 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravity Falls: A Comparative Analysis of Domain-Generation Algorithm (DGA) Detection Methods for Mobile Device Spearphishing
Mar 03, 2026Mobile devices are frequent targets of eCrime threat actors through SMS spearphishing (smishing) links that leverage Domain Generation Algorithms (DGA) to rotate hostile infrastructure. Despite this, DGA research and evaluation largely emphasize malware C2 and email phishing datasets, leaving limited evidence on how well detectors generalize to smishing-driven domain tactics outside enterprise perimeters. This work addresses that gap by evaluating traditional and machine-learning DGA detectors against Gravity Falls, a new semi-synthetic dataset derived from smishing links delivered between 2022 and 2025. Gravity Falls captures a single threat actor's evolution across four technique clusters, shifting from short randomized strings to dictionary concatenation and themed combo-squatting variants used for credential theft and fee/fine fraud. Two string-analysis approaches (Shannon entropy and Exp0se) and two ML-based detectors (an LSTM classifier and COSSAS DGAD) are assessed using Top-1M domains as benign baselines. Results are strongly tactic-dependent: performance is highest on randomized-string domains but drops on dictionary concatenation and themed combo-squatting, with low recall across multiple tool/cluster pairings. Overall, both traditional heuristics and recent ML detectors are ill-suited for consistently evolving DGA tactics observed in Gravity Falls, motivating more context-aware approaches and providing a reproducible benchmark for future evaluation.
Unsupervised Baseline Clustering and Incremental Adaptation for IoT Device Traffic Profiling
Feb 27, 2026The growth and heterogeneity of IoT devices create security challenges where static identification models can degrade as traffic evolves. This paper presents a two-stage, flow-feature-based pipeline for unsupervised IoT device traffic profiling and incremental model updating, evaluated on selected long-duration captures from the Deakin IoT dataset. For baseline profiling, density-based clustering (DBSCAN) isolates a substantial outlier portion of the data and produces the strongest alignment with ground-truth device labels among tested classical methods (NMI 0.78), outperforming centroid-based clustering on cluster purity. For incremental adaptation, we evaluate stream-oriented clustering approaches and find that BIRCH supports efficient updates (0.13 seconds per update) and forms comparatively coherent clusters for a held-out novel device (purity 0.87), but with limited capture of novel traffic (share 0.72) and a measurable trade-off in known-device accuracy after adaptation (0.71). Overall, the results highlight a practical trade-off between high-purity static profiling and the flexibility of incremental clustering for evolving IoT environments.
Quantifying Return on Security Controls in LLM Systems
Dec 17, 2025Although large language models (LLMs) are increasingly used in security-critical workflows, practitioners lack quantitative guidance on which safeguards are worth deploying. This paper introduces a decision-oriented framework and reproducible methodology that together quantify residual risk, convert adversarial probe outcomes into financial risk estimates and return-on-control (RoC) metrics, and enable monetary comparison of layered defenses for LLM-based systems. A retrieval-augmented generation (RAG) service is instantiated using the DeepSeek-R1 model over a corpus containing synthetic personally identifiable information (PII), and subjected to automated attacks with Garak across five vulnerability classes: PII leakage, latent context injection, prompt injection, adversarial attack generation, and divergence. For each (vulnerability, control) pair, attack success probabilities are estimated via Laplace's Rule of Succession and combined with loss triangle distributions, calibrated from public breach-cost data, in 10,000-run Monte Carlo simulations to produce loss exceedance curves and expected losses. Three widely used mitigations, attribute-based access control (ABAC); named entity recognition (NER) redaction using Microsoft Presidio; and NeMo Guardrails, are then compared to a baseline RAG configuration. The baseline system exhibits very high attack success rates (>= 0.98 for PII, latent injection, and prompt injection), yielding a total simulated expected loss of $313k per attack scenario. ABAC collapses success probabilities for PII and prompt-related attacks to near zero and reduces the total expected loss by ~94%, achieving an RoC of 9.83. NER redaction likewise eliminates PII leakage and attains an RoC of 5.97, while NeMo Guardrails provides only marginal benefit (RoC of 0.05).
An Ethically Grounded LLM-Based Approach to Insider Threat Synthesis and Detection
Sep 08, 2025



Insider threats are a growing organizational problem due to the complexity of identifying their technical and behavioral elements. A large research body is dedicated to the study of insider threats from technological, psychological, and educational perspectives. However, research in this domain has been generally dependent on datasets that are static and limited access which restricts the development of adaptive detection models. This study introduces a novel, ethically grounded approach that uses the large language model (LLM) Claude Sonnet 3.7 to dynamically synthesize syslog messages, some of which contain indicators of insider threat scenarios. The messages reflect real-world data distributions by being highly imbalanced (1% insider threats). The syslogs were analyzed for insider threats by both Claude Sonnet 3.7 and GPT-4o, with their performance evaluated through statistical metrics including precision, recall, MCC, and ROC AUC. Sonnet 3.7 consistently outperformed GPT-4o across nearly all metrics, particularly in reducing false alarms and improving detection accuracy. The results show strong promise for the use of LLMs in synthetic dataset generation and insider threat detection.
Scalable and Ethical Insider Threat Detection through Data Synthesis and Analysis by LLMs
Feb 10, 2025



Insider threats wield an outsized influence on organizations, disproportionate to their small numbers. This is due to the internal access insiders have to systems, information, and infrastructure. %One example of this influence is where anonymous respondents submit web-based job search site reviews, an insider threat risk to organizations. Signals for such risks may be found in anonymous submissions to public web-based job search site reviews. This research studies the potential for large language models (LLMs) to analyze and detect insider threat sentiment within job site reviews. Addressing ethical data collection concerns, this research utilizes synthetic data generation using LLMs alongside existing job review datasets. A comparative analysis of sentiment scores generated by LLMs is benchmarked against expert human scoring. Findings reveal that LLMs demonstrate alignment with human evaluations in most cases, thus effectively identifying nuanced indicators of threat sentiment. The performance is lower on human-generated data than synthetic data, suggesting areas for improvement in evaluating real-world data. Text diversity analysis found differences between human-generated and LLM-generated datasets, with synthetic data exhibiting somewhat lower diversity. Overall, the results demonstrate the applicability of LLMs to insider threat detection, and a scalable solution for insider sentiment testing by overcoming ethical and logistical barriers tied to data acquisition.
Toward an Insider Threat Education Platform: A Theoretical Literature Review
Dec 18, 2024Insider threats (InTs) within organizations are small in number but have a disproportionate ability to damage systems, information, and infrastructure. Existing InT research studies the problem from psychological, technical, and educational perspectives. Proposed theories include research on psychological indicators, machine learning, user behavioral log analysis, and educational methods to teach employees recognition and mitigation techniques. Because InTs are a human problem, training methods that address InT detection from a behavioral perspective are critical. While numerous technological and psychological theories exist on detection, prevention, and mitigation, few training methods prioritize psychological indicators. This literature review studied peer-reviewed, InT research organized by subtopic and extracted critical theories from psychological, technical, and educational disciplines. In doing so, this is the first study to comprehensively organize research across all three approaches in a manner which properly informs the development of an InT education platform.
Impact of Data Snooping on Deep Learning Models for Locating Vulnerabilities in Lifted Code
Dec 03, 2024
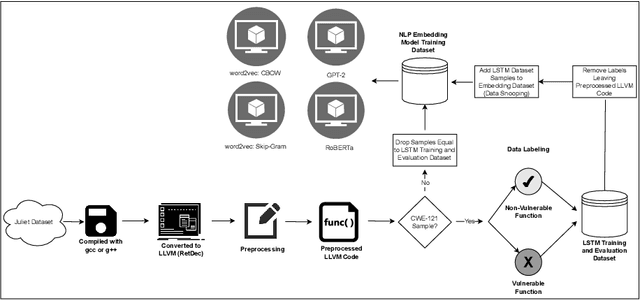
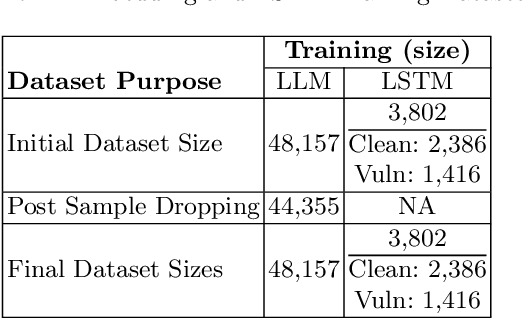
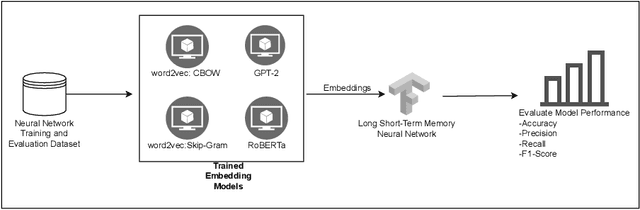
This study examines the impact of data snooping on neural networks for vulnerability detection in lifted code, building on previous research which used word2vec, and unidirectional and bidirectional transformer-based embeddings. The research specifically focuses on how model performance is affected when embedding models are trained on datasets, including samples also used for neural network training and validation. The results show that introducing data snooping did not significantly alter model performance, suggesting that data snooping had a minimal impact or that samples randomly dropped as part of the methodology contained hidden features critical to achieving optimal performance. In addition, the findings reinforce the conclusions of previous research, which found that models trained with GPT-2 embeddings consistently outperformed neural networks trained with other embeddings. The fact that this holds even when data snooping is introduced into the embedding model indicates GPT-2's robustness in representing complex code features, even under less-than-ideal conditions.
Utilizing Large Language Models to Synthesize Product Desirability Datasets
Nov 20, 2024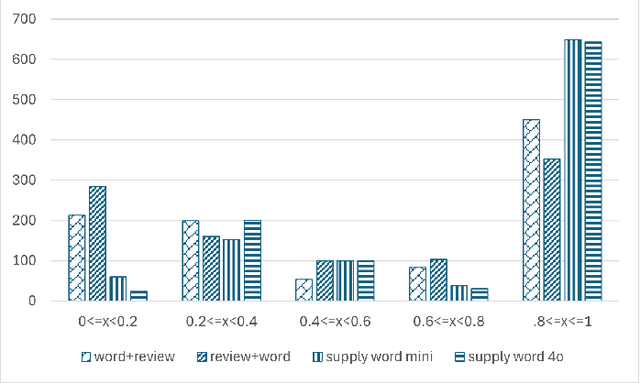
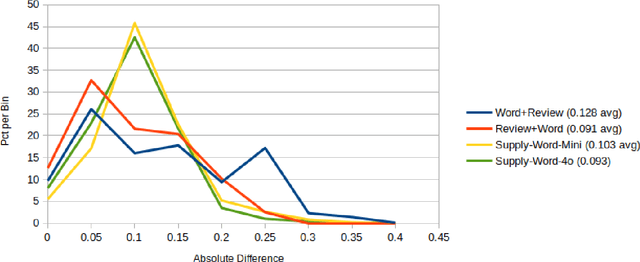
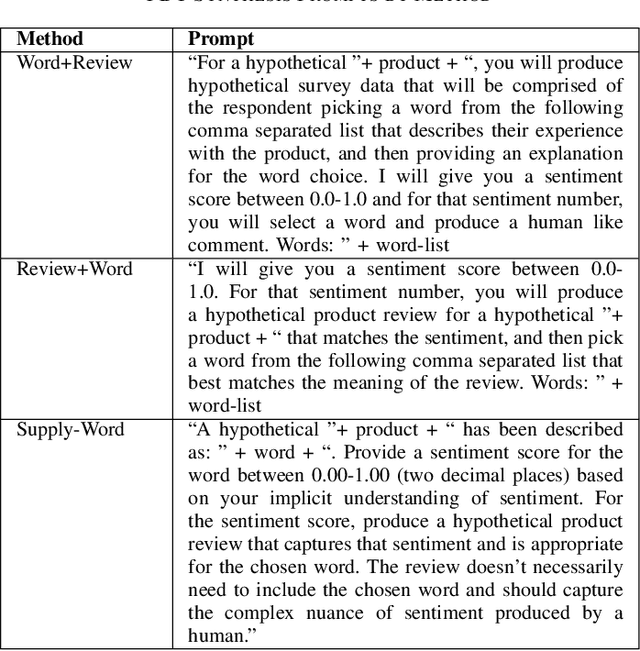
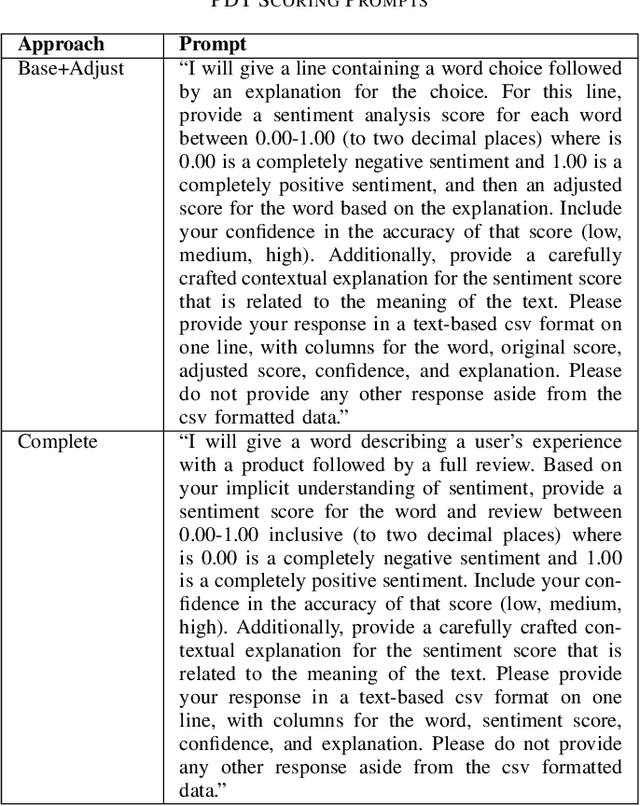
This research explores the application of large language models (LLMs) to generate synthetic datasets for Product Desirability Toolkit (PDT) testing, a key component in evaluating user sentiment and product experience. Utilizing gpt-4o-mini, a cost-effective alternative to larger commercial LLMs, three methods, Word+Review, Review+Word, and Supply-Word, were each used to synthesize 1000 product reviews. The generated datasets were assessed for sentiment alignment, textual diversity, and data generation cost. Results demonstrated high sentiment alignment across all methods, with Pearson correlations ranging from 0.93 to 0.97. Supply-Word exhibited the highest diversity and coverage of PDT terms, although with increased generation costs. Despite minor biases toward positive sentiments, in situations with limited test data, LLM-generated synthetic data offers significant advantages, including scalability, cost savings, and flexibility in dataset production.
Comparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code
Sep 26, 2024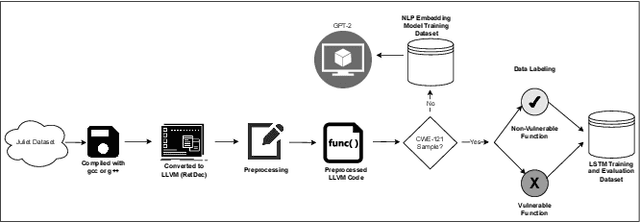
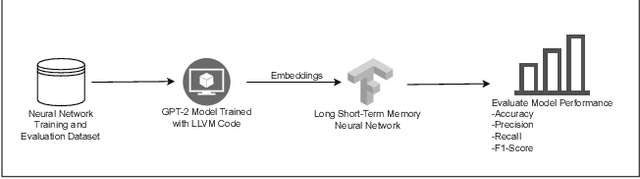
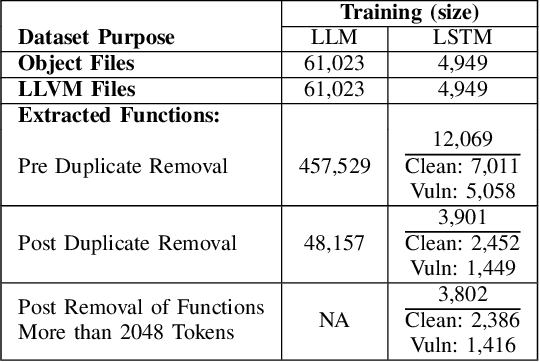
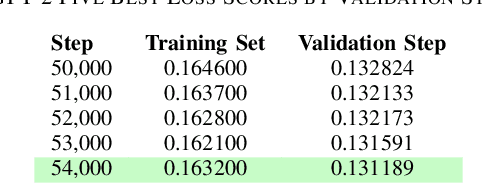
Ransomware and other forms of malware cause significant financial and operational damage to organizations by exploiting long-standing and often difficult-to-detect software vulnerabilities. To detect vulnerabilities such as buffer overflows in compiled code, this research investigates the application of unidirectional transformer-based embeddings, specifically GPT-2. Using a dataset of LLVM functions, we trained a GPT-2 model to generate embeddings, which were subsequently used to build LSTM neural networks to differentiate between vulnerable and non-vulnerable code. Our study reveals that embeddings from the GPT-2 model significantly outperform those from bidirectional models of BERT and RoBERTa, achieving an accuracy of 92.5% and an F1-score of 89.7%. LSTM neural networks were developed with both frozen and unfrozen embedding model layers. The model with the highest performance was achieved when the embedding layers were unfrozen. Further, the research finds that, in exploring the impact of different optimizers within this domain, the SGD optimizer demonstrates superior performance over Adam. Overall, these findings reveal important insights into the potential of unidirectional transformer-based approaches in enhancing cybersecurity defenses.
The Psychological Impacts of Algorithmic and AI-Driven Social Media on Teenagers: A Call to Action
Aug 19, 2024

This study investigates the meta-issues surrounding social media, which, while theoretically designed to enhance social interactions and improve our social lives by facilitating the sharing of personal experiences and life events, often results in adverse psychological impacts. Our investigation reveals a paradoxical outcome: rather than fostering closer relationships and improving social lives, the algorithms and structures that underlie social media platforms inadvertently contribute to a profound psychological impact on individuals, influencing them in unforeseen ways. This phenomenon is particularly pronounced among teenagers, who are disproportionately affected by curated online personas, peer pressure to present a perfect digital image, and the constant bombardment of notifications and updates that characterize their social media experience. As such, we issue a call to action for policymakers, platform developers, and educators to prioritize the well-being of teenagers in the digital age and work towards creating secure and safe social media platforms that protect the young from harm, online harassment, and exploitation.