 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Inaccurate Contamination Ratio on Robust Unsupervised Anomaly Detection
Aug 14, 2024Training data sets intended for unsupervised anomaly detection, typically presumed to be anomaly-free, often contain anomalies (or contamination), a challenge that significantly undermines model performance. Most robust unsupervised anomaly detection models rely on contamination ratio information to tackle contamination. However, in reality, contamination ratio may be inaccurate. We investigate on the impact of inaccurate contamination ratio information in robust unsupervised anomaly detection. We verify whether they are resilient to misinformed contamination ratios. Our investigation on 6 benchmark data sets reveals that such models are not adversely affected by exposure to misinformation. In fact, they can exhibit improved performance when provided with such inaccurate contamination ratios.
Deep Learning for Network Anomaly Detection under Data Contamination: Evaluating Robustness and Mitigating Performance Degradation
Jul 11, 2024


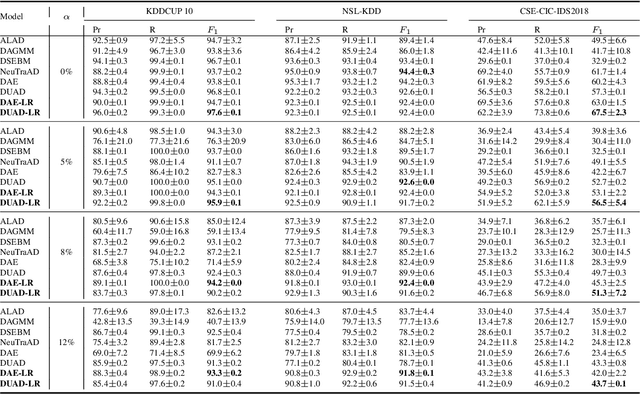
Deep learning (DL) has emerged as a crucial tool in network anomaly detection (NAD) for cybersecurity. While DL models for anomaly detection excel at extracting features and learning patterns from data, they are vulnerable to data contamination -- the inadvertent inclusion of attack-related data in training sets presumed benign. This study evaluates the robustness of six unsupervised DL algorithms against data contamination using our proposed evaluation protocol. Results demonstrate significant performance degradation in state-of-the-art anomaly detection algorithms when exposed to contaminated data, highlighting the critical need for self-protection mechanisms in DL-based NAD models. To mitigate this vulnerability, we propose an enhanced auto-encoder with a constrained latent representation, allowing normal data to cluster more densely around a learnable center in the latent space. Our evaluation reveals that this approach exhibits improved resistance to data contamination compared to existing methods, offering a promising direction for more robust NAD systems.