 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in LLM Reasoning Enable Flexibility in Clinical Problem-Solving
Jan 17, 2026Large Language Models (LLMs) have achieved high accuracy on medical question-answer (QA) benchmarks, yet their capacity for flexible clinical reasoning has been debated. Here, we asked whether advances in reasoning LLMs improve their cognitive flexibility in clinical reasoning. We assessed reasoning models from the OpenAI, Grok, Gemini, Claude, and DeepSeek families on the medicine abstraction and reasoning corpus (mARC), an adversarial medical QA benchmark which utilizes the Einstellung effect to induce inflexible overreliance on learned heuristic patterns in contexts where they become suboptimal. We found that strong reasoning models avoided Einstellung-based traps more often than weaker reasoning models, achieving human-level performance on mARC. On questions most commonly missed by physicians, the top 5 performing models answered 55% to 70% correctly with high confidence, indicating that these models may be less susceptible than humans to Einstellung effects. Our results indicate that strong reasoning models demonstrate improved flexibility in medical reasoning, achieving performance on par with humans on mARC.
Limitations of Large Language Models in Clinical Problem-Solving Arising from Inflexible Reasoning
Feb 05, 2025Large Language Models (LLMs) have attained human-level accuracy on medical question-answer (QA) benchmarks. However, their limitations in navigating open-ended clinical scenarios have recently been shown, raising concerns about the robustness and generalizability of LLM reasoning across diverse, real-world medical tasks. To probe potential LLM failure modes in clinical problem-solving, we present the medical abstraction and reasoning corpus (M-ARC). M-ARC assesses clinical reasoning through scenarios designed to exploit the Einstellung effect -- the fixation of thought arising from prior experience, targeting LLM inductive biases toward inflexible pattern matching from their training data rather than engaging in flexible reasoning. We find that LLMs, including current state-of-the-art o1 and Gemini models, perform poorly compared to physicians on M-ARC, often demonstrating lack of commonsense medical reasoning and a propensity to hallucinate. In addition, uncertainty estimation analyses indicate that LLMs exhibit overconfidence in their answers, despite their limited accuracy. The failure modes revealed by M-ARC in LLM medical reasoning underscore the need to exercise caution when deploying these models in clinical settings.
Bayesian predictive modeling of multi-source multi-way data
Aug 05, 2022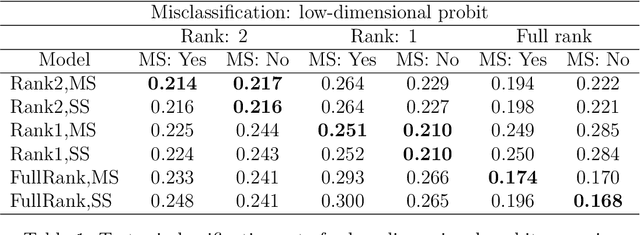
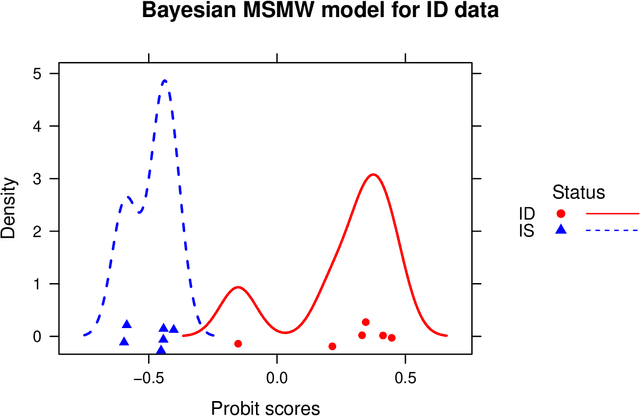
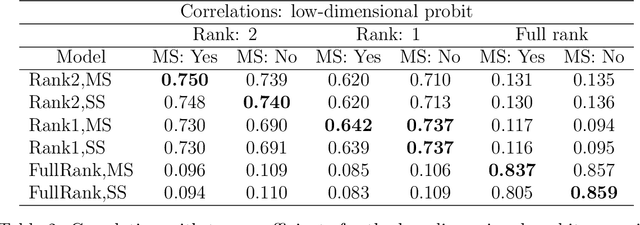
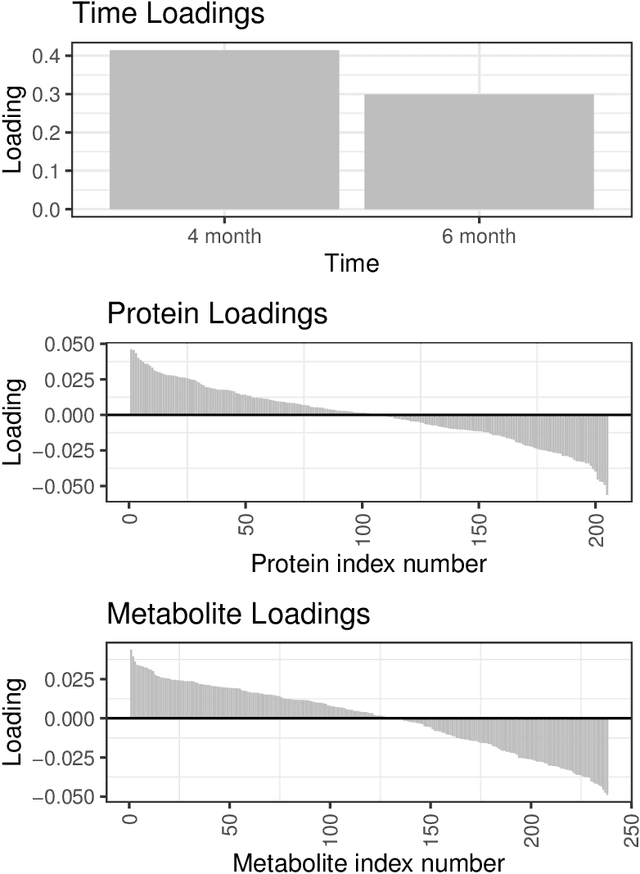
We develop a Bayesian approach to predict a continuous or binary outcome from data that are collected from multiple sources with a multi-way (i.e.. multidimensional tensor) structure. As a motivating example we consider molecular data from multiple 'omics sources, each measured over multiple developmental time points, as predictors of early-life iron deficiency (ID) in a rhesus monkey model. We use a linear model with a low-rank structure on the coefficients to capture multi-way dependence and model the variance of the coefficients separately across each source to infer their relative contributions. Conjugate priors facilitate an efficient Gibbs sampling algorithm for posterior inference, assuming a continuous outcome with normal errors or a binary outcome with a probit link. Simulations demonstrate that our model performs as expected in terms of misclassification rates and correlation of estimated coefficients with true coefficients, with large gains in performance by incorporating multi-way structure and modest gains when accounting for differing signal sizes across the different sources. Moreover, it provides robust classification of ID monkeys for our motivating application. Software in the form of R code is available at https://github.com/BiostatsKim/BayesMSMW .