 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Network Anomaly Detection under Data Contamination: Evaluating Robustness and Mitigating Performance Degradation
Jul 11, 2024


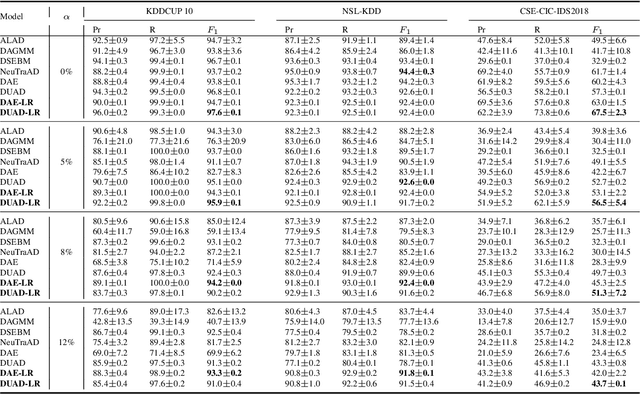
Deep learning (DL) has emerged as a crucial tool in network anomaly detection (NAD) for cybersecurity. While DL models for anomaly detection excel at extracting features and learning patterns from data, they are vulnerable to data contamination -- the inadvertent inclusion of attack-related data in training sets presumed benign. This study evaluates the robustness of six unsupervised DL algorithms against data contamination using our proposed evaluation protocol. Results demonstrate significant performance degradation in state-of-the-art anomaly detection algorithms when exposed to contaminated data, highlighting the critical need for self-protection mechanisms in DL-based NAD models. To mitigate this vulnerability, we propose an enhanced auto-encoder with a constrained latent representation, allowing normal data to cluster more densely around a learnable center in the latent space. Our evaluation reveals that this approach exhibits improved resistance to data contamination compared to existing methods, offering a promising direction for more robust NAD systems.
A Revealing Large-Scale Evaluation of Unsupervised Anomaly Detection Algorithms
Apr 21, 2022
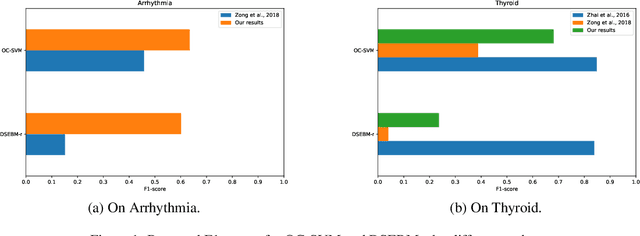
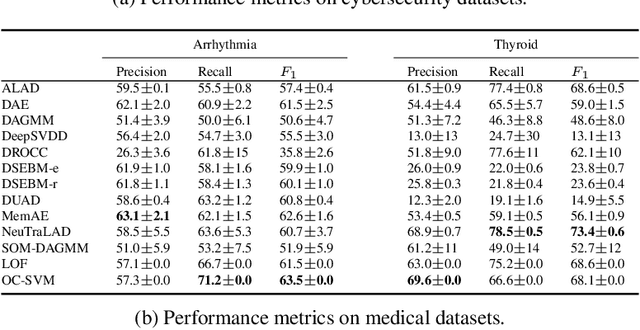
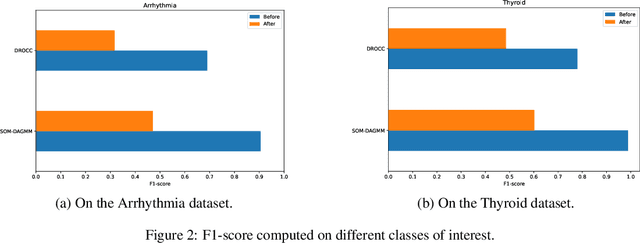
Anomaly detection has many applications ranging from bank-fraud detection and cyber-threat detection to equipment maintenance and health monitoring. However, choosing a suitable algorithm for a given application remains a challenging design decision, often informed by the literature on anomaly detection algorithms. We extensively reviewed twelve of the most popular unsupervised anomaly detection methods. We observed that, so far, they have been compared using inconsistent protocols - the choice of the class of interest or the positive class, the split of training and test data, and the choice of hyperparameters - leading to ambiguous evaluations. This observation led us to define a coherent evaluation protocol which we then used to produce an updated and more precise picture of the relative performance of the twelve methods on five widely used tabular datasets. While our evaluation cannot pinpoint a method that outperforms all the others on all datasets, it identifies those that stand out and revise misconceived knowledge about their relative performances.