 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-training and Co-distillation for Quality Improvement and Compression of Language Models
Nov 07, 2023
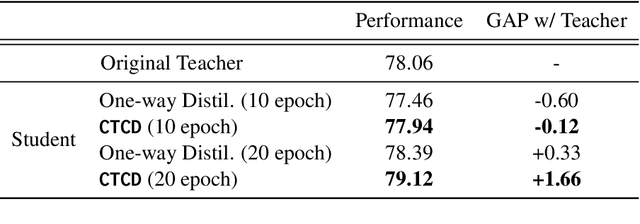
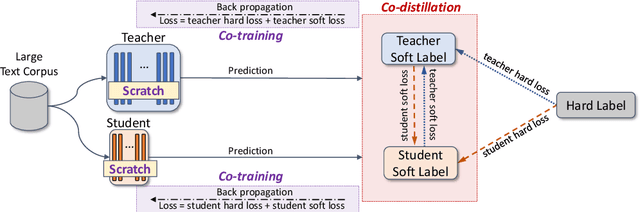

Knowledge Distillation (KD) compresses computationally expensive pre-trained language models (PLMs) by transferring their knowledge to smaller models, allowing their use in resource-constrained or real-time settings. However, most smaller models fail to surpass the performance of the original larger model, resulting in sacrificing performance to improve inference speed. To address this issue, we propose Co-Training and Co-Distillation (CTCD), a novel framework that improves performance and inference speed together by co-training two models while mutually distilling knowledge. The CTCD framework successfully achieves this based on two significant findings: 1) Distilling knowledge from the smaller model to the larger model during co-training improves the performance of the larger model. 2) The enhanced performance of the larger model further boosts the performance of the smaller model. The CTCD framework shows promise as it can be combined with existing techniques like architecture design or data augmentation, replacing one-way KD methods, to achieve further performance improvement. Extensive ablation studies demonstrate the effectiveness of CTCD, and the small model distilled by CTCD outperforms the original larger model by a significant margin of 1.66 on the GLUE benchmark.
A Study on Knowledge Distillation from Weak Teacher for Scaling Up Pre-trained Language Models
May 26, 2023Distillation from Weak Teacher (DWT) is a method of transferring knowledge from a smaller, weaker teacher model to a larger student model to improve its performance. Previous studies have shown that DWT can be effective in the vision domain and natural language processing (NLP) pre-training stage. Specifically, DWT shows promise in practical scenarios, such as enhancing new generation or larger models using pre-trained yet older or smaller models and lacking a resource budget. However, the optimal conditions for using DWT have yet to be fully investigated in NLP pre-training. Therefore, this study examines three key factors to optimize DWT, distinct from those used in the vision domain or traditional knowledge distillation. These factors are: (i) the impact of teacher model quality on DWT effectiveness, (ii) guidelines for adjusting the weighting value for DWT loss, and (iii) the impact of parameter remapping as a student model initialization technique for DWT.
Discovering Characteristic Landmarks on Ancient Coins using Convolutional Networks
Jul 01, 2015


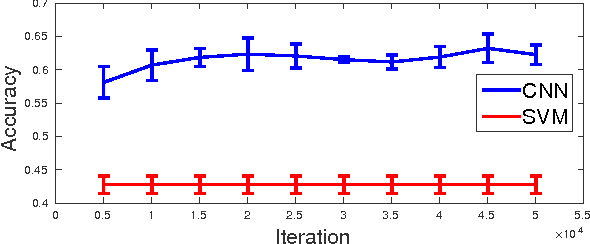
In this paper, we propose a novel method to find characteristic landmarks on ancient Roman imperial coins using deep convolutional neural network models (CNNs). We formulate an optimization problem to discover class-specific regions while guaranteeing specific controlled loss of accuracy. Analysis on visualization of the discovered region confirms that not only can the proposed method successfully find a set of characteristic regions per class, but also the discovered region is consistent with human expert annotations. We also propose a new framework to recognize the Roman coins which exploits hierarchical structure of the ancient Roman coins using the state-of-the-art classification power of the CNNs adopted to a new task of coin classification. Experimental results show that the proposed framework is able to effectively recognize the ancient Roman coins. For this research, we have collected a new Roman coin dataset where all coins are annotated and consist of observe (head) and reverse (tail) images.