 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Measuring and Mitigating Reasoning Shortcuts in Machine Reading Comprehension
Paper and Code
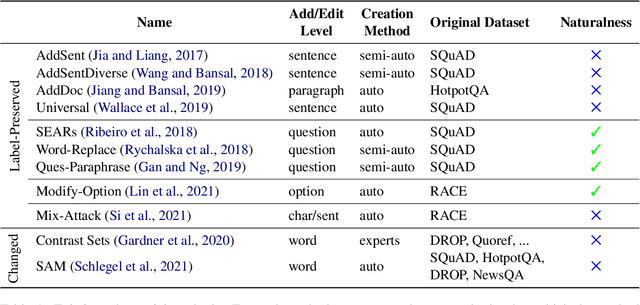

The issue of shortcut learning is widely known in NLP and has been an important research focus in recent years. Unintended correlations in the data enable models to easily solve tasks that were meant to exhibit advanced language understanding and reasoning capabilities. In this survey paper, we focus on the field of machine reading comprehension (MRC), an important task for showcasing high-level language understanding that also suffers from a range of shortcuts. We summarize the available techniques for measuring and mitigating shortcuts and conclude with suggestions for further progress in shortcut research. Most importantly, we highlight two main concerns for shortcut mitigation in MRC: the lack of public challenge sets, a necessary component for effective and reusable evaluation, and the lack of certain mitigation techniques that are prominent in other areas.