 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT Editors, Not Authors: The Stylistic Footprint of LLMs in Academic Preprints
May 22, 2025The proliferation of Large Language Models (LLMs) in late 2022 has impacted academic writing, threatening credibility, and causing institutional uncertainty. We seek to determine the degree to which LLMs are used to generate critical text as opposed to being used for editing, such as checking for grammar errors or inappropriate phrasing. In our study, we analyze arXiv papers for stylistic segmentation, which we measure by varying a PELT threshold against a Bayesian classifier trained on GPT-regenerated text. We find that LLM-attributed language is not predictive of stylistic segmentation, suggesting that when authors use LLMs, they do so uniformly, reducing the risk of hallucinations being introduced into academic preprints.
Depressed individuals express more distorted thinking on social media
Feb 07, 2020
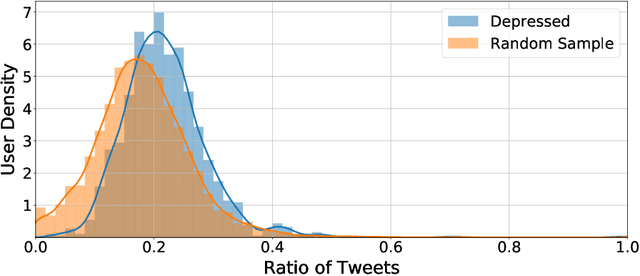
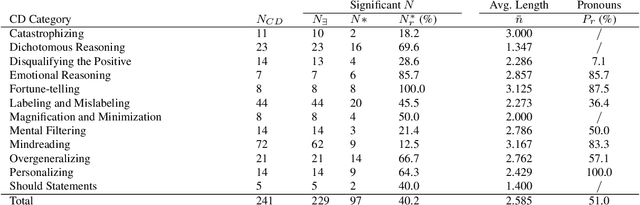
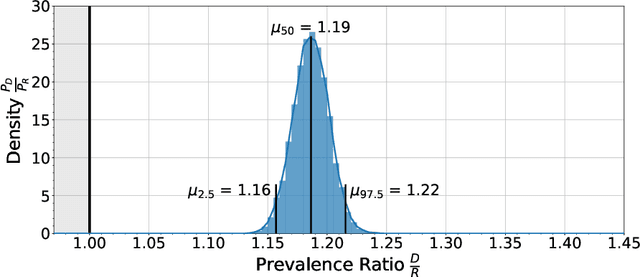
Depression is a leading cause of disability worldwide, but is often under-diagnosed and under-treated. One of the tenets of cognitive-behavioral therapy (CBT) is that individuals who are depressed exhibit distorted modes of thinking, so-called cognitive distortions, which can negatively affect their emotions and motivation. Here, we show that individuals with a self-reported diagnosis of depression on social media express higher levels of distorted thinking than a random sample. Some types of distorted thinking were found to be more than twice as prevalent in our depressed cohort, in particular Personalizing and Emotional Reasoning. This effect is specific to the distorted content of the expression and can not be explained by the presence of specific topics, sentiment, or first-person pronouns. Our results point towards the detection, and possibly mitigation, of patterns of online language that are generally deemed depressogenic. They may also provide insight into recent observations that social media usage can have a negative impact on mental health.
The happiness paradox: your friends are happier than you
Feb 08, 2016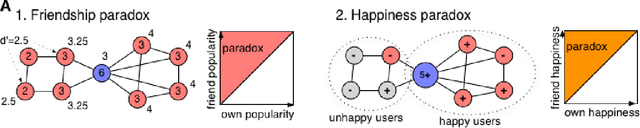

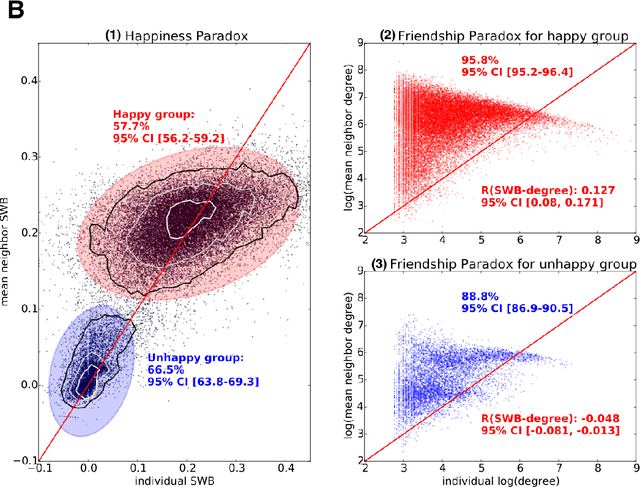
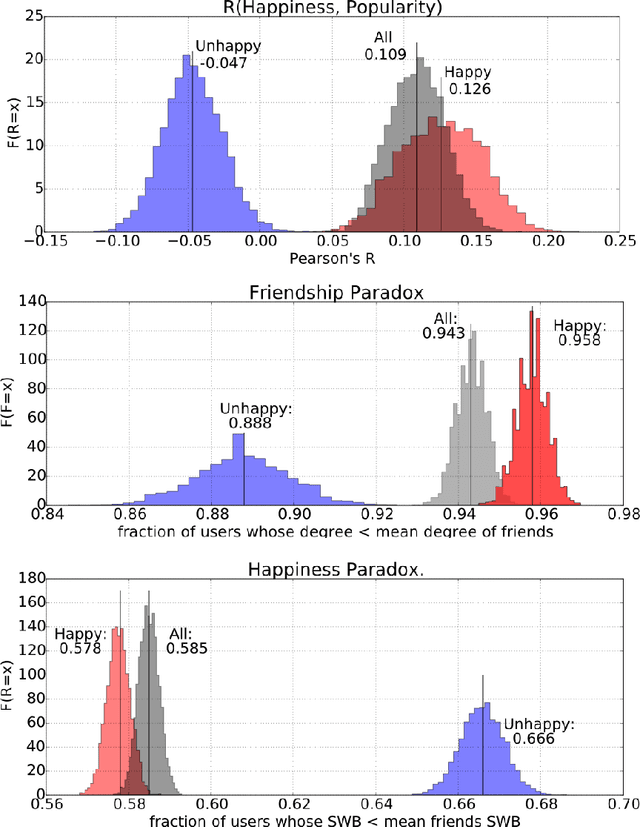
Most individuals in social networks experience a so-called Friendship Paradox: they are less popular than their friends on average. This effect may explain recent findings that widespread social network media use leads to reduced happiness. However the relation between popularity and happiness is poorly understood. A Friendship paradox does not necessarily imply a Happiness paradox where most individuals are less happy than their friends. Here we report the first direct observation of a significant Happiness Paradox in a large-scale online social network of $39,110$ Twitter users. Our results reveal that popular individuals are indeed happier and that a majority of individuals experience a significant Happiness paradox. The magnitude of the latter effect is shaped by complex interactions between individual popularity, happiness, and the fact that users cluster assortatively by level of happiness. Our results indicate that the topology of online social networks and the distribution of happiness in some populations can cause widespread psycho-social effects that affect the well-being of billions of individuals.
Happiness is assortative in online social networks
Mar 03, 2011Social networks tend to disproportionally favor connections between individuals with either similar or dissimilar characteristics. This propensity, referred to as assortative mixing or homophily, is expressed as the correlation between attribute values of nearest neighbour vertices in a graph. Recent results indicate that beyond demographic features such as age, sex and race, even psychological states such as "loneliness" can be assortative in a social network. In spite of the increasing societal importance of online social networks it is unknown whether assortative mixing of psychological states takes place in situations where social ties are mediated solely by online networking services in the absence of physical contact. Here, we show that general happiness or Subjective Well-Being (SWB) of Twitter users, as measured from a 6 month record of their individual tweets, is indeed assortative across the Twitter social network. To our knowledge this is the first result that shows assortative mixing in online networks at the level of SWB. Our results imply that online social networks may be equally subject to the social mechanisms that cause assortative mixing in real social networks and that such assortative mixing takes place at the level of SWB. Given the increasing prevalence of online social networks, their propensity to connect users with similar levels of SWB may be an important instrument in better understanding how both positive and negative sentiments spread through online social ties. Future research may focus on how event-specific mood states can propagate and influence user behavior in "real life".
* 17 pages, 9 figures
Twitter mood predicts the stock market
Oct 14, 2010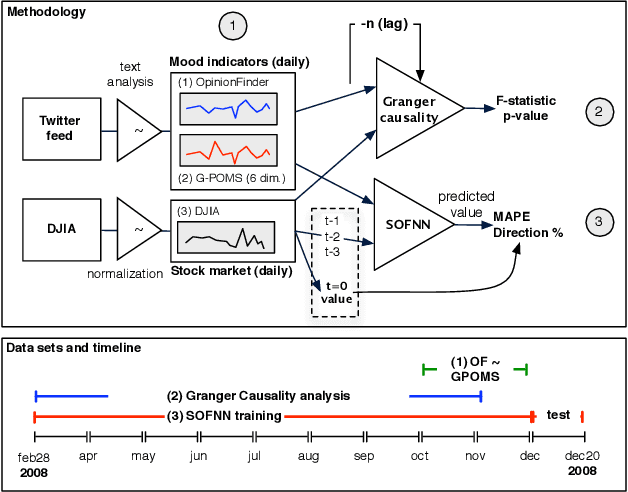
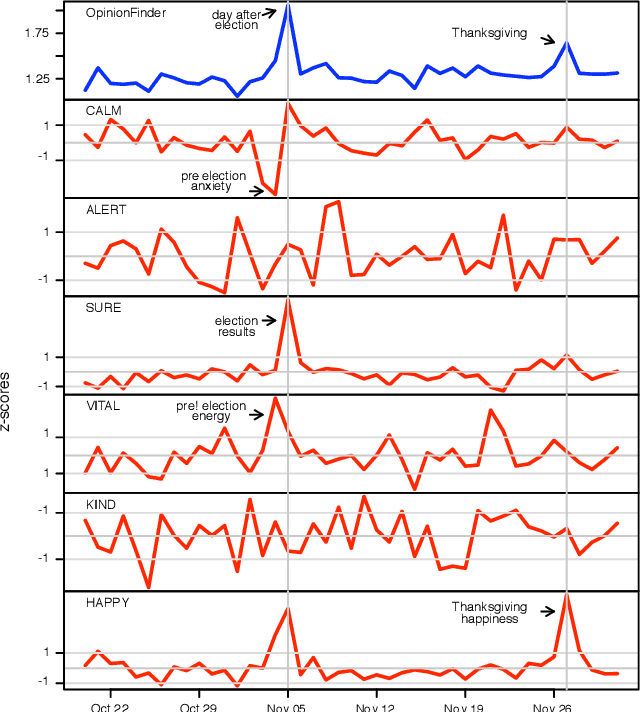
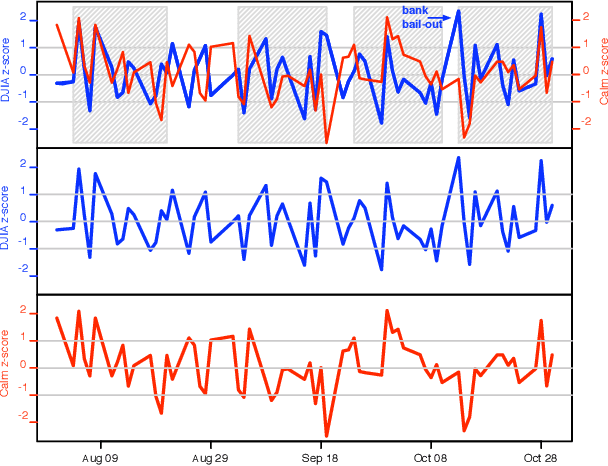
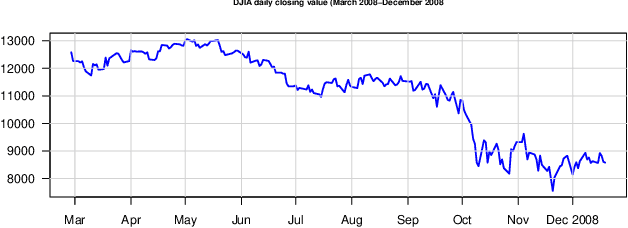
Behavioral economics tells us that emotions can profoundly affect individual behavior and decision-making. Does this also apply to societies at large, i.e., can societies experience mood states that affect their collective decision making? By extension is the public mood correlated or even predictive of economic indicators? Here we investigate whether measurements of collective mood states derived from large-scale Twitter feeds are correlated to the value of the Dow Jones Industrial Average (DJIA) over time. We analyze the text content of daily Twitter feeds by two mood tracking tools, namely OpinionFinder that measures positive vs. negative mood and Google-Profile of Mood States (GPOMS) that measures mood in terms of 6 dimensions (Calm, Alert, Sure, Vital, Kind, and Happy). We cross-validate the resulting mood time series by comparing their ability to detect the public's response to the presidential election and Thanksgiving day in 2008. A Granger causality analysis and a Self-Organizing Fuzzy Neural Network are then used to investigate the hypothesis that public mood states, as measured by the OpinionFinder and GPOMS mood time series, are predictive of changes in DJIA closing values. Our results indicate that the accuracy of DJIA predictions can be significantly improved by the inclusion of specific public mood dimensions but not others. We find an accuracy of 87.6% in predicting the daily up and down changes in the closing values of the DJIA and a reduction of the Mean Average Percentage Error by more than 6%.
An Algorithm to Determine Peer-Reviewers
Jul 15, 2008



The peer-review process is the most widely accepted certification mechanism for officially accepting the written results of researchers within the scientific community. An essential component of peer-review is the identification of competent referees to review a submitted manuscript. This article presents an algorithm to automatically determine the most appropriate reviewers for a manuscript by way of a co-authorship network data structure and a relative-rank particle-swarm algorithm. This approach is novel in that it is not limited to a pre-selected set of referees, is computationally efficient, requires no human-intervention, and, in some instances, can automatically identify conflict of interest situations. A useful application of this algorithm would be to open commentary peer-review systems because it provides a weighting for each referee with respects to their expertise in the domain of a manuscript. The algorithm is validated using referee bid data from the 2005 Joint Conference on Digital Libraries.
* Rodriguez, M.A., Bollen, J., "An Algorithm to Determine Peer-Reviewers", Conference on Information and Knowledge Management, in press, ACM, LA-UR-06-2261, October 2008; ISBN:978-1-59593-991-3
Between conjecture and memento: shaping a collective emotional perception of the future
Jan 25, 2008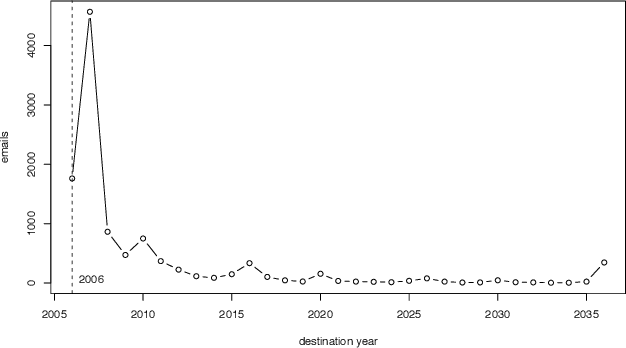
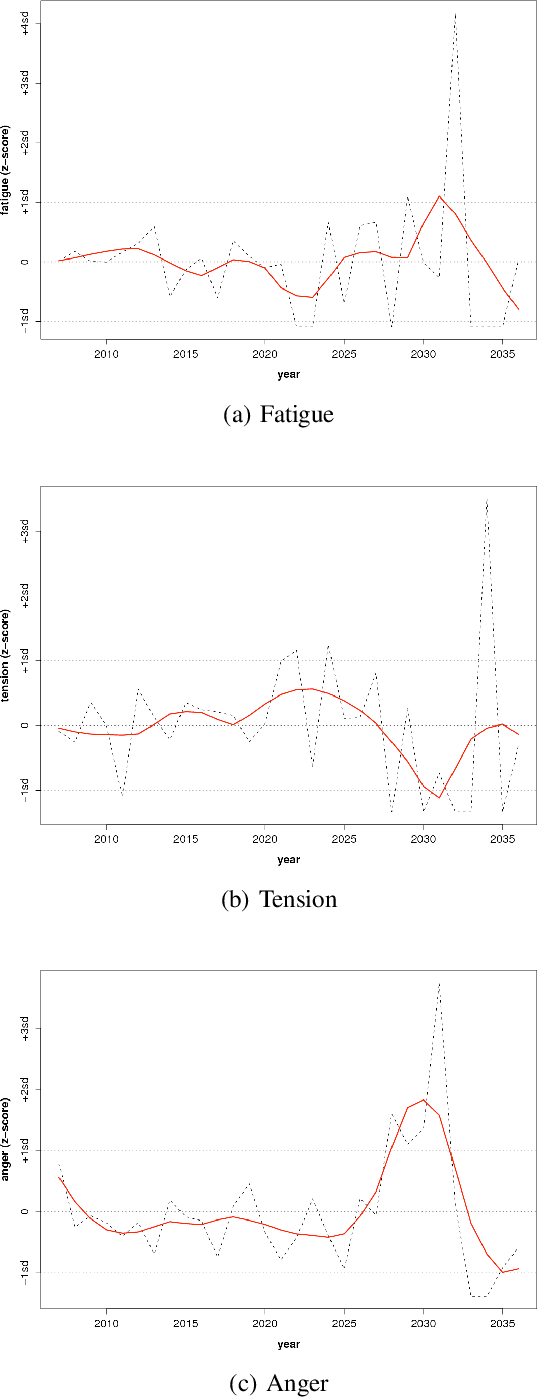
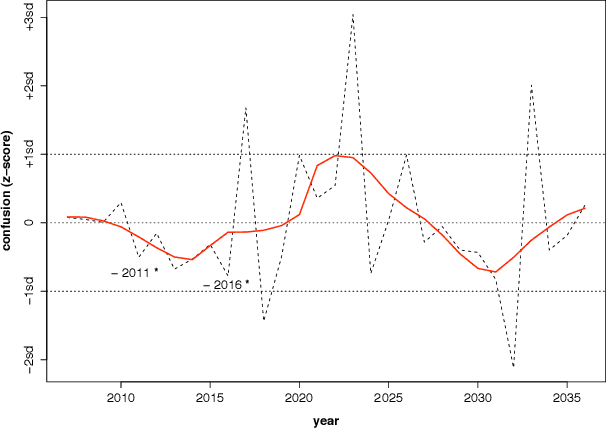
Large scale surveys of public mood are costly and often impractical to perform. However, the web is awash with material indicative of public mood such as blogs, emails, and web queries. Inexpensive content analysis on such extensive corpora can be used to assess public mood fluctuations. The work presented here is concerned with the analysis of the public mood towards the future. Using an extension of the Profile of Mood States questionnaire, we have extracted mood indicators from 10,741 emails submitted in 2006 to futureme.org, a web service that allows its users to send themselves emails to be delivered at a later date. Our results indicate long-term optimism toward the future, but medium-term apprehension and confusion.
Using RDF to Model the Structure and Process of Systems
Oct 15, 2007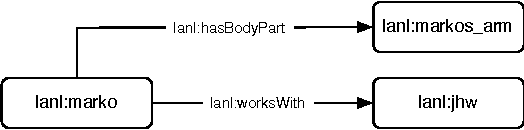
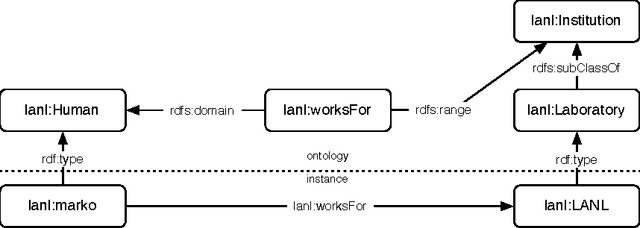
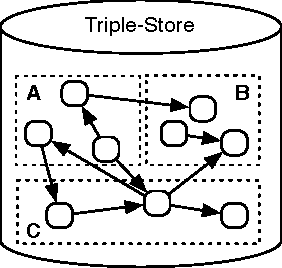
Many systems can be described in terms of networks of discrete elements and their various relationships to one another. A semantic network, or multi-relational network, is a directed labeled graph consisting of a heterogeneous set of entities connected by a heterogeneous set of relationships. Semantic networks serve as a promising general-purpose modeling substrate for complex systems. Various standardized formats and tools are now available to support practical, large-scale semantic network models. First, the Resource Description Framework (RDF) offers a standardized semantic network data model that can be further formalized by ontology modeling languages such as RDF Schema (RDFS) and the Web Ontology Language (OWL). Second, the recent introduction of highly performant triple-stores (i.e. semantic network databases) allows semantic network models on the order of $10^9$ edges to be efficiently stored and manipulated. RDF and its related technologies are currently used extensively in the domains of computer science, digital library science, and the biological sciences. This article will provide an introduction to RDF/RDFS/OWL and an examination of its suitability to model discrete element complex systems.
* International Conference on Complex Systems, Boston MA, October 2007
Modeling Computations in a Semantic Network
May 31, 2007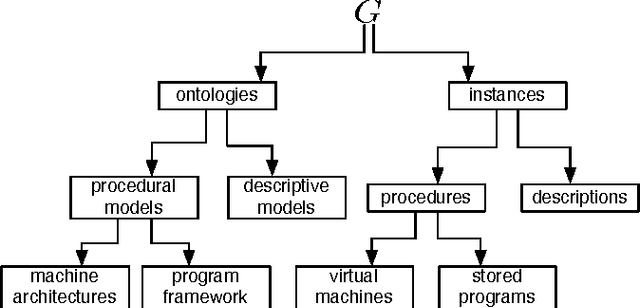
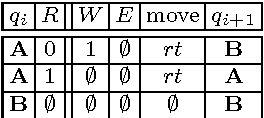
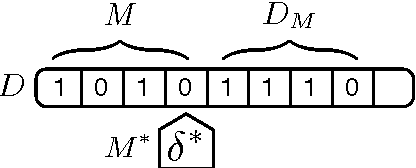
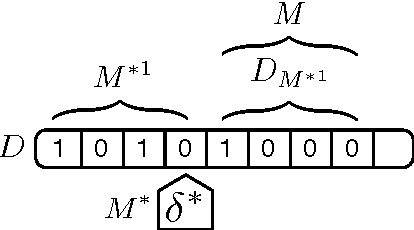
Semantic network research has seen a resurgence from its early history in the cognitive sciences with the inception of the Semantic Web initiative. The Semantic Web effort has brought forth an array of technologies that support the encoding, storage, and querying of the semantic network data structure at the world stage. Currently, the popular conception of the Semantic Web is that of a data modeling medium where real and conceptual entities are related in semantically meaningful ways. However, new models have emerged that explicitly encode procedural information within the semantic network substrate. With these new technologies, the Semantic Web has evolved from a data modeling medium to a computational medium. This article provides a classification of existing computational modeling efforts and the requirements of supporting technologies that will aid in the further growth of this burgeoning domain.