supervised approach provides a foundation for future work seeking to estimate fine-scale information from overhead imagery without the need for label data.
WSAM: Visual Explanations from Style Augmentation as Adversarial Attacker and Their Influence in Image Classification
Aug 29, 2023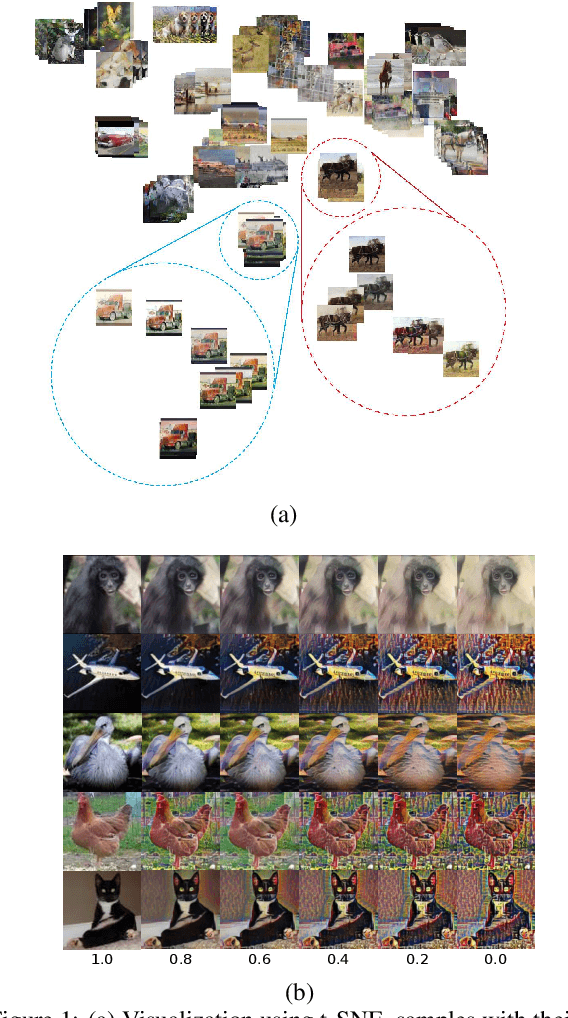



Currently, style augmentation is capturing attention due to convolutional neural networks (CNN) being strongly biased toward recognizing textures rather than shapes. Most existing styling methods either perform a low-fidelity style transfer or a weak style representation in the embedding vector. This paper outlines a style augmentation algorithm using stochastic-based sampling with noise addition to improving randomization on a general linear transformation for style transfer. With our augmentation strategy, all models not only present incredible robustness against image stylizing but also outperform all previous methods and surpass the state-of-the-art performance for the STL-10 dataset. In addition, we present an analysis of the model interpretations under different style variations. At the same time, we compare comprehensive experiments demonstrating the performance when applied to deep neural architectures in training settings.
ChartText: Linking Text with Charts in Documents
Jan 13, 2022



Recent works show that interactive documents connecting text with visualizations facilitate reading comprehension. However, creating this type of content requires specialized knowledge. We present ChartText, a method that links text with visualizations in this work. Our approach supports documents that include bar charts, line charts, and scatter plots. ChartText receives the visual encoding of the visualization and its associated text as input. It then performs the linking in two stages: The matching stage creates individual links relating simple phrases between the text and the chart. Then, it combines the individual links according to the visual channels in the grouping stage, building more meaningful connections. We use two datasets to design and evaluate our method; the first comes from web documents (24 bar charts and texts) and the second from academic documents (25 bar charts, 25 line charts, and 25 scatter plots with their texts). Our experiments show that our method obtains F1 scores of 0.50 and 0.66 on both datasets. We can also use a semi-automatic approach correcting individual links; in this case, the scores rise to 0.68 and 0.84, respectively. To show the usefulness of our technique, we implement two proofs of concept. We create interactive documents using graphic overlays in the first one, facilitating the reading experience. We use voice instead of text to annotate charts in real-time in the second. For example, in a videoconference, our technique can automatically annotate a chart following the presenter's description.