 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhost Units Yield Biologically Plausible Backprop in Deep Neural Networks
Nov 15, 2019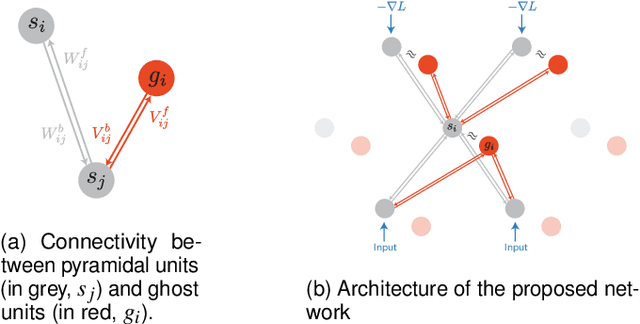
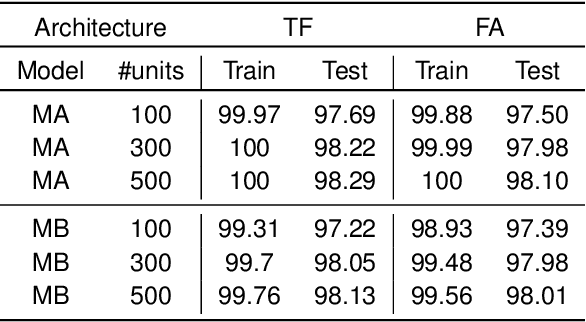
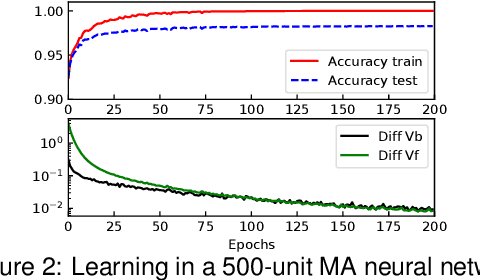
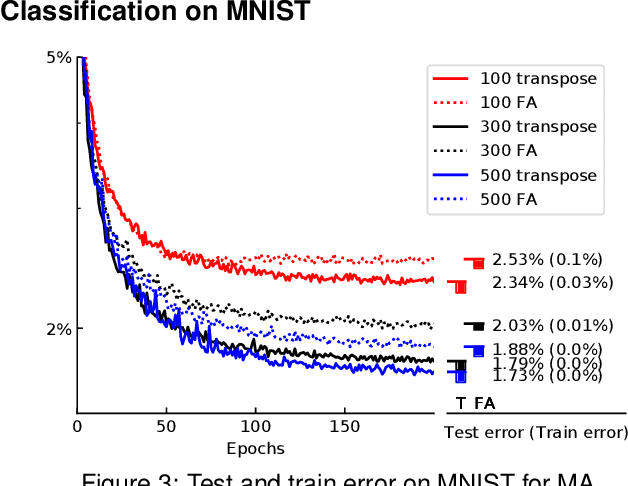
In the past few years, deep learning has transformed artificial intelligence research and led to impressive performance in various difficult tasks. However, it is still unclear how the brain can perform credit assignment across many areas as efficiently as backpropagation does in deep neural networks. In this paper, we introduce a model that relies on a new role for a neuronal inhibitory machinery, referred to as ghost units. By cancelling the feedback coming from the upper layer when no target signal is provided to the top layer, the ghost units enables the network to backpropagate errors and do efficient credit assignment in deep structures. While considering one-compartment neurons and requiring very few biological assumptions, it is able to approximate the error gradient and achieve good performance on classification tasks. Error backpropagation occurs through the recurrent dynamics of the network and thanks to biologically plausible local learning rules. In particular, it does not require separate feedforward and feedback circuits. Different mechanisms for cancelling the feedback were studied, ranging from complete duplication of the connectivity by long term processes to online replication of the feedback activity. This reduced system combines the essential elements to have a working biologically abstracted analogue of backpropagation with a simple formulation and proofs of the associated results. Therefore, this model is a step towards understanding how learning and memory are implemented in cortical multilayer structures, but it also raises interesting perspectives for neuromorphic hardware.
Feedforward Initialization for Fast Inference of Deep Generative Networks is biologically plausible
Jun 28, 2016
We consider deep multi-layered generative models such as Boltzmann machines or Hopfield nets in which computation (which implements inference) is both recurrent and stochastic, but where the recurrence is not to model sequential structure, only to perform computation. We find conditions under which a simple feedforward computation is a very good initialization for inference, after the input units are clamped to observed values. It means that after the feedforward initialization, the recurrent network is very close to a fixed point of the network dynamics, where the energy gradient is 0. The main condition is that consecutive layers form a good auto-encoder, or more generally that different groups of inputs into the unit (in particular, bottom-up inputs on one hand, top-down inputs on the other hand) are consistent with each other, producing the same contribution into the total weighted sum of inputs. In biological terms, this would correspond to having each dendritic branch correctly predicting the aggregate input from all the dendritic branches, i.e., the soma potential. This is consistent with the prediction that the synaptic weights into dendritic branches such as those of the apical and basal dendrites of pyramidal cells are trained to minimize the prediction error made by the dendritic branch when the target is the somatic activity. Whereas previous work has shown how to achieve fast negative phase inference (when the model is unclamped) in a predictive recurrent model, this contribution helps to achieve fast positive phase inference (when the target output is clamped) in such recurrent neural models.