 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetries in Overparametrized Neural Networks: A Mean-Field View
May 30, 2024We develop a Mean-Field (MF) view of the learning dynamics of overparametrized Artificial Neural Networks (NN) under data symmetric in law wrt the action of a general compact group $G$. We consider for this a class of generalized shallow NNs given by an ensemble of $N$ multi-layer units, jointly trained using stochastic gradient descent (SGD) and possibly symmetry-leveraging (SL) techniques, such as Data Augmentation (DA), Feature Averaging (FA) or Equivariant Architectures (EA). We introduce the notions of weakly and strongly invariant laws (WI and SI) on the parameter space of each single unit, corresponding, respectively, to $G$-invariant distributions, and to distributions supported on parameters fixed by the group action (which encode EA). This allows us to define symmetric models compatible with taking $N\to\infty$ and give an interpretation of the asymptotic dynamics of DA, FA and EA in terms of Wasserstein Gradient Flows describing their MF limits. When activations respect the group action, we show that, for symmetric data, DA, FA and freely-trained models obey the exact same MF dynamic, which stays in the space of WI laws and minimizes therein the population risk. We also give a counterexample to the general attainability of an optimum over SI laws. Despite this, quite remarkably, we show that the set of SI laws is also preserved by the MF dynamics even when freely trained. This sharply contrasts the finite-$N$ setting, in which EAs are generally not preserved by unconstrained SGD. We illustrate the validity of our findings as $N$ gets larger in a teacher-student experimental setting, training a student NN to learn from a WI, SI or arbitrary teacher model through various SL schemes. We last deduce a data-driven heuristic to discover the largest subspace of parameters supporting SI distributions for a problem, that could be used for designing EA with minimal generalization error.
Streaming computation of optimal weak transport barycenters
Feb 26, 2021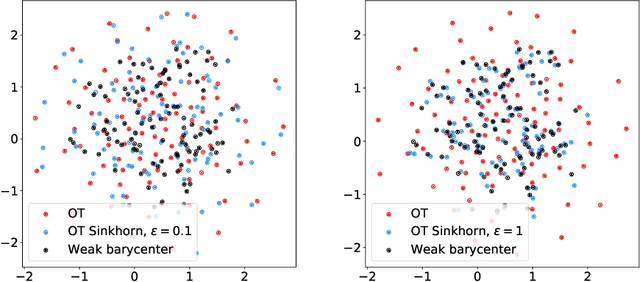
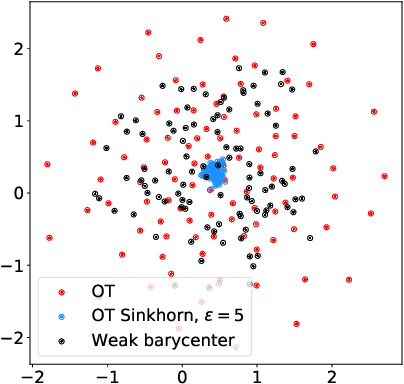
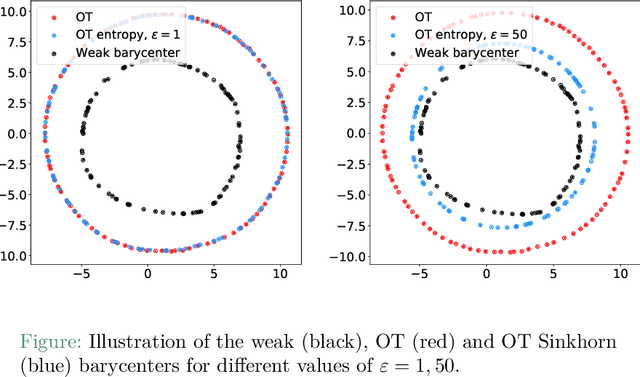
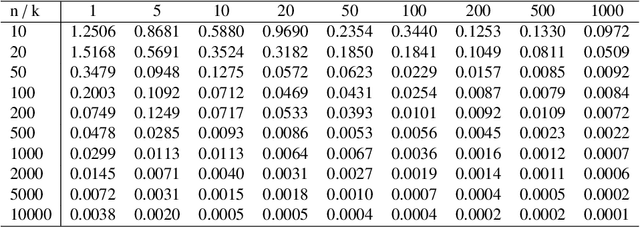
We introduce the weak barycenter of a family of probability distributions, based on the recently developed notion of optimal weak transport of measures arXiv:1412.7480(v4). We provide a theoretical analysis of the weak barycenter and its relationship to the classic Wasserstein barycenter, and discuss its meaning in the light of convex ordering between probability measures. In particular, we argue that, rather than averaging the information of the input distributions as done by the usual optimal transport barycenters, weak barycenters contain geometric information shared across all input distributions, which can be interpreted as a latent random variable affecting all the measures. We also provide iterative algorithms to compute a weak barycenter for either finite or infinite families of arbitrary measures (with finite moments of order 2), which are particularly well suited for the streaming setting, i.e., when measures arrive sequentially. In particular, our streaming computation of weak barycenters does not require to smooth empirical measures or to define a common grid for them, as some of the previous approaches to Wasserstin barycenters do. The concept of weak barycenter and our computation approaches are illustrated on synthetic examples, validated on 2D real-world data and compared to the classical Wasserstein barycenters.
Bayesian Learning with Wasserstein Barycenters
Jun 25, 2018
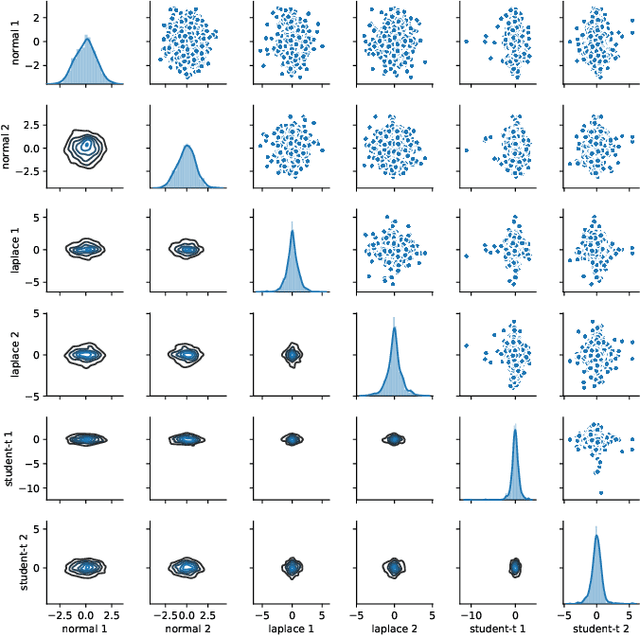
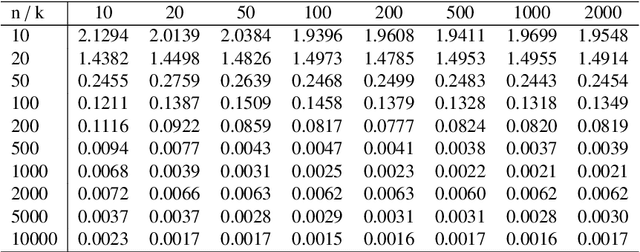
In this work we introduce a novel paradigm for Bayesian learning based on optimal transport theory. Namely, we propose to use the Wasserstein barycenter of the posterior law on models, as an alternative to the maximum a posteriori estimator and Bayesian model average. We exhibit conditions granting the existence and consistency of this estimator, discuss some of its basic and specific properties, and provide insight for practical implementations relying on standard sampling in finite-dimensional parameter spaces. We thus contribute to the recent blooming of applications of optimal transport theory in machine learning, beyond the discrete setting so far considered. The advantages of the proposed estimator are presented in theoretical terms and through analytical and numeral examples.