 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code
Sep 26, 2024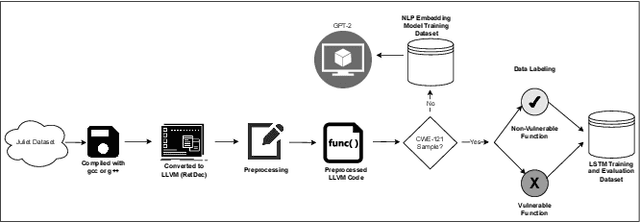
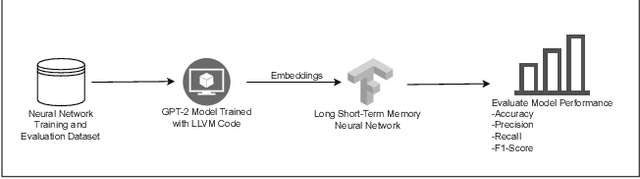
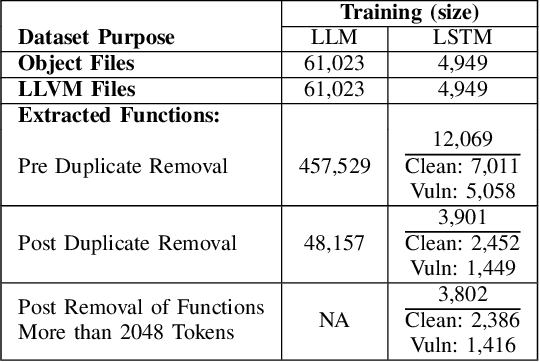
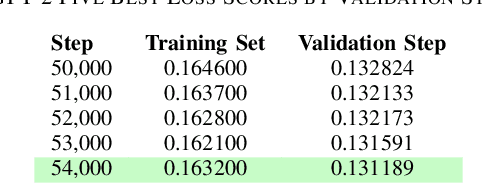
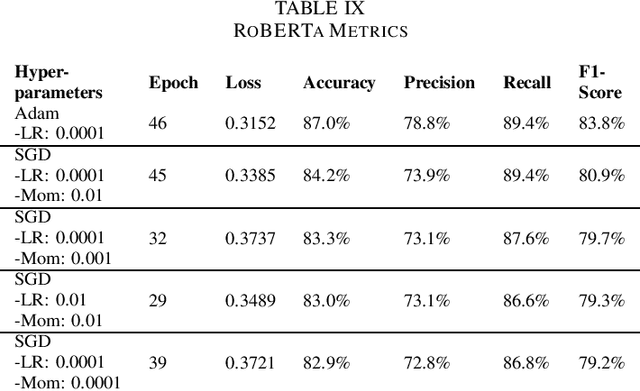
Ransomware and other forms of malware cause significant financial and operational damage to organizations by exploiting long-standing and often difficult-to-detect software vulnerabilities. To detect vulnerabilities such as buffer overflows in compiled code, this research investigates the application of unidirectional transformer-based embeddings, specifically GPT-2. Using a dataset of LLVM functions, we trained a GPT-2 model to generate embeddings, which were subsequently used to build LSTM neural networks to differentiate between vulnerable and non-vulnerable code. Our study reveals that embeddings from the GPT-2 model significantly outperform those from bidirectional models of BERT and RoBERTa, achieving an accuracy of 92.5% and an F1-score of 89.7%. LSTM neural networks were developed with both frozen and unfrozen embedding model layers. The model with the highest performance was achieved when the embedding layers were unfrozen. Further, the research finds that, in exploring the impact of different optimizers within this domain, the SGD optimizer demonstrates superior performance over Adam. Overall, these findings reveal important insights into the potential of unidirectional transformer-based approaches in enhancing cybersecurity defenses.
Bi-Directional Transformers vs. word2vec: Discovering Vulnerabilities in Lifted Compiled Code
May 31, 2024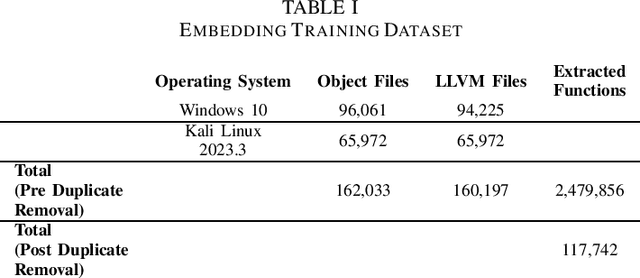
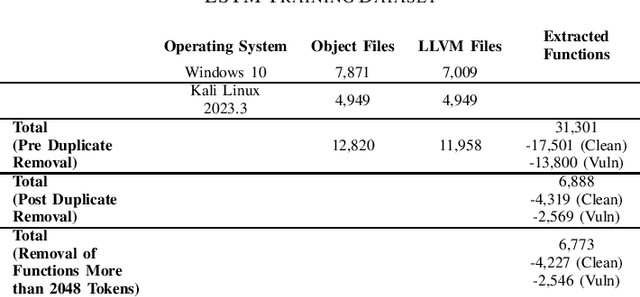
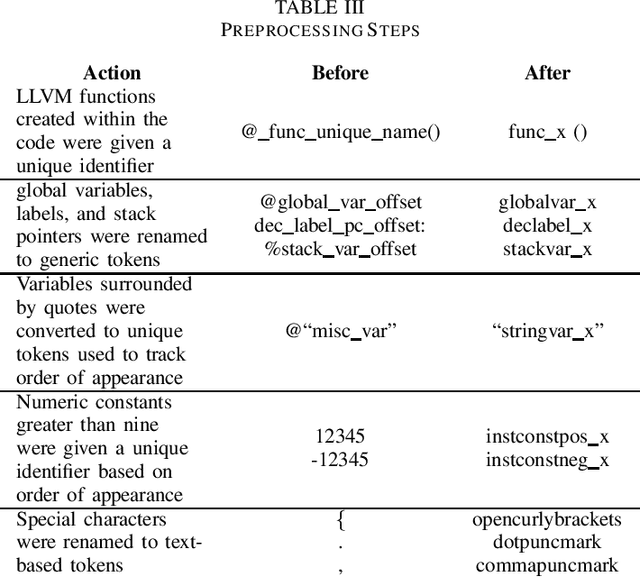
Detecting vulnerabilities within compiled binaries is challenging due to lost high-level code structures and other factors such as architectural dependencies, compilers, and optimization options. To address these obstacles, this research explores vulnerability detection by using natural language processing (NLP) embedding techniques with word2vec, BERT, and RoBERTa to learn semantics from intermediate representation (LLVM) code. Long short-term memory (LSTM) neural networks were trained on embeddings from encoders created using approximately 118k LLVM functions from the Juliet dataset. This study is pioneering in its comparison of word2vec models with multiple bidirectional transformer (BERT, RoBERTa) embeddings built using LLVM code to train neural networks to detect vulnerabilities in compiled binaries. word2vec Continuous Bag of Words (CBOW) models achieved 92.3% validation accuracy in detecting vulnerabilities, outperforming word2vec Skip-Gram, BERT, and RoBERTa. This suggests that complex contextual NLP embeddings may not provide advantages over simpler word2vec models for this task when a limited number (e.g. 118K) of data samples are used to train the bidirectional transformer-based models. The comparative results provide novel insights into selecting optimal embeddings for learning compiler-independent semantic code representations to advance machine learning detection of vulnerabilities in compiled binaries.