 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Criteria Automated MLOps Pipeline for Cost-Effective Cloud-Based Classifier Retraining in Response to Data Distribution Shifts
Dec 12, 2025The performance of machine learning (ML) models often deteriorates when the underlying data distribution changes over time, a phenomenon known as data distribution drift. When this happens, ML models need to be retrained and redeployed. ML Operations (MLOps) is often manual, i.e., humans trigger the process of model retraining and redeployment. In this work, we present an automated MLOps pipeline designed to address neural network classifier retraining in response to significant data distribution changes. Our MLOps pipeline employs multi-criteria statistical techniques to detect distribution shifts and triggers model updates only when necessary, ensuring computational efficiency and resource optimization. We demonstrate the effectiveness of our framework through experiments on several benchmark anomaly detection data sets, showing significant improvements in model accuracy and robustness compared to traditional retraining strategies. Our work provides a foundation for deploying more reliable and adaptive ML systems in dynamic real-world settings, where data distribution changes are common.
Impact of Inaccurate Contamination Ratio on Robust Unsupervised Anomaly Detection
Aug 14, 2024Training data sets intended for unsupervised anomaly detection, typically presumed to be anomaly-free, often contain anomalies (or contamination), a challenge that significantly undermines model performance. Most robust unsupervised anomaly detection models rely on contamination ratio information to tackle contamination. However, in reality, contamination ratio may be inaccurate. We investigate on the impact of inaccurate contamination ratio information in robust unsupervised anomaly detection. We verify whether they are resilient to misinformed contamination ratios. Our investigation on 6 benchmark data sets reveals that such models are not adversely affected by exposure to misinformation. In fact, they can exhibit improved performance when provided with such inaccurate contamination ratios.
Performance-Agnostic Fusion of Probabilistic Classifier Outputs
Sep 01, 2020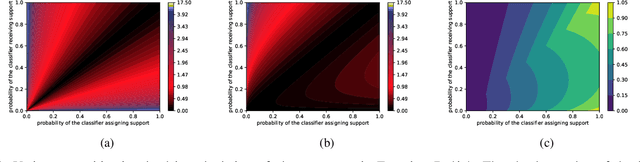

We propose a method for combining probabilistic outputs of classifiers to make a single consensus class prediction when no further information about the individual classifiers is available, beyond that they have been trained for the same task. The lack of relevant prior information rules out typical applications of Bayesian or Dempster-Shafer methods, and the default approach here would be methods based on the principle of indifference, such as the sum or product rule, which essentially weight all classifiers equally. In contrast, our approach considers the diversity between the outputs of the various classifiers, iteratively updating predictions based on their correspondence with other predictions until the predictions converge to a consensus decision. The intuition behind this approach is that classifiers trained for the same task should typically exhibit regularities in their outputs on a new task; the predictions of classifiers which differ significantly from those of others are thus given less credence using our approach. The approach implicitly assumes a symmetric loss function, in that the relative cost of various prediction errors are not taken into account. Performance of the model is demonstrated on different benchmark datasets. Our proposed method works well in situations where accuracy is the performance metric; however, it does not output calibrated probabilities, so it is not suitable in situations where such probabilities are required for further processing.
A Coordinated Search Strategy for Multiple Solitary Robots: An Extension
May 25, 2019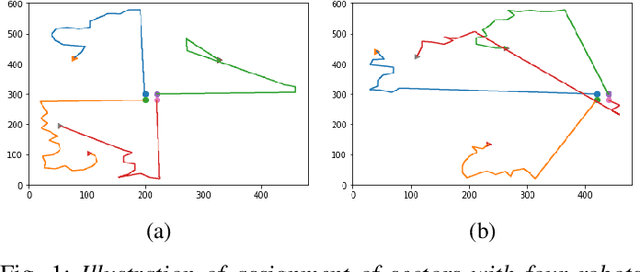
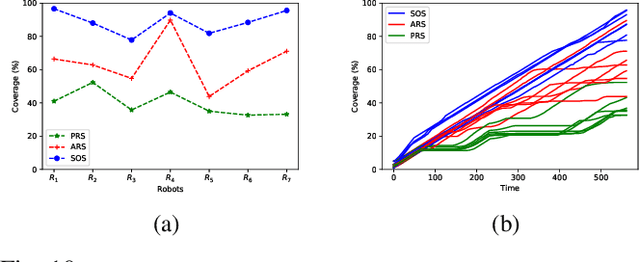
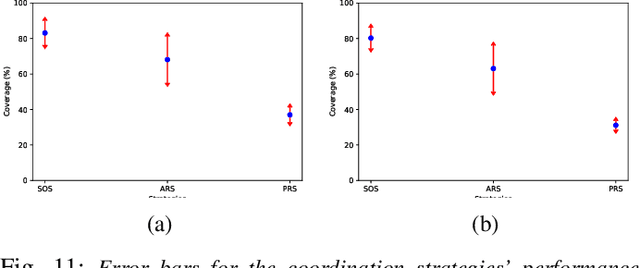
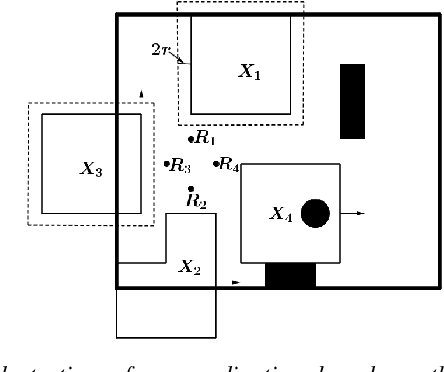
The problem of coordination without a priori information about the environment is important in robotics. Applications vary from formation control to search and rescue. This paper considers the problem of search by a group of solitary robots: self-interested robots without a priori knowledge about each other, and with restricted communication capacity. When the capacity of robots to communicate is limited, they may obliviously search in overlapping regions (i.e. be subject to interference). Interference hinders robot progress, and strategies have been proposed in the literature to mitigate interference [1], [2]. Interaction of solitary robots has attracted much interest in robotics, but the problem of mitigating interference when time for search is limited remains an important area of research. We propose a coordination strategy based on the method of cellular decomposition [3] where we employ the concept of soft obstacles: a robot considers cells assigned to other robots as obstacles. The performance of the proposed strategy is demonstrated by means of simulation experiments. Simulations indicate the utility of the strategy in situations where a known upper bound on the search time precludes search of the entire environment.
Machine Learning Methods for Shark Detection
May 21, 2019



This essay reviews human observer-based methods employed in shark spotting in Muizenberg Beach. It investigates Machine Learning methods for automated shark detection with the aim of enhancing human observation. A questionnaire and interview were used to collect information about shark spotting, the motivation of the actual Shark Spotter program and its limitations. We have defined a list of desirable properties for our model and chosen the adequate mathematical techniques. The preliminary results of the research show that we can expect to extract useful information from shark images despite the geometric transformations that sharks perform, its features do not change. To conclude, we have partially implemented our model; the remaining implementation requires dataset.