 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Assistance for Pediatric Depression
Jan 29, 2025



Traditional depression screening methods, such as the PHQ-9, are particularly challenging for children in pediatric primary care due to practical limitations. AI has the potential to help, but the scarcity of annotated datasets in mental health, combined with the computational costs of training, highlights the need for efficient, zero-shot approaches. In this work, we investigate the feasibility of state-of-the-art LLMs for depressive symptom extraction in pediatric settings (ages 6-24). This approach aims to complement traditional screening and minimize diagnostic errors. Our findings show that all LLMs are 60% more efficient than word match, with Flan leading in precision (average F1: 0.65, precision: 0.78), excelling in the extraction of more rare symptoms like "sleep problems" (F1: 0.92) and "self-loathing" (F1: 0.8). Phi strikes a balance between precision (0.44) and recall (0.60), performing well in categories like "Feeling depressed" (0.69) and "Weight change" (0.78). Llama 3, with the highest recall (0.90), overgeneralizes symptoms, making it less suitable for this type of analysis. Challenges include the complexity of clinical notes and overgeneralization from PHQ-9 scores. The main challenges faced by LLMs include navigating the complex structure of clinical notes with content from different times in the patient trajectory, as well as misinterpreting elevated PHQ-9 scores. We finally demonstrate the utility of symptom annotations provided by Flan as features in an ML algorithm, which differentiates depression cases from controls with high precision of 0.78, showing a major performance boost compared to a baseline that does not use these features.
A Data-Centric Approach to Detecting and Mitigating Demographic Bias in Pediatric Mental Health Text: A Case Study in Anxiety Detection
Dec 30, 2024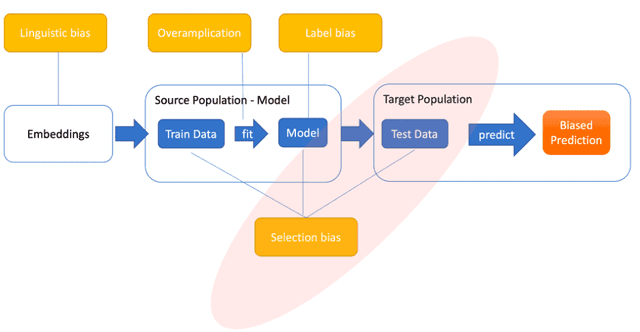
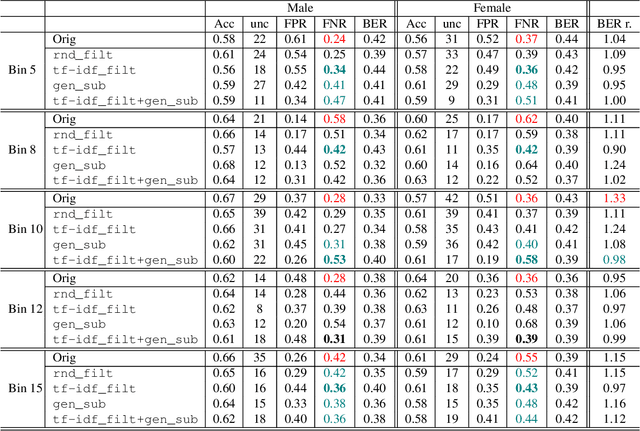
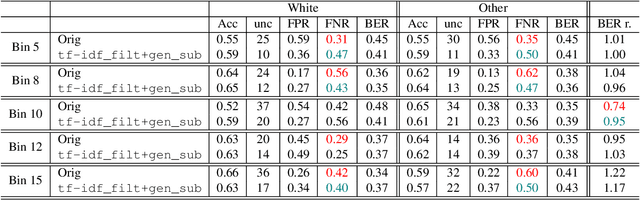
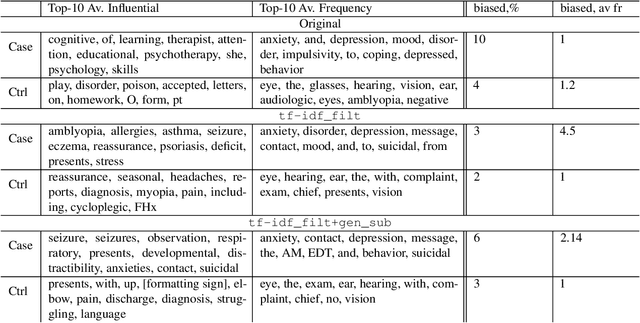
Introduction: Healthcare AI models often inherit biases from their training data. While efforts have primarily targeted bias in structured data, mental health heavily depends on unstructured data. This study aims to detect and mitigate linguistic differences related to non-biological differences in the training data of AI models designed to assist in pediatric mental health screening. Our objectives are: (1) to assess the presence of bias by evaluating outcome parity across sex subgroups, (2) to identify bias sources through textual distribution analysis, and (3) to develop a de-biasing method for mental health text data. Methods: We examined classification parity across demographic groups and assessed how gendered language influences model predictions. A data-centric de-biasing method was applied, focusing on neutralizing biased terms while retaining salient clinical information. This methodology was tested on a model for automatic anxiety detection in pediatric patients. Results: Our findings revealed a systematic under-diagnosis of female adolescent patients, with a 4% lower accuracy and a 9% higher False Negative Rate (FNR) compared to male patients, likely due to disparities in information density and linguistic differences in patient notes. Notes for male patients were on average 500 words longer, and linguistic similarity metrics indicated distinct word distributions between genders. Implementing our de-biasing approach reduced diagnostic bias by up to 27%, demonstrating its effectiveness in enhancing equity across demographic groups. Discussion: We developed a data-centric de-biasing framework to address gender-based content disparities within clinical text. By neutralizing biased language and enhancing focus on clinically essential information, our approach demonstrates an effective strategy for mitigating bias in AI healthcare models trained on text.