 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphXForm: Graph transformer for computer-aided molecular design with application to extraction
Nov 03, 2024Generative deep learning has become pivotal in molecular design for drug discovery and materials science. A widely used paradigm is to pretrain neural networks on string representations of molecules and fine-tune them using reinforcement learning on specific objectives. However, string-based models face challenges in ensuring chemical validity and enforcing structural constraints like the presence of specific substructures. We propose to instead combine graph-based molecular representations, which can naturally ensure chemical validity, with transformer architectures, which are highly expressive and capable of modeling long-range dependencies between atoms. Our approach iteratively modifies a molecular graph by adding atoms and bonds, which ensures chemical validity and facilitates the incorporation of structural constraints. We present GraphXForm, a decoder-only graph transformer architecture, which is pretrained on existing compounds and then fine-tuned using a new training algorithm that combines elements of the deep cross-entropy method with self-improvement learning from language modeling, allowing stable fine-tuning of deep transformers with many layers. We evaluate GraphXForm on two solvent design tasks for liquid-liquid extraction, showing that it outperforms four state-of-the-art molecular design techniques, while it can flexibly enforce structural constraints or initiate the design from existing molecular structures.
Take a Step and Reconsider: Sequence Decoding for Self-Improved Neural Combinatorial Optimization
Jul 24, 2024The constructive approach within Neural Combinatorial Optimization (NCO) treats a combinatorial optimization problem as a finite Markov decision process, where solutions are built incrementally through a sequence of decisions guided by a neural policy network. To train the policy, recent research is shifting toward a 'self-improved' learning methodology that addresses the limitations of reinforcement learning and supervised approaches. Here, the policy is iteratively trained in a supervised manner, with solutions derived from the current policy serving as pseudo-labels. The way these solutions are obtained from the policy determines the quality of the pseudo-labels. In this paper, we present a simple and problem-independent sequence decoding method for self-improved learning based on sampling sequences without replacement. We incrementally follow the best solution found and repeat the sampling process from intermediate partial solutions. By modifying the policy to ignore previously sampled sequences, we force it to consider only unseen alternatives, thereby increasing solution diversity. Experimental results for the Traveling Salesman and Capacitated Vehicle Routing Problem demonstrate its strong performance. Furthermore, our method outperforms previous NCO approaches on the Job Shop Scheduling Problem.
Self-Improvement for Neural Combinatorial Optimization: Sample without Replacement, but Improvement
Mar 22, 2024Current methods for end-to-end constructive neural combinatorial optimization usually train a policy using behavior cloning from expert solutions or policy gradient methods from reinforcement learning. While behavior cloning is straightforward, it requires expensive expert solutions, and policy gradient methods are often computationally demanding and complex to fine-tune. In this work, we bridge the two and simplify the training process by sampling multiple solutions for random instances using the current model in each epoch and then selecting the best solution as an expert trajectory for supervised imitation learning. To achieve progressively improving solutions with minimal sampling, we introduce a method that combines round-wise Stochastic Beam Search with an update strategy derived from a provable policy improvement. This strategy refines the policy between rounds by utilizing the advantage of the sampled sequences with almost no computational overhead. We evaluate our approach on the Traveling Salesman Problem and the Capacitated Vehicle Routing Problem. The models trained with our method achieve comparable performance and generalization to those trained with expert data. Additionally, we apply our method to the Job Shop Scheduling Problem using a transformer-based architecture and outperform existing state-of-the-art methods by a wide margin.
Deep reinforcement learning uncovers processes for separating azeotropic mixtures without prior knowledge
Oct 10, 2023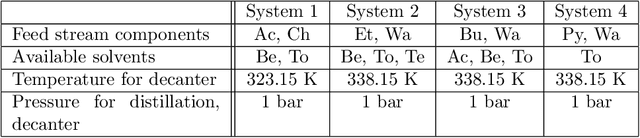

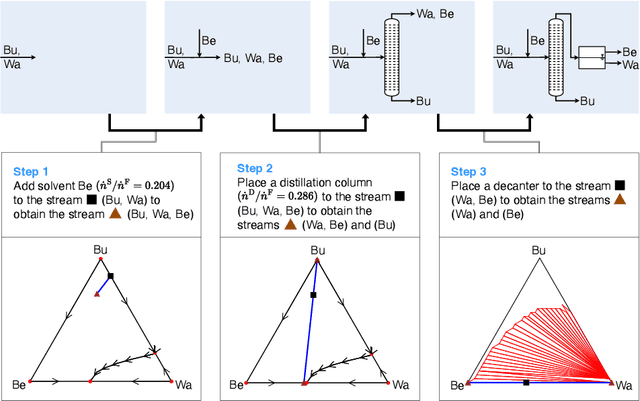
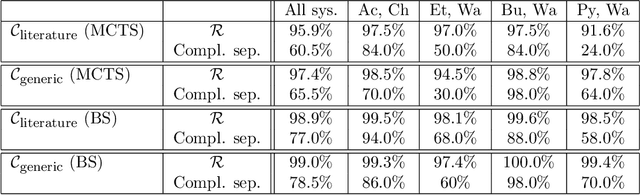
Process synthesis in chemical engineering is a complex planning problem due to vast search spaces, continuous parameters and the need for generalization. Deep reinforcement learning agents, trained without prior knowledge, have shown to outperform humans in various complex planning problems in recent years. Existing work on reinforcement learning for flowsheet synthesis shows promising concepts, but focuses on narrow problems in a single chemical system, limiting its practicality. We present a general deep reinforcement learning approach for flowsheet synthesis. We demonstrate the adaptability of a single agent to the general task of separating binary azeotropic mixtures. Without prior knowledge, it learns to craft near-optimal flowsheets for multiple chemical systems, considering different feed compositions and conceptual approaches. On average, the agent can separate more than 99% of the involved materials into pure components, while autonomously learning fundamental process engineering paradigms. This highlights the agent's planning flexibility, an encouraging step toward true generality.
Policy-Based Self-Competition for Planning Problems
Jun 07, 2023



AlphaZero-type algorithms may stop improving on single-player tasks in case the value network guiding the tree search is unable to approximate the outcome of an episode sufficiently well. One technique to address this problem is transforming the single-player task through self-competition. The main idea is to compute a scalar baseline from the agent's historical performances and to reshape an episode's reward into a binary output, indicating whether the baseline has been exceeded or not. However, this baseline only carries limited information for the agent about strategies how to improve. We leverage the idea of self-competition and directly incorporate a historical policy into the planning process instead of its scalar performance. Based on the recently introduced Gumbel AlphaZero (GAZ), we propose our algorithm GAZ 'Play-to-Plan' (GAZ PTP), in which the agent learns to find strong trajectories by planning against possible strategies of its past self. We show the effectiveness of our approach in two well-known combinatorial optimization problems, the Traveling Salesman Problem and the Job-Shop Scheduling Problem. With only half of the simulation budget for search, GAZ PTP consistently outperforms all selected single-player variants of GAZ.
* 24 pages, 5 figures
Inpainting Transformer for Anomaly Detection
Apr 28, 2021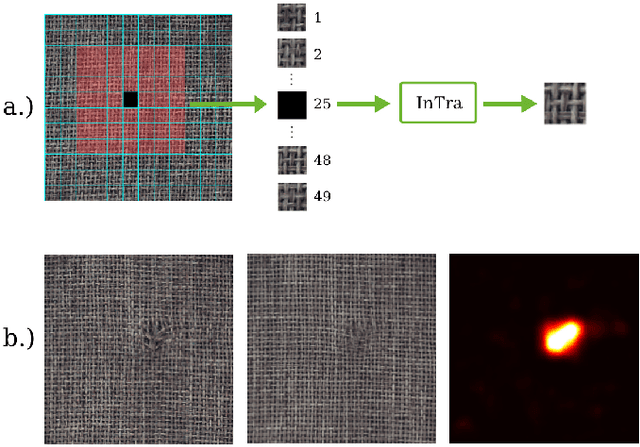
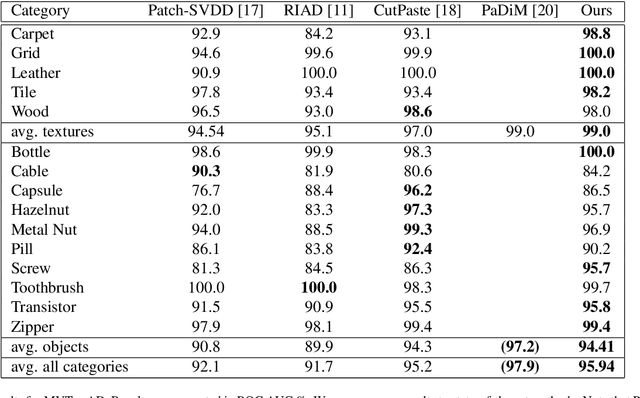


Anomaly detection in computer vision is the task of identifying images which deviate from a set of normal images. A common approach is to train deep convolutional autoencoders to inpaint covered parts of an image and compare the output with the original image. By training on anomaly-free samples only, the model is assumed to not being able to reconstruct anomalous regions properly. For anomaly detection by inpainting we suggest it to be beneficial to incorporate information from potentially distant regions. In particular we pose anomaly detection as a patch-inpainting problem and propose to solve it with a purely self-attention based approach discarding convolutions. The proposed Inpainting Transformer (InTra) is trained to inpaint covered patches in a large sequence of image patches, thereby integrating information across large regions of the input image. When learning from scratch, InTra achieves better than state-of-the-art results on the MVTec AD [1] dataset for detection and localization.