 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Fairness with Selective Labels
May 21, 2026Long-term fairness algorithms aim to satisfy fairness beyond static and short-term notions by accounting for the dynamics between decision-making policies and population behavior. Most previous approaches evaluate performance and fairness measures from observable features and a label, which is assumed to be fully observed. However, in scenarios such as hiring or lending, the labels (e.g., ability to repay the loan) are selective labels as they are only revealed based on positive decisions (e.g., when a loan is granted). In this paper, we study long-term fairness in the selective labels setting and analytically show that naive solutions do not guarantee fairness. To address this gap, we then introduce a novel framework that leverages both the observed data and a label predictor model to estimate the true fairness measure value by decomposing it into the observed fairness and bias from label predictions. This allows us to derive sufficient conditions to satisfy true fairness from observable quantities by using the confidence in the predictor model. Finally, we rely on our theoretical results to propose a novel reinforcement learning algorithm for effective long-term fair decision-making with selective labels. In semisynthetic environments, the proposed algorithm reached comparable fairness and performance to an agent with oracle access to the true labels.
M$^2$FGB: A Min-Max Gradient Boosting Framework for Subgroup Fairness
Apr 16, 2025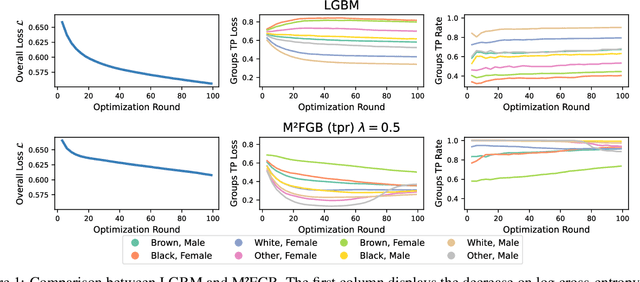

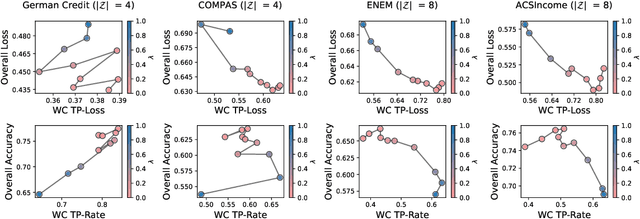

In recent years, fairness in machine learning has emerged as a critical concern to ensure that developed and deployed predictive models do not have disadvantageous predictions for marginalized groups. It is essential to mitigate discrimination against individuals based on protected attributes such as gender and race. In this work, we consider applying subgroup justice concepts to gradient-boosting machines designed for supervised learning problems. Our approach expanded gradient-boosting methodologies to explore a broader range of objective functions, which combines conventional losses such as the ones from classification and regression and a min-max fairness term. We study relevant theoretical properties of the solution of the min-max optimization problem. The optimization process explored the primal-dual problems at each boosting round. This generic framework can be adapted to diverse fairness concepts. The proposed min-max primal-dual gradient boosting algorithm was theoretically shown to converge under mild conditions and empirically shown to be a powerful and flexible approach to address binary and subgroup fairness.
Best Practices for Responsible Machine Learning in Credit Scoring
Sep 30, 2024



The widespread use of machine learning in credit scoring has brought significant advancements in risk assessment and decision-making. However, it has also raised concerns about potential biases, discrimination, and lack of transparency in these automated systems. This tutorial paper performed a non-systematic literature review to guide best practices for developing responsible machine learning models in credit scoring, focusing on fairness, reject inference, and explainability. We discuss definitions, metrics, and techniques for mitigating biases and ensuring equitable outcomes across different groups. Additionally, we address the issue of limited data representativeness by exploring reject inference methods that incorporate information from rejected loan applications. Finally, we emphasize the importance of transparency and explainability in credit models, discussing techniques that provide insights into the decision-making process and enable individuals to understand and potentially improve their creditworthiness. By adopting these best practices, financial institutions can harness the power of machine learning while upholding ethical and responsible lending practices.
Granularity at Scale: Estimating Neighborhood Well-Being from High-Resolution Orthographic Imagery and Hybrid Learning
Sep 28, 2023



Many areas of the world are without basic information on the well-being of the residing population due to limitations in existing data collection methods. Overhead images obtained remotely, such as from satellite or aircraft, can help serve as windows into the state of life on the ground and help "fill in the gaps" where community information is sparse, with estimates at smaller geographic scales requiring higher resolution sensors. Concurrent with improved sensor resolutions, recent advancements in machine learning and computer vision have made it possible to quickly extract features from and detect patterns in image data, in the process correlating these features with other information. In this work, we explore how well two approaches, a supervised convolutional neural network and semi-supervised clustering based on bag-of-visual-words, estimate population density, median household income, and educational attainment of individual neighborhoods from publicly available high-resolution imagery of cities throughout the United States. Results and analyses indicate that features extracted from the imagery can accurately estimate the density (R$^2$ up to 0.81) of neighborhoods, with the supervised approach able to explain about half the variation in a population's income and education. In addition to the presented approaches serving as a basis for further geographic generalization, the novel semi-supervised approach provides a foundation for future work seeking to estimate fine-scale information from overhead imagery without the need for label data.