 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-Purpose Computing on a Semantic Network Substrate
Jun 06, 2010

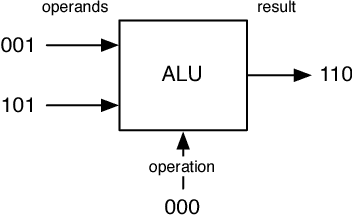

This article presents a model of general-purpose computing on a semantic network substrate. The concepts presented are applicable to any semantic network representation. However, due to the standards and technological infrastructure devoted to the Semantic Web effort, this article is presented from this point of view. In the proposed model of computing, the application programming interface, the run-time program, and the state of the computing virtual machine are all represented in the Resource Description Framework (RDF). The implementation of the concepts presented provides a practical computing paradigm that leverages the highly-distributed and standardized representational-layer of the Semantic Web.
The Dilated Triple
Jun 06, 2010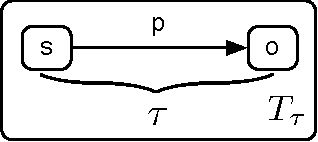

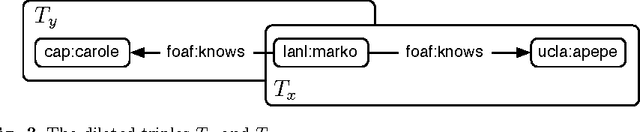
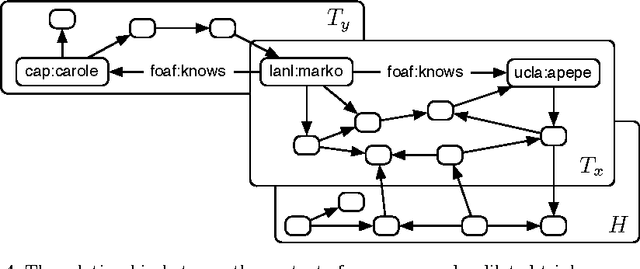
The basic unit of meaning on the Semantic Web is the RDF statement, or triple, which combines a distinct subject, predicate and object to make a definite assertion about the world. A set of triples constitutes a graph, to which they give a collective meaning. It is upon this simple foundation that the rich, complex knowledge structures of the Semantic Web are built. Yet the very expressiveness of RDF, by inviting comparison with real-world knowledge, highlights a fundamental shortcoming, in that RDF is limited to statements of absolute fact, independent of the context in which a statement is asserted. This is in stark contrast with the thoroughly context-sensitive nature of human thought. The model presented here provides a particularly simple means of contextualizing an RDF triple by associating it with related statements in the same graph. This approach, in combination with a notion of graph similarity, is sufficient to select only those statements from an RDF graph which are subjectively most relevant to the context of the requesting process.
A Reflection on the Structure and Process of the Web of Data
Aug 04, 2009
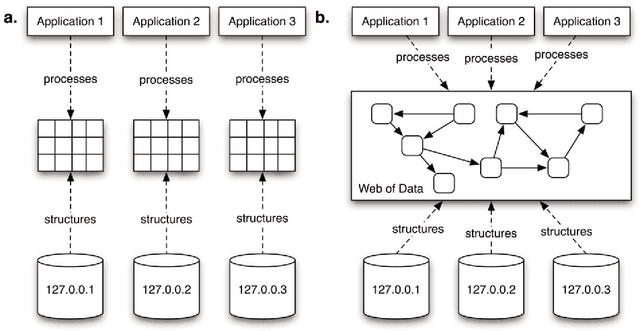
The Web community has introduced a set of standards and technologies for representing, querying, and manipulating a globally distributed data structure known as the Web of Data. The proponents of the Web of Data envision much of the world's data being interrelated and openly accessible to the general public. This vision is analogous in many ways to the Web of Documents of common knowledge, but instead of making documents and media openly accessible, the focus is on making data openly accessible. In providing data for public use, there has been a stimulated interest in a movement dubbed Open Data. Open Data is analogous in many ways to the Open Source movement. However, instead of focusing on software, Open Data is focused on the legal and licensing issues around publicly exposed data. Together, various technological and legal tools are laying the groundwork for the future of global-scale data management on the Web. As of today, in its early form, the Web of Data hosts a variety of data sets that include encyclopedic facts, drug and protein data, metadata on music, books and scholarly articles, social network representations, geospatial information, and many other types of information. The size and diversity of the Web of Data is a demonstration of the flexibility of the underlying standards and the overall feasibility of the project as a whole. The purpose of this article is to provide a review of the technological underpinnings of the Web of Data as well as some of the hurdles that need to be overcome if the Web of Data is to emerge as the defacto medium for data representation, distribution, and ultimately, processing.
Interpretations of the Web of Data
May 21, 2009
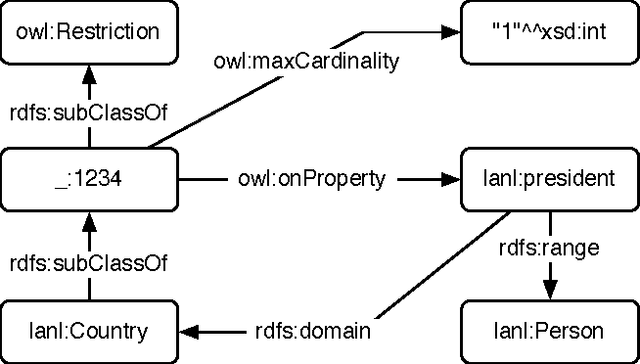
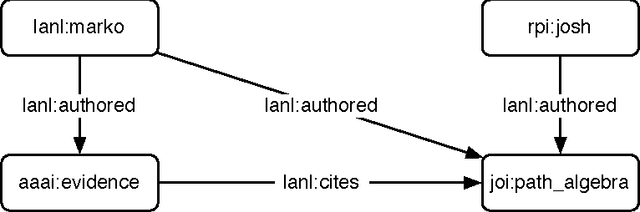
The emerging Web of Data utilizes the web infrastructure to represent and interrelate data. The foundational standards of the Web of Data include the Uniform Resource Identifier (URI) and the Resource Description Framework (RDF). URIs are used to identify resources and RDF is used to relate resources. While RDF has been posited as a logic language designed specifically for knowledge representation and reasoning, it is more generally useful if it can conveniently support other models of computing. In order to realize the Web of Data as a general-purpose medium for storing and processing the world's data, it is necessary to separate RDF from its logic language legacy and frame it simply as a data model. Moreover, there is significant advantage in seeing the Semantic Web as a particular interpretation of the Web of Data that is focused specifically on knowledge representation and reasoning. By doing so, other interpretations of the Web of Data are exposed that realize RDF in different capacities and in support of different computing models.
Faith in the Algorithm, Part 2: Computational Eudaemonics
Apr 01, 2009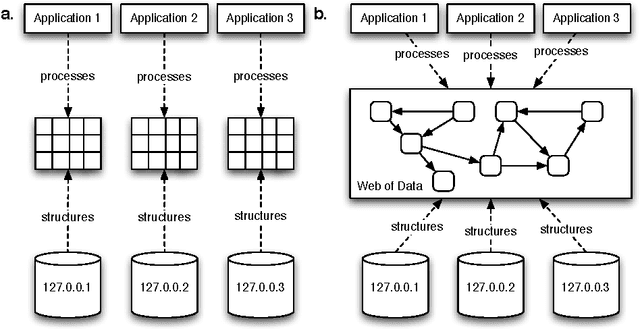

Eudaemonics is the study of the nature, causes, and conditions of human well-being. According to the ethical theory of eudaemonia, reaping satisfaction and fulfillment from life is not only a desirable end, but a moral responsibility. However, in modern society, many individuals struggle to meet this responsibility. Computational mechanisms could better enable individuals to achieve eudaemonia by yielding practical real-world systems that embody algorithms that promote human flourishing. This article presents eudaemonic systems as the evolutionary goal of the present day recommender system.
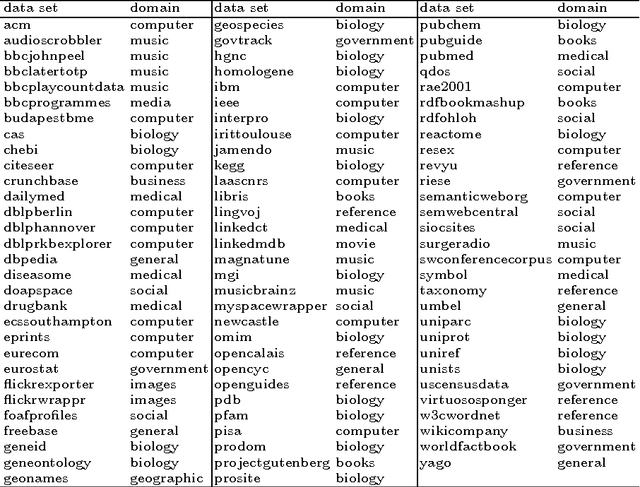
A Graph Analysis of the Linked Data Cloud
Mar 02, 2009


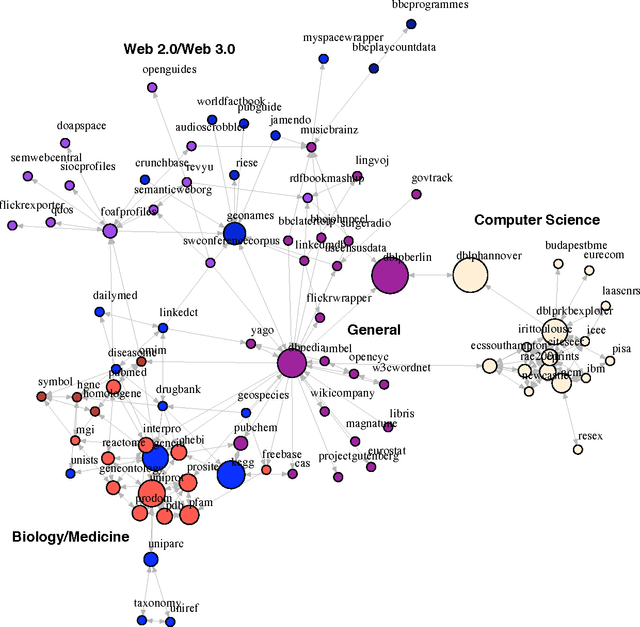
The Linked Data community is focused on integrating Resource Description Framework (RDF) data sets into a single unified representation known as the Web of Data. The Web of Data can be traversed by both man and machine and shows promise as the \textit{de facto} standard for integrating data world wide much like the World Wide Web is the \textit{de facto} standard for integrating documents. On February 27$^\text{th}$ of 2009, an updated Linked Data cloud visualization was made publicly available. This visualization represents the various RDF data sets currently in the Linked Data cloud and their interlinking relationships. For the purposes of this article, this visual representation was manually transformed into a directed graph and analyzed.
Faith in the Algorithm, Part 1: Beyond the Turing Test
Mar 02, 2009Since the Turing test was first proposed by Alan Turing in 1950, the primary goal of artificial intelligence has been predicated on the ability for computers to imitate human behavior. However, the majority of uses for the computer can be said to fall outside the domain of human abilities and it is exactly outside of this domain where computers have demonstrated their greatest contribution to intelligence. Another goal for artificial intelligence is one that is not predicated on human mimicry, but instead, on human amplification. This article surveys various systems that contribute to the advancement of human and social intelligence.
Grammar-Based Random Walkers in Semantic Networks
Sep 10, 2008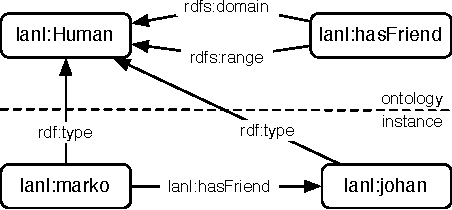
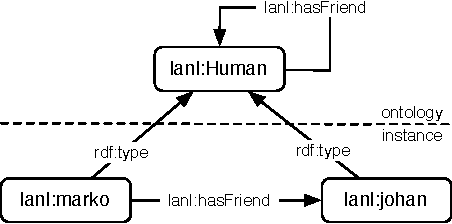
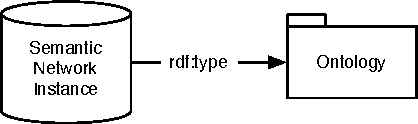

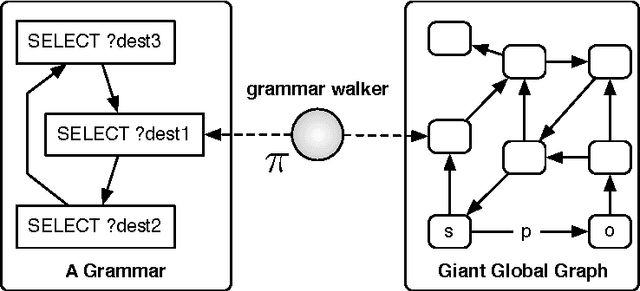
Semantic networks qualify the meaning of an edge relating any two vertices. Determining which vertices are most "central" in a semantic network is difficult because one relationship type may be deemed subjectively more important than another. For this reason, research into semantic network metrics has focused primarily on context-based rankings (i.e. user prescribed contexts). Moreover, many of the current semantic network metrics rank semantic associations (i.e. directed paths between two vertices) and not the vertices themselves. This article presents a framework for calculating semantically meaningful primary eigenvector-based metrics such as eigenvector centrality and PageRank in semantic networks using a modified version of the random walker model of Markov chain analysis. Random walkers, in the context of this article, are constrained by a grammar, where the grammar is a user defined data structure that determines the meaning of the final vertex ranking. The ideas in this article are presented within the context of the Resource Description Framework (RDF) of the Semantic Web initiative.
* First draft of manuscript originally written in November 2006
A Distributed Process Infrastructure for a Distributed Data Structure
Jul 24, 2008The Resource Description Framework (RDF) is continuing to grow outside the bounds of its initial function as a metadata framework and into the domain of general-purpose data modeling. This expansion has been facilitated by the continued increase in the capacity and speed of RDF database repositories known as triple-stores. High-end RDF triple-stores can hold and process on the order of 10 billion triples. In an effort to provide a seamless integration of the data contained in RDF repositories, the Linked Data community is providing specifications for linking RDF data sets into a universal distributed graph that can be traversed by both man and machine. While the seamless integration of RDF data sets is important, at the scale of the data sets that currently exist and will ultimately grow to become, the "download and index" philosophy of the World Wide Web will not so easily map over to the Semantic Web. This essay discusses the importance of adding a distributed RDF process infrastructure to the current distributed RDF data structure.
An Algorithm to Determine Peer-Reviewers
Jul 15, 2008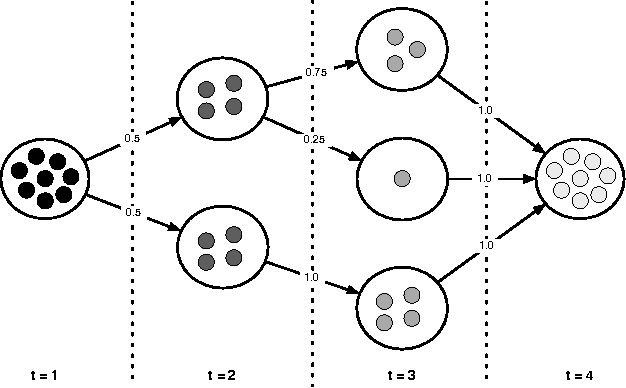



The peer-review process is the most widely accepted certification mechanism for officially accepting the written results of researchers within the scientific community. An essential component of peer-review is the identification of competent referees to review a submitted manuscript. This article presents an algorithm to automatically determine the most appropriate reviewers for a manuscript by way of a co-authorship network data structure and a relative-rank particle-swarm algorithm. This approach is novel in that it is not limited to a pre-selected set of referees, is computationally efficient, requires no human-intervention, and, in some instances, can automatically identify conflict of interest situations. A useful application of this algorithm would be to open commentary peer-review systems because it provides a weighting for each referee with respects to their expertise in the domain of a manuscript. The algorithm is validated using referee bid data from the 2005 Joint Conference on Digital Libraries.
* Rodriguez, M.A., Bollen, J., "An Algorithm to Determine Peer-Reviewers", Conference on Information and Knowledge Management, in press, ACM, LA-UR-06-2261, October 2008; ISBN:978-1-59593-991-3