 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Masks: A New Framework for Shortcut Mitigation in NLU
Oct 28, 2022


Debiasing language models from unwanted behaviors in Natural Language Understanding tasks is a topic with rapidly increasing interest in the NLP community. Spurious statistical correlations in the data allow models to perform shortcuts and avoid uncovering more advanced and desirable linguistic features. A multitude of effective debiasing approaches has been proposed, but flexibility remains a major issue. For the most part, models must be retrained to find a new set of weights with debiased behavior. We propose a new debiasing method in which we identify debiased pruning masks that can be applied to a finetuned model. This enables the selective and conditional application of debiasing behaviors. We assume that bias is caused by a certain subset of weights in the network; our method is, in essence, a mask search to identify and remove biased weights. Our masks show equivalent or superior performance to the standard counterparts, while offering important benefits. Pruning masks can be stored with high efficiency in memory, and it becomes possible to switch among several debiasing behaviors (or revert back to the original biased model) at inference time. Finally, it opens the doors to further research on how biases are acquired by studying the generated masks. For example, we observed that the early layers and attention heads were pruned more aggressively, possibly hinting towards the location in which biases may be encoded.
A Survey on Measuring and Mitigating Reasoning Shortcuts in Machine Reading Comprehension
Sep 05, 2022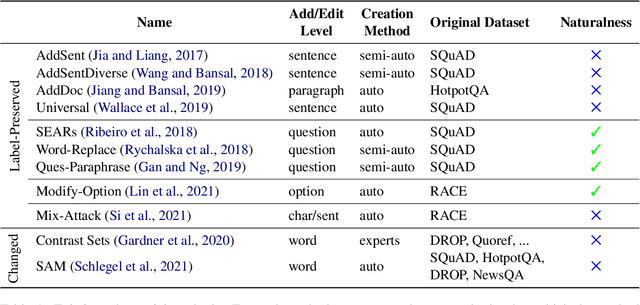

The issue of shortcut learning is widely known in NLP and has been an important research focus in recent years. Unintended correlations in the data enable models to easily solve tasks that were meant to exhibit advanced language understanding and reasoning capabilities. In this survey paper, we focus on the field of machine reading comprehension (MRC), an important task for showcasing high-level language understanding that also suffers from a range of shortcuts. We summarize the available techniques for measuring and mitigating shortcuts and conclude with suggestions for further progress in shortcut research. Most importantly, we highlight two main concerns for shortcut mitigation in MRC: the lack of public challenge sets, a necessary component for effective and reusable evaluation, and the lack of certain mitigation techniques that are prominent in other areas.
Embracing Ambiguity: Shifting the Training Target of NLI Models
Jun 06, 2021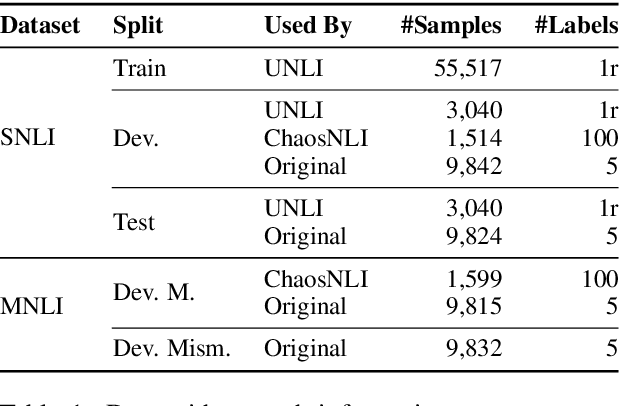
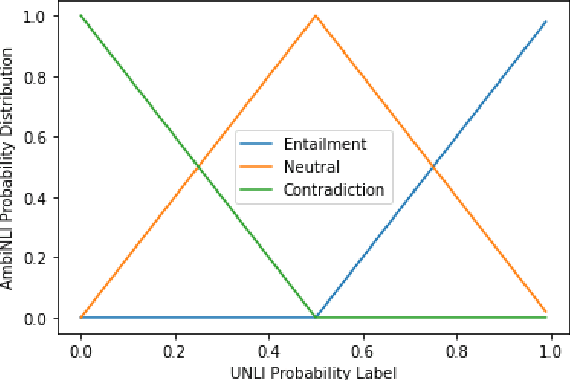
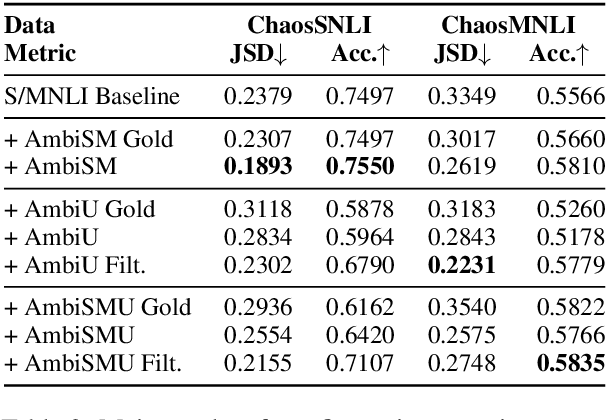
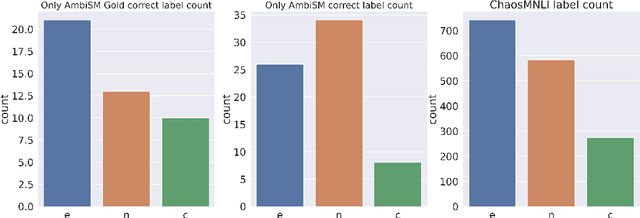
Natural Language Inference (NLI) datasets contain examples with highly ambiguous labels. While many research works do not pay much attention to this fact, several recent efforts have been made to acknowledge and embrace the existence of ambiguity, such as UNLI and ChaosNLI. In this paper, we explore the option of training directly on the estimated label distribution of the annotators in the NLI task, using a learning loss based on this ambiguity distribution instead of the gold-labels. We prepare AmbiNLI, a trial dataset obtained from readily available sources, and show it is possible to reduce ChaosNLI divergence scores when finetuning on this data, a promising first step towards learning how to capture linguistic ambiguity. Additionally, we show that training on the same amount of data but targeting the ambiguity distribution instead of gold-labels can result in models that achieve higher performance and learn better representations for downstream tasks.