 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Large Language Models to Synthesize Product Desirability Datasets
Nov 20, 2024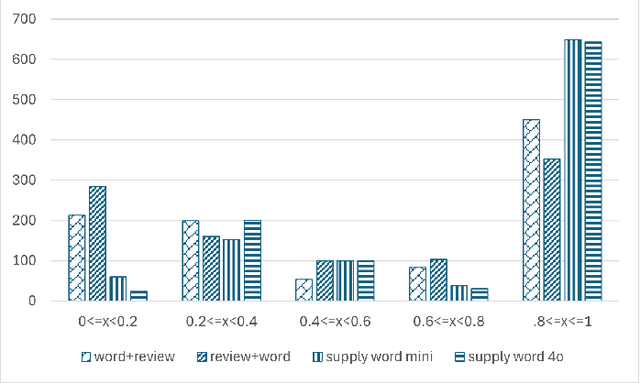
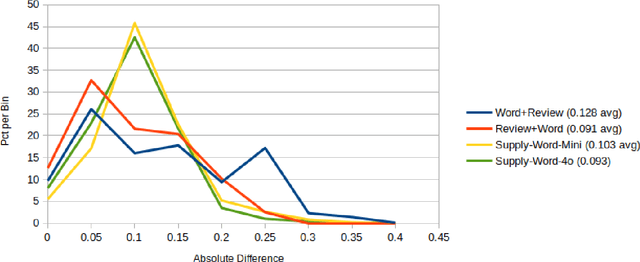
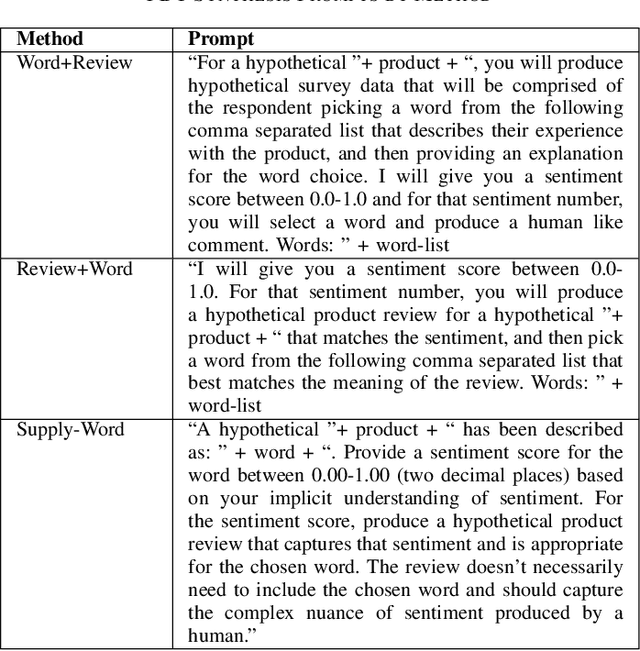
This research explores the application of large language models (LLMs) to generate synthetic datasets for Product Desirability Toolkit (PDT) testing, a key component in evaluating user sentiment and product experience. Utilizing gpt-4o-mini, a cost-effective alternative to larger commercial LLMs, three methods, Word+Review, Review+Word, and Supply-Word, were each used to synthesize 1000 product reviews. The generated datasets were assessed for sentiment alignment, textual diversity, and data generation cost. Results demonstrated high sentiment alignment across all methods, with Pearson correlations ranging from 0.93 to 0.97. Supply-Word exhibited the highest diversity and coverage of PDT terms, although with increased generation costs. Despite minor biases toward positive sentiments, in situations with limited test data, LLM-generated synthetic data offers significant advantages, including scalability, cost savings, and flexibility in dataset production.
Analyzing LLMs' Capabilities to Establish Implicit User Sentiment of Software Desirability
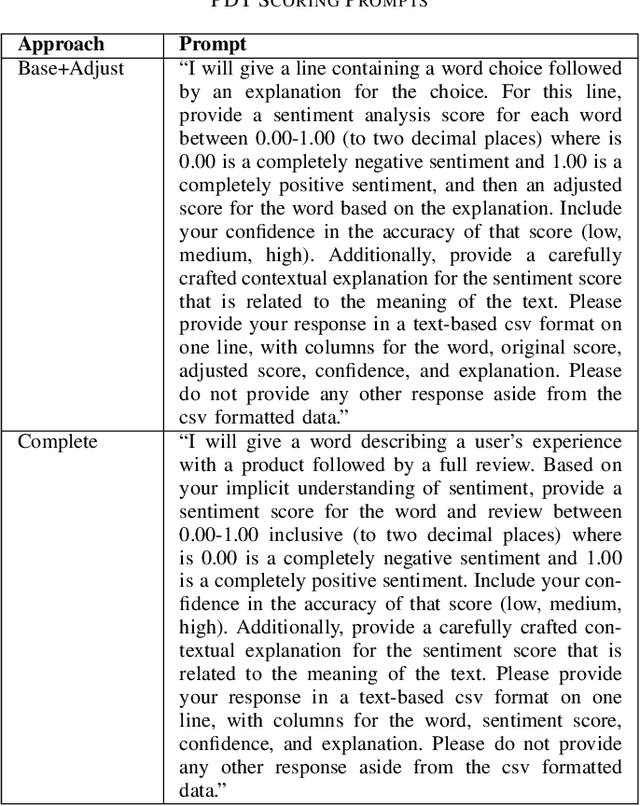
Aug 02, 2024This study explores the use of several LLMs for providing quantitative zero-shot sentiment analysis of implicit software desirability expressed by users. The study provides scaled numerical sentiment analysis unlike other methods that simply classify sentiment as positive, neutral, or negative. Numerical analysis provides deeper insights into the magnitude of sentiment, to drive better decisions regarding product desirability. Data is collected through the use of the Microsoft Product Desirability Toolkit (PDT), a well-known qualitative user experience analysis tool. For initial exploration, the PDT metric was given to users of ZORQ, a gamification system used in undergraduate computer science education. The PDT data collected was fed through several LLMs (Claude Sonnet 3 and 3.5, GPT4, and GPT4o) and through a leading transfer learning technique, Twitter-Roberta-Base-Sentiment (TRBS), and through Vader, a leading sentiment analysis tool, for quantitative sentiment analysis. Each system was asked to evaluate the data in two ways, first by looking at the sentiment expressed in the PDT word/explanation pairs; and by looking at the sentiment expressed by the users in their grouped selection of five words and explanations, as a whole. Each LLM was also asked to provide its confidence (low, medium, high) in its sentiment score, along with an explanation of why it selected the sentiment value. All LLMs tested were able to statistically detect user sentiment from the users' grouped data, whereas TRBS and Vader were not. The confidence and explanation of confidence provided by the LLMs assisted in understanding the user sentiment. This study adds to a deeper understanding of evaluating user experiences, toward the goal of creating a universal tool that quantifies implicit sentiment expressed.