 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in LLM Reasoning Enable Flexibility in Clinical Problem-Solving
Jan 17, 2026Large Language Models (LLMs) have achieved high accuracy on medical question-answer (QA) benchmarks, yet their capacity for flexible clinical reasoning has been debated. Here, we asked whether advances in reasoning LLMs improve their cognitive flexibility in clinical reasoning. We assessed reasoning models from the OpenAI, Grok, Gemini, Claude, and DeepSeek families on the medicine abstraction and reasoning corpus (mARC), an adversarial medical QA benchmark which utilizes the Einstellung effect to induce inflexible overreliance on learned heuristic patterns in contexts where they become suboptimal. We found that strong reasoning models avoided Einstellung-based traps more often than weaker reasoning models, achieving human-level performance on mARC. On questions most commonly missed by physicians, the top 5 performing models answered 55% to 70% correctly with high confidence, indicating that these models may be less susceptible than humans to Einstellung effects. Our results indicate that strong reasoning models demonstrate improved flexibility in medical reasoning, achieving performance on par with humans on mARC.
Limitations of Large Language Models in Clinical Problem-Solving Arising from Inflexible Reasoning
Feb 05, 2025Large Language Models (LLMs) have attained human-level accuracy on medical question-answer (QA) benchmarks. However, their limitations in navigating open-ended clinical scenarios have recently been shown, raising concerns about the robustness and generalizability of LLM reasoning across diverse, real-world medical tasks. To probe potential LLM failure modes in clinical problem-solving, we present the medical abstraction and reasoning corpus (M-ARC). M-ARC assesses clinical reasoning through scenarios designed to exploit the Einstellung effect -- the fixation of thought arising from prior experience, targeting LLM inductive biases toward inflexible pattern matching from their training data rather than engaging in flexible reasoning. We find that LLMs, including current state-of-the-art o1 and Gemini models, perform poorly compared to physicians on M-ARC, often demonstrating lack of commonsense medical reasoning and a propensity to hallucinate. In addition, uncertainty estimation analyses indicate that LLMs exhibit overconfidence in their answers, despite their limited accuracy. The failure modes revealed by M-ARC in LLM medical reasoning underscore the need to exercise caution when deploying these models in clinical settings.
EEG-GPT: Exploring Capabilities of Large Language Models for EEG Classification and Interpretation
Feb 03, 2024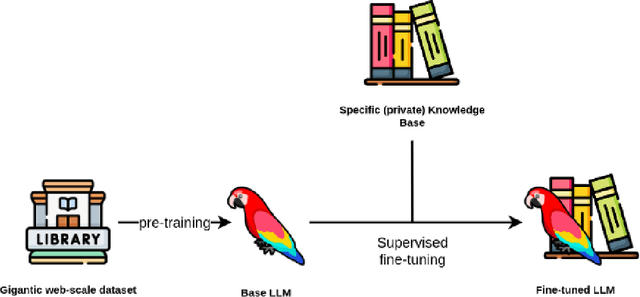

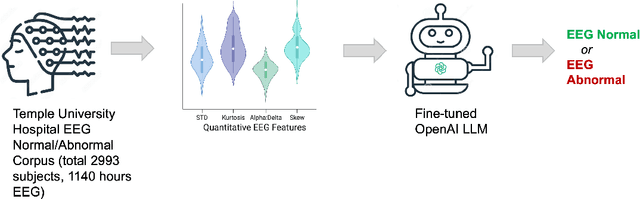

In conventional machine learning (ML) approaches applied to electroencephalography (EEG), this is often a limited focus, isolating specific brain activities occurring across disparate temporal scales (from transient spikes in milliseconds to seizures lasting minutes) and spatial scales (from localized high-frequency oscillations to global sleep activity). This siloed approach limits the development EEG ML models that exhibit multi-scale electrophysiological understanding and classification capabilities. Moreover, typical ML EEG approaches utilize black-box approaches, limiting their interpretability and trustworthiness in clinical contexts. Thus, we propose EEG-GPT, a unifying approach to EEG classification that leverages advances in large language models (LLM). EEG-GPT achieves excellent performance comparable to current state-of-the-art deep learning methods in classifying normal from abnormal EEG in a few-shot learning paradigm utilizing only 2% of training data. Furthermore, it offers the distinct advantages of providing intermediate reasoning steps and coordinating specialist EEG tools across multiple scales in its operation, offering transparent and interpretable step-by-step verification, thereby promoting trustworthiness in clinical contexts.