 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tool Calling to Symbolic Thinking: LLMs in a Persistent Lisp Metaprogramming Loop
Jun 08, 2025We propose a novel architecture for integrating large language models (LLMs) with a persistent, interactive Lisp environment. This setup enables LLMs to define, invoke, and evolve their own tools through programmatic interaction with a live REPL. By embedding Lisp expressions within generation and intercepting them via a middleware layer, the system allows for stateful external memory, reflective programming, and dynamic tool creation. We present a design framework and architectural principles to guide future implementations of interactive AI systems that integrate symbolic programming with neural language generation.
Scalable Unit Harmonization in Medical Informatics Using Bi-directional Transformers and Bayesian-Optimized BM25 and Sentence Embedding Retrieval
May 01, 2025Objective: To develop and evaluate a scalable methodology for harmonizing inconsistent units in large-scale clinical datasets, addressing a key barrier to data interoperability. Materials and Methods: We designed a novel unit harmonization system combining BM25, sentence embeddings, Bayesian optimization, and a bidirectional transformer based binary classifier for retrieving and matching laboratory test entries. The system was evaluated using the Optum Clinformatics Datamart dataset (7.5 billion entries). We implemented a multi-stage pipeline: filtering, identification, harmonization proposal generation, automated re-ranking, and manual validation. Performance was assessed using Mean Reciprocal Rank (MRR) and other standard information retrieval metrics. Results: Our hybrid retrieval approach combining BM25 and sentence embeddings (MRR: 0.8833) significantly outperformed both lexical-only (MRR: 0.7985) and embedding-only (MRR: 0.5277) approaches. The transformer-based reranker further improved performance (absolute MRR improvement: 0.10), bringing the final system MRR to 0.9833. The system achieved 83.39\% precision at rank 1 and 94.66\% recall at rank 5. Discussion: The hybrid architecture effectively leverages the complementary strengths of lexical and semantic approaches. The reranker addresses cases where initial retrieval components make errors due to complex semantic relationships in medical terminology. Conclusion: Our framework provides an efficient, scalable solution for unit harmonization in clinical datasets, reducing manual effort while improving accuracy. Once harmonized, data can be reused seamlessly in different analyses, ensuring consistency across healthcare systems and enabling more reliable multi-institutional studies and meta-analyses.
MiceBoneChallenge: Micro-CT public dataset and six solutions for automatic growth plate detection in micro-CT mice bone scans
Nov 26, 2024



Detecting and quantifying bone changes in micro-CT scans of rodents is a common task in preclinical drug development studies. However, this task is manual, time-consuming and subject to inter- and intra-observer variability. In 2024, Anonymous Company organized an internal challenge to develop models for automatic bone quantification. We prepared and annotated a high-quality dataset of 3D $\mu$CT bone scans from $83$ mice. The challenge attracted over $80$ AI scientists from around the globe who formed $23$ teams. The participants were tasked with developing a solution to identify the plane where the bone growth happens, which is essential for fully automatic segmentation of trabecular bone. As a result, six computer vision solutions were developed that can accurately identify the location of the growth plate plane. The solutions achieved the mean absolute error of $1.91\pm0.87$ planes from the ground truth on the test set, an accuracy level acceptable for practical use by a radiologist. The annotated 3D scans dataset along with the six solutions and source code, is being made public, providing researchers with opportunities to develop and benchmark their own approaches. The code, trained models, and the data will be shared.
Modelos Generativos basados en Mecanismos de Difusión
Feb 18, 2023Diffusion-based generative models are a design framework that allows generating new images from processes analogous to those found in non-equilibrium thermodynamics. These models model the reversal of a physical diffusion process in which two miscible liquids of different colors progressively mix until they form a homogeneous mixture. Diffusion models can be applied to signals of a different nature, such as audio and image signals. In the image case, a progressive pixel corruption process is carried out by applying random noise, and a neural network is trained to revert each one of the corruption steps. For the reconstruction process to be reversible, it is necessary to carry out the corruption very progressively. If the training of the neural network is successful, it will be possible to generate an image from random noise by chaining a number of steps similar to those used for image deconstruction at training time. In this article we present the theoretical foundations on which this method is based as well as some of its applications. This article is in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.
Transformadores: Fundamentos teoricos y Aplicaciones
Feb 18, 2023Transformers are a neural network architecture originally designed for natural language processing that it is now a mainstream tool for solving a wide variety of problems, including natural language processing, sound, image, reinforcement learning, and other problems with heterogeneous input data. Its distinctive feature is its self-attention system, based on attention to one's own sequence, which derives from the previously introduced attention system. This article provides the reader with the necessary context to understand the most recent research articles and presents the mathematical and algorithmic foundations of the elements that make up this type of network. The different components that make up this architecture and the variations that may exist are also studied, as well as some applications of the transformer models. This article is in Spanish to bring this scientific knowledge to the Spanish-speaking community.
Autocodificadores Variacionales (VAE) Fundamentos Teóricos y Aplicaciones
Feb 18, 2023VAEs are probabilistic graphical models based on neural networks that allow the coding of input data in a latent space formed by simpler probability distributions and the reconstruction, based on such latent variables, of the source data. After training, the reconstruction network, called decoder, is capable of generating new elements belonging to a close distribution, ideally equal to the original one. This article has been written in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.
Redes Generativas Adversarias (GAN) Fundamentos Teóricos y Aplicaciones
Feb 18, 2023Generative adversarial networks (GANs) are a method based on the training of two neural networks, one called generator and the other discriminator, competing with each other to generate new instances that resemble those of the probability distribution of the training data. GANs have a wide range of applications in fields such as computer vision, semantic segmentation, time series synthesis, image editing, natural language processing, and image generation from text, among others. Generative models model the probability distribution of a data set, but instead of providing a probability value, they generate new instances that are close to the original distribution. GANs use a learning scheme that allows the defining attributes of the probability distribution to be encoded in a neural network, allowing instances to be generated that resemble the original probability distribution. This article presents the theoretical foundations of this type of network as well as the basic architecture schemes and some of its applications. This article is in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.
Identification and Visualization of the Underlying Independent Causes of the Diagnostic of Diabetic Retinopathy made by a Deep Learning Classifier
Sep 23, 2018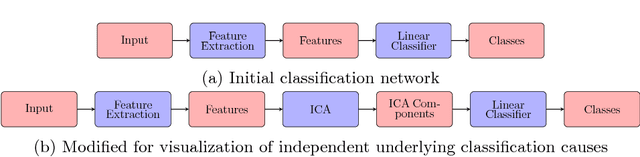

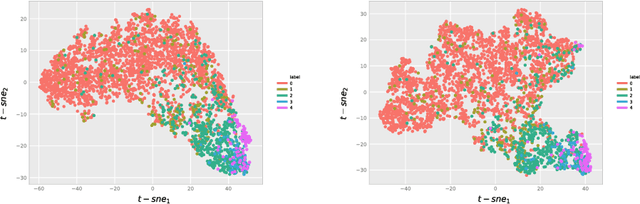
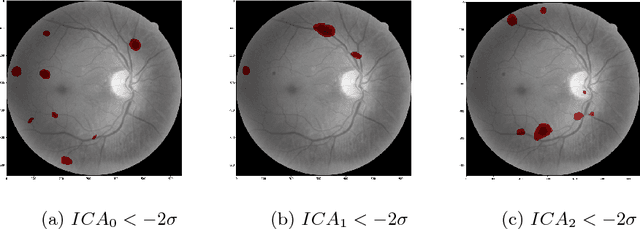
Interpretability is a key factor in the design of automatic classifiers for medical diagnosis. Deep learning models have been proven to be a very effective classification algorithm when trained in a supervised way with enough data. The main concern is the difficulty of inferring rationale interpretations from them. Different attempts have been done in last years in order to convert deep learning classifiers from high confidence statistical black box machines into self-explanatory models. In this paper we go forward into the generation of explanations by identifying the independent causes that use a deep learning model for classifying an image into a certain class. We use a combination of Independent Component Analysis with a Score Visualization technique. In this paper we study the medical problem of classifying an eye fundus image into 5 levels of Diabetic Retinopathy. We conclude that only 3 independent components are enough for the differentiation and correct classification between the 5 disease standard classes. We propose a method for visualizing them and detecting lesions from the generated visual maps.
A Deep Learning Interpretable Classifier for Diabetic Retinopathy Disease Grading
Dec 21, 2017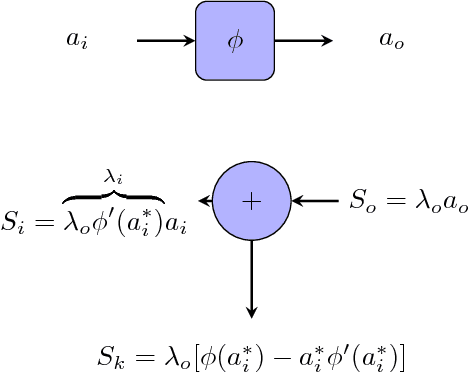

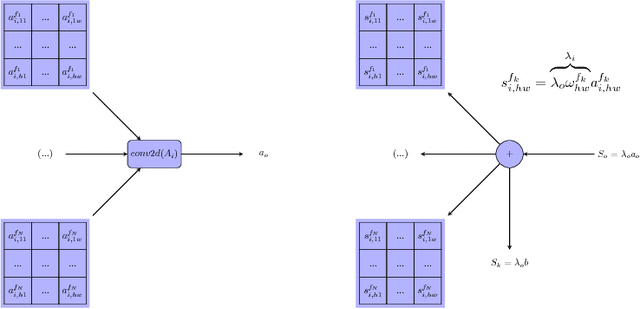
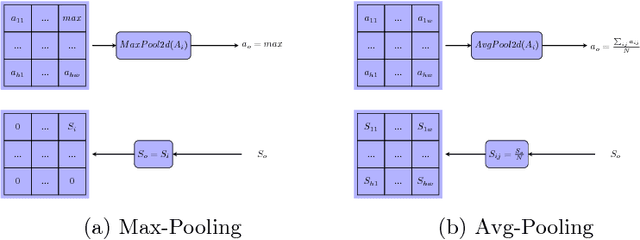
Deep neural network models have been proven to be very successful in image classification tasks, also for medical diagnosis, but their main concern is its lack of interpretability. They use to work as intuition machines with high statistical confidence but unable to give interpretable explanations about the reported results. The vast amount of parameters of these models make difficult to infer a rationale interpretation from them. In this paper we present a diabetic retinopathy interpretable classifier able to classify retine images into the different levels of disease severity and of explaining its results by assigning a score for every point in the hidden and input space, evaluating its contribution to the final classification in a linear way. The generated visual maps can be interpreted by an expert in order to compare its own knowledge with the interpretation given by the model.