 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Stoplights to On-Ramps: A Comprehensive Set of Crash Rate Benchmarks for Freeway and Surface Street ADS Evaluation
Aug 26, 2025This paper presents crash rate benchmarks for evaluating US-based Automated Driving Systems (ADS) for multiple urban areas. The purpose of this study was to extend prior benchmarks focused only on surface streets to additionally capture freeway crash risk for future ADS safety performance assessments. Using publicly available police-reported crash and vehicle miles traveled (VMT) data, the methodology details the isolation of in-transport passenger vehicles, road type classification, and crash typology. Key findings revealed that freeway crash rates exhibit large geographic dependence variations with any-injury-reported crash rates being nearly 3.5 times higher in Atlanta (2.4 IPMM; the highest) when compared to Phoenix (0.7 IPMM; the lowest). The results show the critical need for location-specific benchmarks to avoid biased safety evaluations and provide insights into the vehicle miles traveled (VMT) required to achieve statistical significance for various safety impact levels. The distribution of crash types depended on the outcome severity level. Higher severity outcomes (e.g., fatal crashes) had a larger proportion of single-vehicle, vulnerable road users (VRU), and opposite-direction collisions compared to lower severity (police-reported) crashes. Given heterogeneity in crash types by severity, performance in low-severity scenarios may not be predictive of high-severity outcomes. These benchmarks are additionally used to quantify at the required mileage to show statistically significant deviations from human performance. This is the first paper to generate freeway-specific benchmarks for ADS evaluation and provides a foundational framework for future ADS benchmarking by evaluators and developers.
Comparison of Waymo Rider-Only Crash Rates by Crash Type to Human Benchmarks at 56.7 Million Miles
May 02, 2025SAE Level 4 Automated Driving Systems (ADSs) are deployed on public roads, including Waymo's Rider-Only (RO) ride-hailing service (without a driver behind the steering wheel). The objective of this study was to perform a retrospective safety assessment of Waymo's RO crash rate compared to human benchmarks, including disaggregated by crash type. Eleven crash type groups were identified from commonly relied upon crash typologies that are derived from human crash databases. Human benchmarks were aligned to the same vehicle types, road types, and locations as where the Waymo Driver operated. Waymo crashes were extracted from the NHTSA Standing General Order (SGO). RO mileage was provided by the company via a public website. Any-injury-reported, Airbag Deployment, and Suspected Serious Injury+ crash outcomes were examined because they represented previously established, safety-relevant benchmarks where statistical testing could be performed at the current mileage. Data was examined over 56.7 million RO miles through the end of January 2025, resulting in a statistically significant lower crashed vehicle rate for all crashes compared to the benchmarks in Any-Injury-Reported and Airbag Deployment, and Suspected Serious Injury+ crashes. Of the crash types, V2V Intersection crash events represented the largest total crash reduction, with a 96% reduction in Any-injury-reported (87%-99% CI) and a 91% reduction in Airbag Deployment (76%-98% CI) events. Cyclist, Motorcycle, Pedestrian, Secondary Crash, and Single Vehicle crashes were also statistically reduced for the Any-Injury-Reported outcome. There was no statistically significant disbenefit found in any of the 11 crash type groups. This study represents the first retrospective safety assessment of an RO ADS that made statistical conclusions about more serious crash outcomes and analyzed crash rates on a crash type basis.
Dynamic Benchmarks: Spatial and Temporal Alignment for ADS Performance Evaluation
Oct 11, 2024
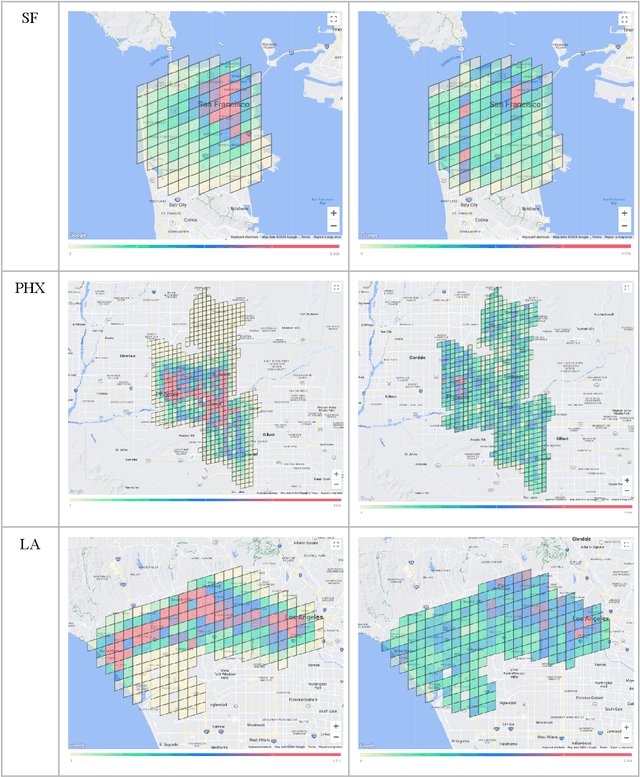
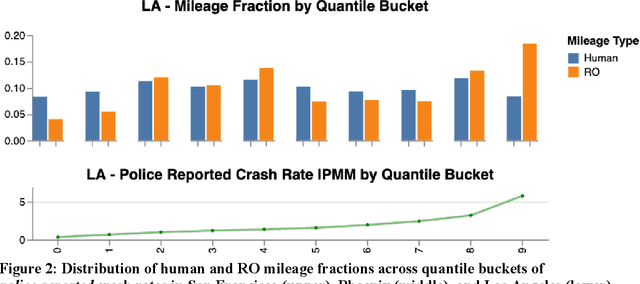
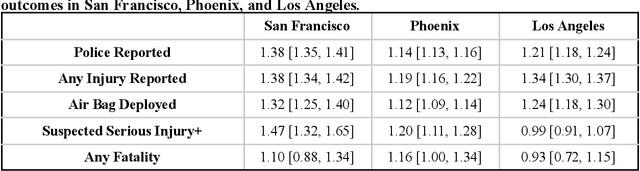
Deployed SAE level 4+ Automated Driving Systems (ADS) without a human driver are currently operational ride-hailing fleets on surface streets in the United States. This current use case and future applications of this technology will determine where and when the fleets operate, potentially resulting in a divergence from the distribution of driving of some human benchmark population within a given locality. Existing benchmarks for evaluating ADS performance have only done county-level geographical matching of the ADS and benchmark driving exposure in crash rates. This study presents a novel methodology for constructing dynamic human benchmarks that adjust for spatial and temporal variations in driving distribution between an ADS and the overall human driven fleet. Dynamic benchmarks were generated using human police-reported crash data, human vehicle miles traveled (VMT) data, and over 20 million miles of Waymo's rider-only (RO) operational data accumulated across three US counties. The spatial adjustment revealed significant differences across various severity levels in adjusted crash rates compared to unadjusted benchmarks with these differences ranging from 10% to 47% higher in San Francisco, 12% to 20% higher in Maricopa, and 7% lower to 34% higher in Los Angeles counties. The time-of-day adjustment in San Francisco, limited to this region due to data availability, resulted in adjusted crash rates 2% lower to 16% higher than unadjusted rates, depending on severity level. The findings underscore the importance of adjusting for spatial and temporal confounders in benchmarking analysis, which ultimately contributes to a more equitable benchmark for ADS performance evaluations.
RAVE Checklist: Recommendations for Overcoming Challenges in Retrospective Safety Studies of Automated Driving Systems
Aug 14, 2024



The public, regulators, and domain experts alike seek to understand the effect of deployed SAE level 4 automated driving system (ADS) technologies on safety. The recent expansion of ADS technology deployments is paving the way for early stage safety impact evaluations, whereby the observational data from both an ADS and a representative benchmark fleet are compared to quantify safety performance. In January 2024, a working group of experts across academia, insurance, and industry came together in Washington, DC to discuss the current and future challenges in performing such evaluations. A subset of this working group then met, virtually, on multiple occasions to produce this paper. This paper presents the RAVE (Retrospective Automated Vehicle Evaluation) checklist, a set of fifteen recommendations for performing and evaluating retrospective ADS performance comparisons. The recommendations are centered around the concepts of (1) quality and validity, (2) transparency, and (3) interpretation. Over time, it is anticipated there will be a large and varied body of work evaluating the observed performance of these ADS fleets. Establishing and promoting good scientific practices benefits the work of stakeholders, many of whom may not be subject matter experts. This working group's intentions are to: i) strengthen individual research studies and ii) make the at-large community more informed on how to evaluate this collective body of work.
Benchmarks for Retrospective Automated Driving System Crash Rate Analysis Using Police-Reported Crash Data
Dec 20, 2023With fully automated driving systems (ADS; SAE level 4) ride-hailing services expanding in the US, we are now approaching an inflection point, where the process of retrospectively evaluating ADS safety impact can start to yield statistically credible conclusions. An ADS safety impact measurement requires a comparison to a "benchmark" crash rate. This study aims to address, update, and extend the existing literature by leveraging police-reported crashes to generate human crash rates for multiple geographic areas with current ADS deployments. All of the data leveraged is publicly accessible, and the benchmark determination methodology is intended to be repeatable and transparent. Generating a benchmark that is comparable to ADS crash data is associated with certain challenges, including data selection, handling underreporting and reporting thresholds, identifying the population of drivers and vehicles to compare against, choosing an appropriate severity level to assess, and matching crash and mileage exposure data. Consequently, we identify essential steps when generating benchmarks, and present our analyses amongst a backdrop of existing ADS benchmark literature. One analysis presented is the usage of established underreporting correction methodology to publicly available human driver police-reported data to improve comparability to publicly available ADS crash data. We also identify important dependencies in controlling for geographic region, road type, and vehicle type, and show how failing to control for these features can bias results. This body of work aims to contribute to the ability of the community - researchers, regulators, industry, and experts - to reach consensus on how to estimate accurate benchmarks.
Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles
Dec 20, 2023This paper examines the safety performance of the Waymo Driver, an SAE level 4 automated driving system (ADS) used in a rider-only (RO) ride-hailing application without a human driver, either in the vehicle or remotely. ADS crash data was derived from NHTSA's Standing General Order (SGO) reporting over 7.14 million RO miles through the end of October 2023 in Phoenix, AZ, San Francisco, CA, and Los Angeles, CA. This study is one of the first to compare overall crashed vehicle rates using only RO data (as opposed to ADS testing with a human behind the wheel) to a human benchmark that also corrects for biases caused by underreporting and unequal reporting thresholds reported in the literature. When considering all locations together, the any-injury-reported crashed vehicle rate was 0.41 incidents per million miles (IPMM) for the ADS vs 2.78 IPMM for the human benchmark, an 85% reduction or a 6.8 times lower rate. Police-reported crashed vehicle rates for all locations together were 2.1 IPMM for the ADS vs. 4.85 IPMM for the human benchmark, a 57% reduction or 2.3 times lower rate. Police-reported and any-injury-reported crashed vehicle rate reductions for the ADS were statistically significant when compared in San Francisco and Phoenix as well as combined across all locations. The comparison in Los Angeles, which to date has low mileage and no reported events, was not statistically significant. In general, the Waymo ADS had a lower any property damage or injury rate than the human benchmarks. Given imprecision in the benchmark estimate and multiple potential sources of underreporting biasing the benchmarks, caution should be taken when interpreting the results of the any property damage or injury comparison. Together, these crash-rate results should be interpreted as a directional and continuous confidence growth indicator, together with other methodologies, in a safety case approach.