 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn AI-enabled tool for quantifying overlapping red blood cell sickling dynamics in microfluidic assays
Jan 25, 2026Understanding sickle cell dynamics requires accurate identification of morphological transitions under diverse biophysical conditions, particularly in densely packed and overlapping cell populations. Here, we present an automated deep learning framework that integrates AI-assisted annotation, segmentation, classification, and instance counting to quantify red blood cell (RBC) populations across varying density regimes in time-lapse microscopy data. Experimental images were annotated using the Roboflow platform to generate labeled dataset for training an nnU-Net segmentation model. The trained network enables prediction of the temporal evolution of the sickle cell fraction, while a watershed algorithm resolves overlapping cells to enhance quantification accuracy. Despite requiring only a limited amount of labeled data for training, the framework achieves high segmentation performance, effectively addressing challenges associated with scarce manual annotations and cell overlap. By quantitatively tracking dynamic changes in RBC morphology, this approach can more than double the experimental throughput via densely packed cell suspensions, capture drug-dependent sickling behavior, and reveal distinct mechanobiological signatures of cellular morphological evolution. Overall, this AI-driven framework establishes a scalable and reproducible computational platform for investigating cellular biomechanics and assessing therapeutic efficacy in microphysiological systems.
Set Norm and Equivariant Skip Connections: Putting the Deep in Deep Sets
Jun 23, 2022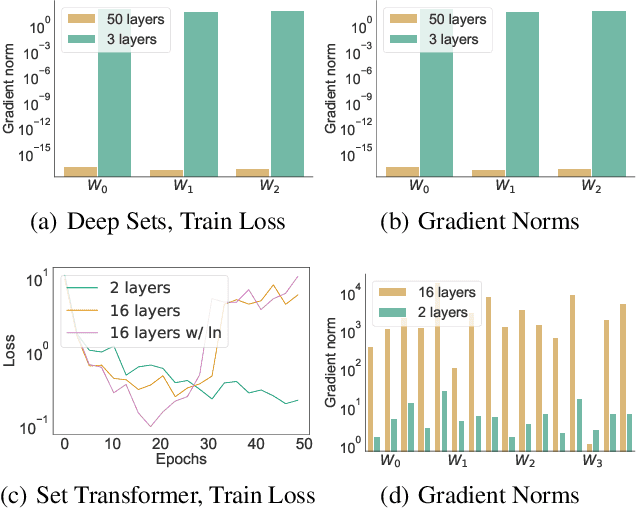
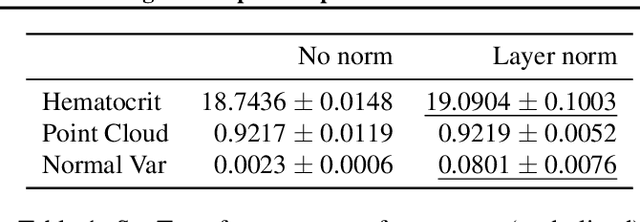
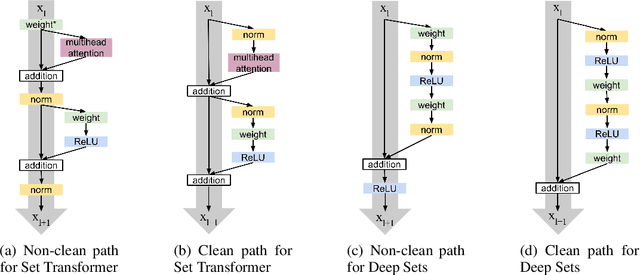
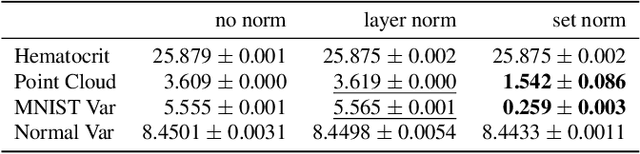
Permutation invariant neural networks are a promising tool for making predictions from sets. However, we show that existing permutation invariant architectures, Deep Sets and Set Transformer, can suffer from vanishing or exploding gradients when they are deep. Additionally, layer norm, the normalization of choice in Set Transformer, can hurt performance by removing information useful for prediction. To address these issues, we introduce the clean path principle for equivariant residual connections and develop set norm, a normalization tailored for sets. With these, we build Deep Sets++ and Set Transformer++, models that reach high depths with comparable or better performance than their original counterparts on a diverse suite of tasks. We additionally introduce Flow-RBC, a new single-cell dataset and real-world application of permutation invariant prediction. We open-source our data and code here: https://github.com/rajesh-lab/deep_permutation_invariant.