 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFooling Neural Networks for Motion Forecasting via Adversarial Attacks
Mar 11, 2024Human motion prediction is still an open problem, which is extremely important for autonomous driving and safety applications. Although there are great advances in this area, the widely studied topic of adversarial attacks has not been applied to multi-regression models such as GCNs and MLP-based architectures in human motion prediction. This work intends to reduce this gap using extensive quantitative and qualitative experiments in state-of-the-art architectures similar to the initial stages of adversarial attacks in image classification. The results suggest that models are susceptible to attacks even on low levels of perturbation. We also show experiments with 3D transformations that affect the model performance, in particular, we show that most models are sensitive to simple rotations and translations which do not alter joint distances. We conclude that similar to earlier CNN models, motion forecasting tasks are susceptible to small perturbations and simple 3D transformations.
Context-based Interpretable Spatio-Temporal Graph Convolutional Network for Human Motion Forecasting
Feb 21, 2024



Human motion prediction is still an open problem extremely important for autonomous driving and safety applications. Due to the complex spatiotemporal relation of motion sequences, this remains a challenging problem not only for movement prediction but also to perform a preliminary interpretation of the joint connections. In this work, we present a Context-based Interpretable Spatio-Temporal Graph Convolutional Network (CIST-GCN), as an efficient 3D human pose forecasting model based on GCNs that encompasses specific layers, aiding model interpretability and providing information that might be useful when analyzing motion distribution and body behavior. Our architecture extracts meaningful information from pose sequences, aggregates displacements and accelerations into the input model, and finally predicts the output displacements. Extensive experiments on Human 3.6M, AMASS, 3DPW, and ExPI datasets demonstrate that CIST-GCN outperforms previous methods in human motion prediction and robustness. Since the idea of enhancing interpretability for motion prediction has its merits, we showcase experiments towards it and provide preliminary evaluations of such insights here. available code: https://github.com/QualityMinds/cistgcn
WSAM: Visual Explanations from Style Augmentation as Adversarial Attacker and Their Influence in Image Classification
Aug 29, 2023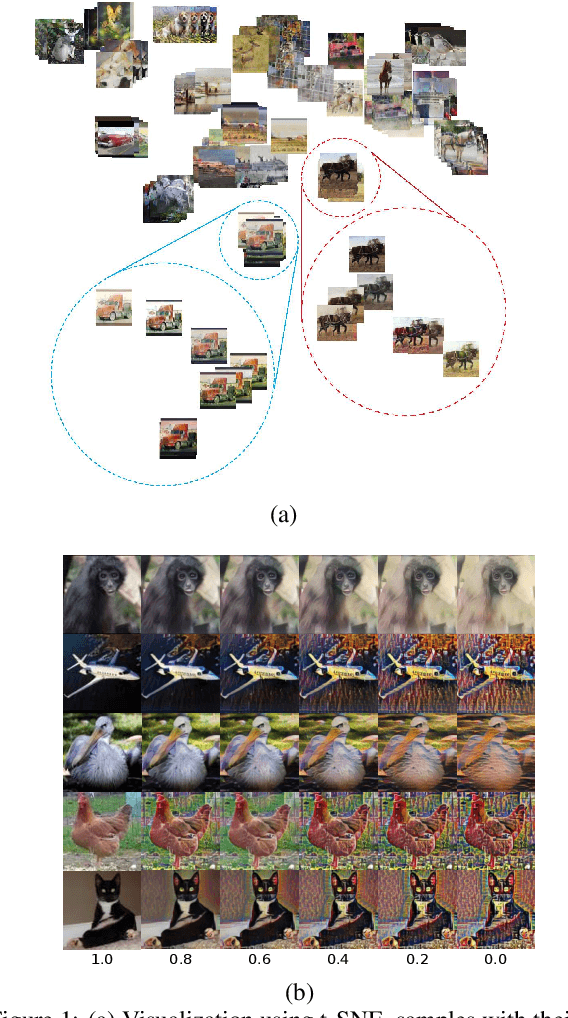



Currently, style augmentation is capturing attention due to convolutional neural networks (CNN) being strongly biased toward recognizing textures rather than shapes. Most existing styling methods either perform a low-fidelity style transfer or a weak style representation in the embedding vector. This paper outlines a style augmentation algorithm using stochastic-based sampling with noise addition to improving randomization on a general linear transformation for style transfer. With our augmentation strategy, all models not only present incredible robustness against image stylizing but also outperform all previous methods and surpass the state-of-the-art performance for the STL-10 dataset. In addition, we present an analysis of the model interpretations under different style variations. At the same time, we compare comprehensive experiments demonstrating the performance when applied to deep neural architectures in training settings.