 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman interaction classifier for LLM based chatbot
Jul 31, 2024
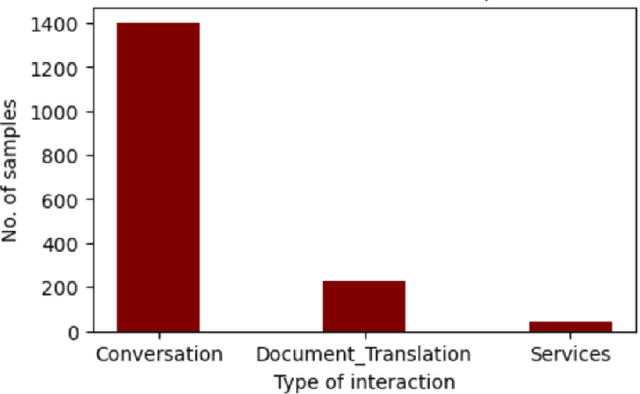

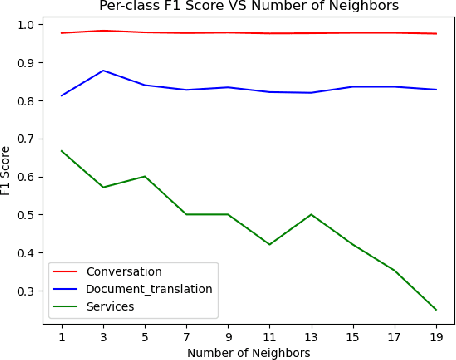
This study investigates different approaches to classify human interactions in an artificial intelligence-based environment, specifically for Applus+ IDIADA's intelligent agent AIDA. The main objective is to develop a classifier that accurately identifies the type of interaction received (Conversation, Services, or Document Translation) to direct requests to the appropriate channel and provide a more specialized and efficient service. Various models are compared, including LLM-based classifiers, KNN using Titan and Cohere embeddings, SVM, and artificial neural networks. Results show that SVM and ANN models with Cohere embeddings achieve the best overall performance, with superior F1 scores and faster execution times compared to LLM-based approaches. The study concludes that the SVM model with Cohere embeddings is the most suitable option for classifying human interactions in the AIDA environment, offering an optimal balance between accuracy and computational efficiency.
3DPeople: Modeling the Geometry of Dressed Humans
Apr 09, 2019



Recent advances in 3D human shape estimation build upon parametric representations that model very well the shape of the naked body, but are not appropriate to represent the clothing geometry. In this paper, we present an approach to model dressed humans and predict their geometry from single images. We contribute in three fundamental aspects of the problem, namely, a new dataset, a novel shape parameterization algorithm and an end-to-end deep generative network for predicting shape. First, we present 3DPeople, a large-scale synthetic dataset with 2.5 Million photo-realistic images of 80 subjects performing 70 activities and wearing diverse outfits. Besides providing textured 3D meshes for clothes and body, we annotate the dataset with segmentation masks, skeletons, depth, normal maps and optical flow. All this together makes 3DPeople suitable for a plethora of tasks. We then represent the 3D shapes using 2D geometry images. To build these images we propose a novel spherical area-preserving parameterization algorithm based on the optimal mass transportation method. We show this approach to improve existing spherical maps which tend to shrink the elongated parts of the full body models such as the arms and legs, making the geometry images incomplete. Finally, we design a multi-resolution deep generative network that, given an input image of a dressed human, predicts his/her geometry image (and thus the clothed body shape) in an end-to-end manner. We obtain very promising results in jointly capturing body pose and clothing shape, both for synthetic validation and on the wild images.