 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDNeRF: Vision-only Dynamic Neural Radiance Field for Urban Scenes
Nov 09, 2025Neural Radiance Fields (NeRFs) implicitly model continuous three-dimensional scenes using a set of images with known camera poses, enabling the rendering of photorealistic novel views. However, existing NeRF-based methods encounter challenges in applications such as autonomous driving and robotic perception, primarily due to the difficulty of capturing accurate camera poses and limitations in handling large-scale dynamic environments. To address these issues, we propose Vision-only Dynamic NeRF (VDNeRF), a method that accurately recovers camera trajectories and learns spatiotemporal representations for dynamic urban scenes without requiring additional camera pose information or expensive sensor data. VDNeRF employs two separate NeRF models to jointly reconstruct the scene. The static NeRF model optimizes camera poses and static background, while the dynamic NeRF model incorporates the 3D scene flow to ensure accurate and consistent reconstruction of dynamic objects. To address the ambiguity between camera motion and independent object motion, we design an effective and powerful training framework to achieve robust camera pose estimation and self-supervised decomposition of static and dynamic elements in a scene. Extensive evaluations on mainstream urban driving datasets demonstrate that VDNeRF surpasses state-of-the-art NeRF-based pose-free methods in both camera pose estimation and dynamic novel view synthesis.
Multi-vehicle Flocking Control with Deep Deterministic Policy Gradient Method
Jun 01, 2018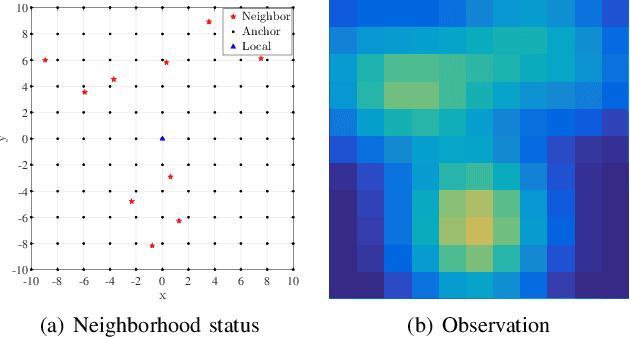
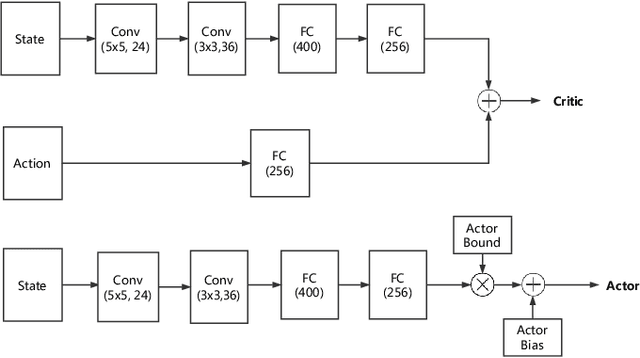
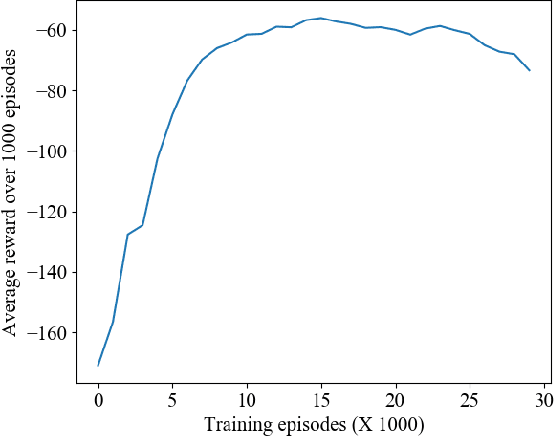
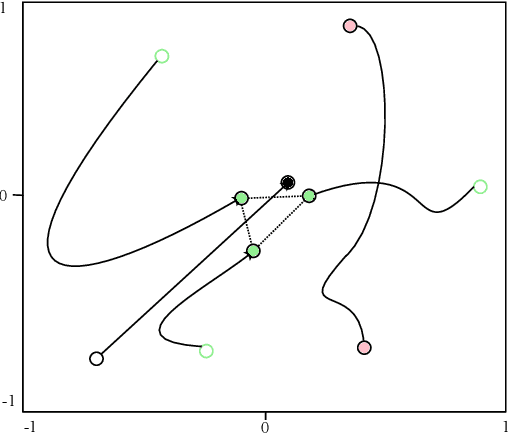
Flocking control has been studied extensively along with the wide application of multi-vehicle systems. In this paper the Multi-vehicles System (MVS) flocking control with collision avoidance and communication preserving is considered based on the deep reinforcement learning framework. Specifically the deep deterministic policy gradient (DDPG) with centralized training and distributed execution process is implemented to obtain the flocking control policy. First, to avoid the dynamically changed observation of state, a three layers tensor based representation of the observation is used so that the state remains constant although the observation dimension is changing. A reward function is designed to guide the way-points tracking, collision avoidance and communication preserving. The reward function is augmented by introducing the local reward function of neighbors. Finally, a centralized training process which trains the shared policy based on common training set among all agents. The proposed method is tested under simulated scenarios with different setup.