 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePi-NAS: Improving Neural Architecture Search by Reducing Supernet Training Consistency Shift
Aug 22, 2021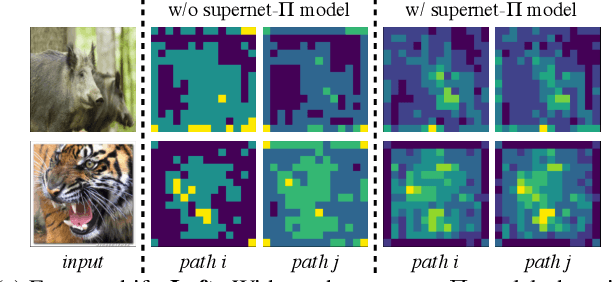
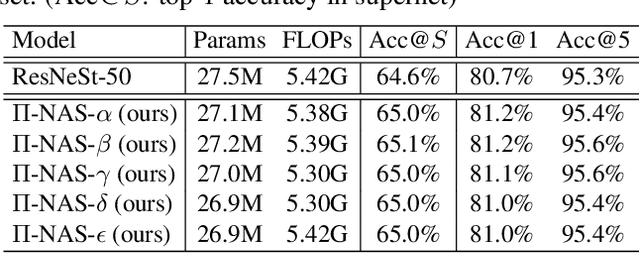
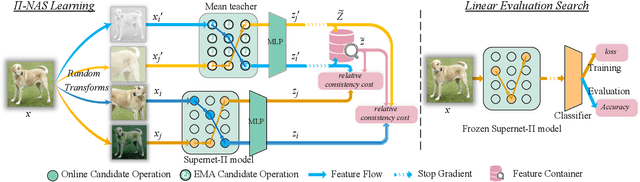
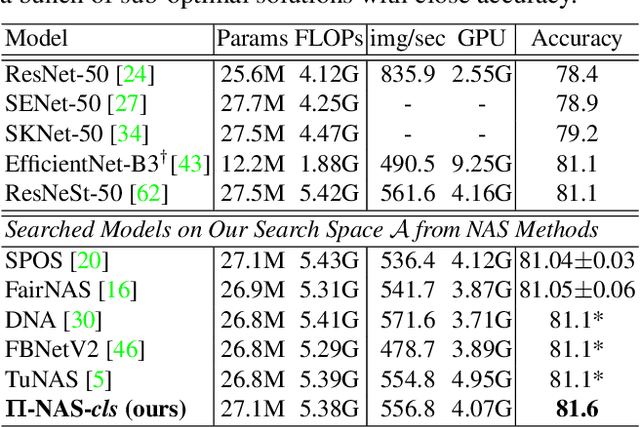
Recently proposed neural architecture search (NAS) methods co-train billions of architectures in a supernet and estimate their potential accuracy using the network weights detached from the supernet. However, the ranking correlation between the architectures' predicted accuracy and their actual capability is incorrect, which causes the existing NAS methods' dilemma. We attribute this ranking correlation problem to the supernet training consistency shift, including feature shift and parameter shift. Feature shift is identified as dynamic input distributions of a hidden layer due to random path sampling. The input distribution dynamic affects the loss descent and finally affects architecture ranking. Parameter shift is identified as contradictory parameter updates for a shared layer lay in different paths in different training steps. The rapidly-changing parameter could not preserve architecture ranking. We address these two shifts simultaneously using a nontrivial supernet-Pi model, called Pi-NAS. Specifically, we employ a supernet-Pi model that contains cross-path learning to reduce the feature consistency shift between different paths. Meanwhile, we adopt a novel nontrivial mean teacher containing negative samples to overcome parameter shift and model collision. Furthermore, our Pi-NAS runs in an unsupervised manner, which can search for more transferable architectures. Extensive experiments on ImageNet and a wide range of downstream tasks (e.g., COCO 2017, ADE20K, and Cityscapes) demonstrate the effectiveness and universality of our Pi-NAS compared to supervised NAS. See Codes: https://github.com/Ernie1/Pi-NAS.
Joint Learning of Neural Transfer and Architecture Adaptation for Image Recognition
Mar 31, 2021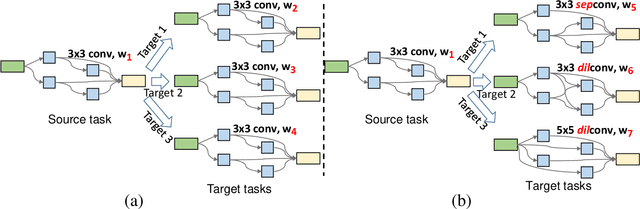



Current state-of-the-art visual recognition systems usually rely on the following pipeline: (a) pretraining a neural network on a large-scale dataset (e.g., ImageNet) and (b) finetuning the network weights on a smaller, task-specific dataset. Such a pipeline assumes the sole weight adaptation is able to transfer the network capability from one domain to another domain, based on a strong assumption that a fixed architecture is appropriate for all domains. However, each domain with a distinct recognition target may need different levels/paths of feature hierarchy, where some neurons may become redundant, and some others are re-activated to form new network structures. In this work, we prove that dynamically adapting network architectures tailored for each domain task along with weight finetuning benefits in both efficiency and effectiveness, compared to the existing image recognition pipeline that only tunes the weights regardless of the architecture. Our method can be easily generalized to an unsupervised paradigm by replacing supernet training with self-supervised learning in the source domain tasks and performing linear evaluation in the downstream tasks. This further improves the search efficiency of our method. Moreover, we also provide principled and empirical analysis to explain why our approach works by investigating the ineffectiveness of existing neural architecture search. We find that preserving the joint distribution of the network architecture and weights is of importance. This analysis not only benefits image recognition but also provides insights for crafting neural networks. Experiments on five representative image recognition tasks such as person re-identification, age estimation, gender recognition, image classification, and unsupervised domain adaptation demonstrate the effectiveness of our method.