 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep reinforcement learning uncovers processes for separating azeotropic mixtures without prior knowledge
Oct 10, 2023

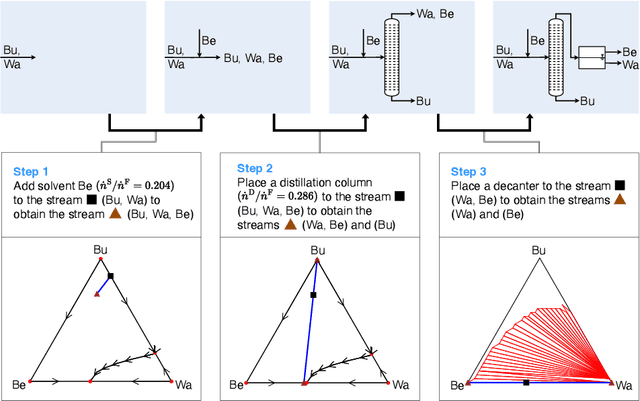
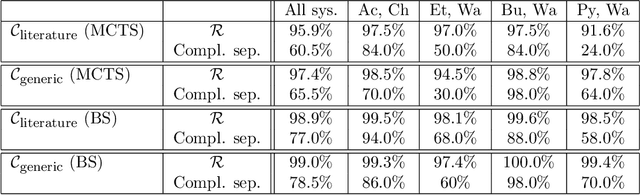
Process synthesis in chemical engineering is a complex planning problem due to vast search spaces, continuous parameters and the need for generalization. Deep reinforcement learning agents, trained without prior knowledge, have shown to outperform humans in various complex planning problems in recent years. Existing work on reinforcement learning for flowsheet synthesis shows promising concepts, but focuses on narrow problems in a single chemical system, limiting its practicality. We present a general deep reinforcement learning approach for flowsheet synthesis. We demonstrate the adaptability of a single agent to the general task of separating binary azeotropic mixtures. Without prior knowledge, it learns to craft near-optimal flowsheets for multiple chemical systems, considering different feed compositions and conceptual approaches. On average, the agent can separate more than 99% of the involved materials into pure components, while autonomously learning fundamental process engineering paradigms. This highlights the agent's planning flexibility, an encouraging step toward true generality.
Policy-Based Self-Competition for Planning Problems
Jun 07, 2023



AlphaZero-type algorithms may stop improving on single-player tasks in case the value network guiding the tree search is unable to approximate the outcome of an episode sufficiently well. One technique to address this problem is transforming the single-player task through self-competition. The main idea is to compute a scalar baseline from the agent's historical performances and to reshape an episode's reward into a binary output, indicating whether the baseline has been exceeded or not. However, this baseline only carries limited information for the agent about strategies how to improve. We leverage the idea of self-competition and directly incorporate a historical policy into the planning process instead of its scalar performance. Based on the recently introduced Gumbel AlphaZero (GAZ), we propose our algorithm GAZ 'Play-to-Plan' (GAZ PTP), in which the agent learns to find strong trajectories by planning against possible strategies of its past self. We show the effectiveness of our approach in two well-known combinatorial optimization problems, the Traveling Salesman Problem and the Job-Shop Scheduling Problem. With only half of the simulation budget for search, GAZ PTP consistently outperforms all selected single-player variants of GAZ.
* 24 pages, 5 figures
Automated Synthesis of Steady-State Continuous Processes using Reinforcement Learning
Jan 12, 2021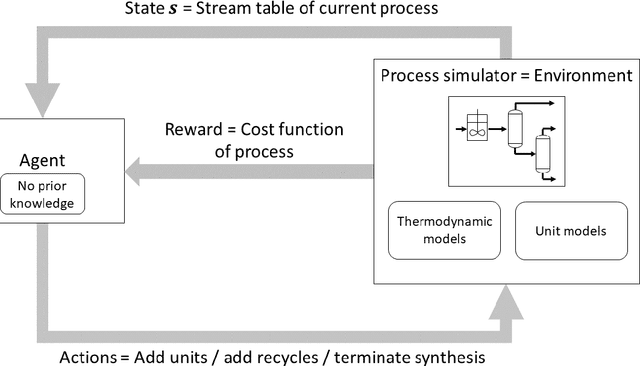

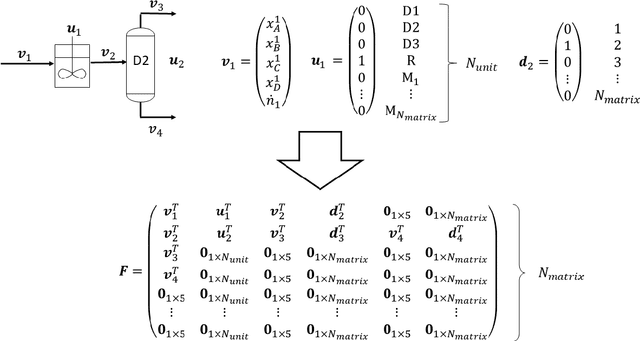

Automated flowsheet synthesis is an important field in computer-aided process engineering. The present work demonstrates how reinforcement learning (RL) can be used for automated flowsheet synthesis without any heuristics of prior knowledge of conceptual design. The environment consists of a steady-state flowsheet simulator that contains all physical knowledge. An agent is trained to take discrete actions and sequentially built up flowsheets that solve a given process problem. A novel RL method named SynGameZero is developed to ensure good exploration schemes in the complex problem. Therein, flowsheet synthesis is modelled as a game of two competing players. The RL agent plays this game against itself during training and consists of an artificial neural network and a tree search for forward planning. The method is applied successfully to a reaction-distillation process in a quaternary system.