 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Complexity in Part-of-Speech Induction
Jan 16, 2014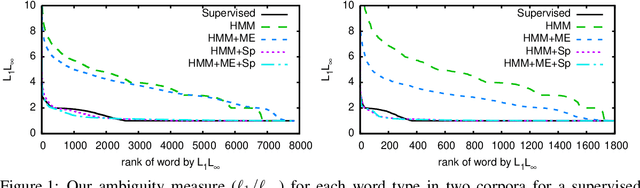

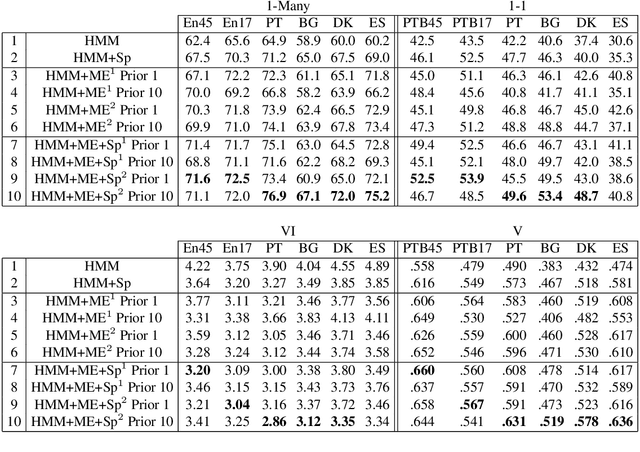
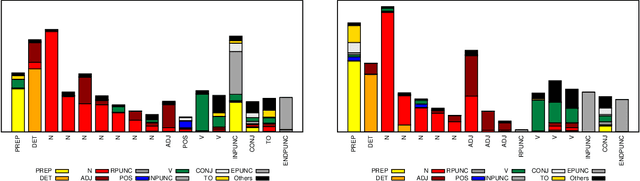
We consider the problem of fully unsupervised learning of grammatical (part-of-speech) categories from unlabeled text. The standard maximum-likelihood hidden Markov model for this task performs poorly, because of its weak inductive bias and large model capacity. We address this problem by refining the model and modifying the learning objective to control its capacity via para- metric and non-parametric constraints. Our approach enforces word-category association sparsity, adds morphological and orthographic features, and eliminates hard-to-estimate parameters for rare words. We develop an efficient learning algorithm that is not much more computationally intensive than standard training. We also provide an open-source implementation of the algorithm. Our experiments on five diverse languages (Bulgarian, Danish, English, Portuguese, Spanish) achieve significant improvements compared with previous methods for the same task.