 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Attribute Capsules for Noise Face Super Resolution
Feb 16, 2020
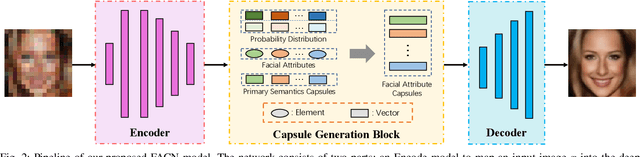
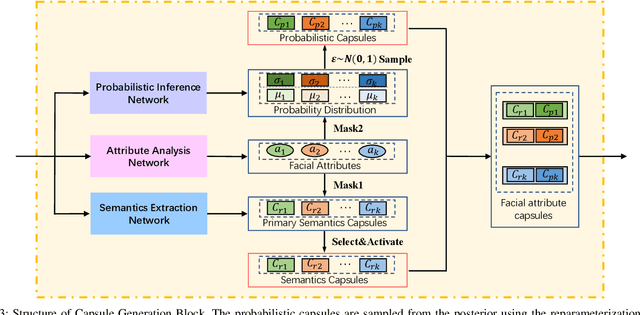

Existing face super-resolution (SR) methods mainly assume the input image to be noise-free. Their performance degrades drastically when applied to real-world scenarios where the input image is always contaminated by noise. In this paper, we propose a Facial Attribute Capsules Network (FACN) to deal with the problem of high-scale super-resolution of noisy face image. Capsule is a group of neurons whose activity vector models different properties of the same entity. Inspired by the concept of capsule, we propose an integrated representation model of facial information, which named Facial Attribute Capsule (FAC). In the SR processing, we first generated a group of FACs from the input LR face, and then reconstructed the HR face from this group of FACs. Aiming to effectively improve the robustness of FAC to noise, we generate FAC in semantic, probabilistic and facial attributes manners by means of integrated learning strategy. Each FAC can be divided into two sub-capsules: Semantic Capsule (SC) and Probabilistic Capsule (PC). Them describe an explicit facial attribute in detail from two aspects of semantic representation and probability distribution. The group of FACs model an image as a combination of facial attribute information in the semantic space and probabilistic space by an attribute-disentangling way. The diverse FACs could better combine the face prior information to generate the face images with fine-grained semantic attributes. Extensive benchmark experiments show that our method achieves superior hallucination results and outperforms state-of-the-art for very low resolution (LR) noise face image super resolution.
Video Face Super-Resolution with Motion-Adaptive Feedback Cell
Feb 15, 2020



Video super-resolution (VSR) methods have recently achieved a remarkable success due to the development of deep convolutional neural networks (CNN). Current state-of-the-art CNN methods usually treat the VSR problem as a large number of separate multi-frame super-resolution tasks, at which a batch of low resolution (LR) frames is utilized to generate a single high resolution (HR) frame, and running a slide window to select LR frames over the entire video would obtain a series of HR frames. However, duo to the complex temporal dependency between frames, with the number of LR input frames increase, the performance of the reconstructed HR frames become worse. The reason is in that these methods lack the ability to model complex temporal dependencies and hard to give an accurate motion estimation and compensation for VSR process. Which makes the performance degrade drastically when the motion in frames is complex. In this paper, we propose a Motion-Adaptive Feedback Cell (MAFC), a simple but effective block, which can efficiently capture the motion compensation and feed it back to the network in an adaptive way. Our approach efficiently utilizes the information of the inter-frame motion, the dependence of the network on motion estimation and compensation method can be avoid. In addition, benefiting from the excellent nature of MAFC, the network can achieve better performance in the case of extremely complex motion scenarios. Extensive evaluations and comparisons validate the strengths of our approach, and the experimental results demonstrated that the proposed framework is outperform the state-of-the-art methods.