 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Forcing: Autoregressive Video Generation with Reward Feedback
Jan 23, 2026While most prior work in video generation relies on bidirectional architectures, recent efforts have sought to adapt these models into autoregressive variants to support near real-time generation. However, such adaptations often depend heavily on teacher models, which can limit performance, particularly in the absence of a strong autoregressive teacher, resulting in output quality that typically lags behind their bidirectional counterparts. In this paper, we explore an alternative approach that uses reward signals to guide the generation process, enabling more efficient and scalable autoregressive generation. By using reward signals to guide the model, our method simplifies training while preserving high visual fidelity and temporal consistency. Through extensive experiments on standard benchmarks, we find that our approach performs comparably to existing autoregressive models and, in some cases, surpasses similarly sized bidirectional models by avoiding constraints imposed by teacher architectures. For example, on VBench, our method achieves a total score of 84.92, closely matching state-of-the-art autoregressive methods that score 84.31 but require significant heterogeneous distillation.
Can Agent Conquer Web? Exploring the Frontiers of ChatGPT Atlas Agent in Web Games
Oct 30, 2025OpenAI's ChatGPT Atlas introduces new capabilities for web interaction, enabling the model to analyze webpages, process user intents, and execute cursor and keyboard inputs directly within the browser. While its capacity for information retrieval tasks has been demonstrated, its performance in dynamic, interactive environments remains less explored. In this study, we conduct an early evaluation of Atlas's web interaction capabilities using browser-based games as test scenarios, including Google's T-Rex Runner, Sudoku, Flappy Bird, and Stein.world. We employ in-game performance scores as quantitative metrics to assess performance across different task types. Our results show that Atlas performs strongly in logical reasoning tasks like Sudoku, completing puzzles significantly faster than human baselines, but struggles substantially in real-time games requiring precise timing and motor control, often failing to progress beyond initial obstacles. These findings suggest that while Atlas demonstrates capable analytical processing, there remain notable limitations in dynamic web environments requiring real-time interaction. The website of our project can be found at https://atlas-game-eval.github.io.
Latent Video Dataset Distillation
Apr 23, 2025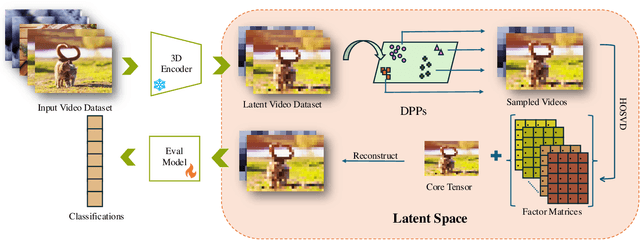

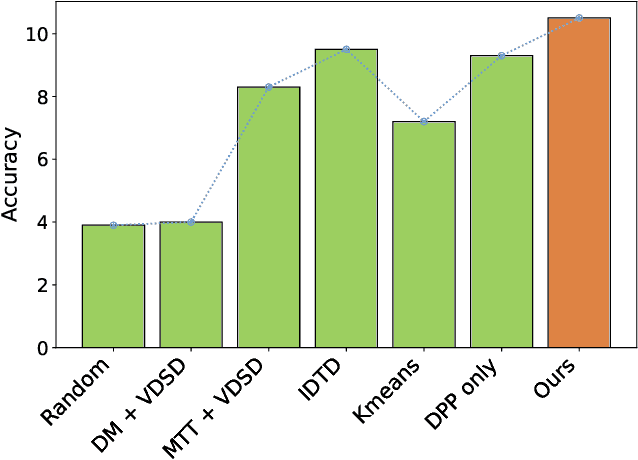

Dataset distillation has demonstrated remarkable effectiveness in high-compression scenarios for image datasets. While video datasets inherently contain greater redundancy, existing video dataset distillation methods primarily focus on compression in the pixel space, overlooking advances in the latent space that have been widely adopted in modern text-to-image and text-to-video models. In this work, we bridge this gap by introducing a novel video dataset distillation approach that operates in the latent space using a state-of-the-art variational encoder. Furthermore, we employ a diversity-aware data selection strategy to select both representative and diverse samples. Additionally, we introduce a simple, training-free method to further compress the distilled latent dataset. By combining these techniques, our approach achieves a new state-of-the-art performance in dataset distillation, outperforming prior methods on all datasets, e.g. on HMDB51 IPC 1, we achieve a 2.6% performance increase; on MiniUCF IPC 5, we achieve a 7.8% performance increase.
Have we unified image generation and understanding yet? An empirical study of GPT-4o's image generation ability
Apr 09, 2025OpenAI's multimodal GPT-4o has demonstrated remarkable capabilities in image generation and editing, yet its ability to achieve world knowledge-informed semantic synthesis--seamlessly integrating domain knowledge, contextual reasoning, and instruction adherence--remains unproven. In this study, we systematically evaluate these capabilities across three critical dimensions: (1) Global Instruction Adherence, (2) Fine-Grained Editing Precision, and (3) Post-Generation Reasoning. While existing benchmarks highlight GPT-4o's strong capabilities in image generation and editing, our evaluation reveals GPT-4o's persistent limitations: the model frequently defaults to literal interpretations of instructions, inconsistently applies knowledge constraints, and struggles with conditional reasoning tasks. These findings challenge prevailing assumptions about GPT-4o's unified understanding and generation capabilities, exposing significant gaps in its dynamic knowledge integration. Our study calls for the development of more robust benchmarks and training strategies that go beyond surface-level alignment, emphasizing context-aware and reasoning-grounded multimodal generation.
Cooperative Cross-Stream Network for Discriminative Action Representation
Aug 27, 2019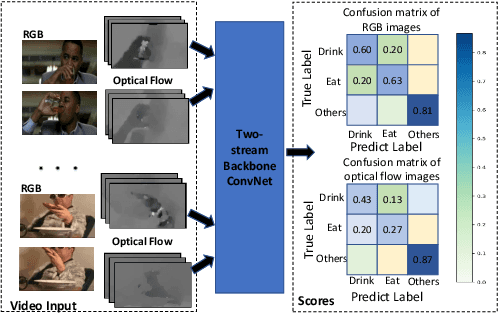

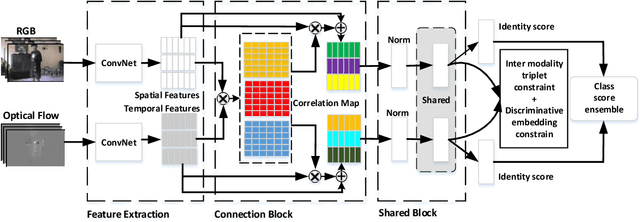
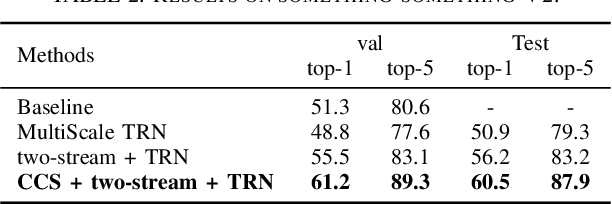
Spatial and temporal stream model has gained great success in video action recognition. Most existing works pay more attention to designing effective features fusion methods, which train the two-stream model in a separate way. However, it's hard to ensure discriminability and explore complementary information between different streams in existing works. In this work, we propose a novel cooperative cross-stream network that investigates the conjoint information in multiple different modalities. The jointly spatial and temporal stream networks feature extraction is accomplished by an end-to-end learning manner. It extracts this complementary information of different modality from a connection block, which aims at exploring correlations of different stream features. Furthermore, different from the conventional ConvNet that learns the deep separable features with only one cross-entropy loss, our proposed model enhances the discriminative power of the deeply learned features and reduces the undesired modality discrepancy by jointly optimizing a modality ranking constraint and a cross-entropy loss for both homogeneous and heterogeneous modalities. The modality ranking constraint constitutes intra-modality discriminative embedding and inter-modality triplet constraint, and it reduces both the intra-modality and cross-modality feature variations. Experiments on three benchmark datasets demonstrate that by cooperating appearance and motion feature extraction, our method can achieve state-of-the-art or competitive performance compared with existing results.
Temporal Reasoning Graph for Activity Recognition
Aug 27, 2019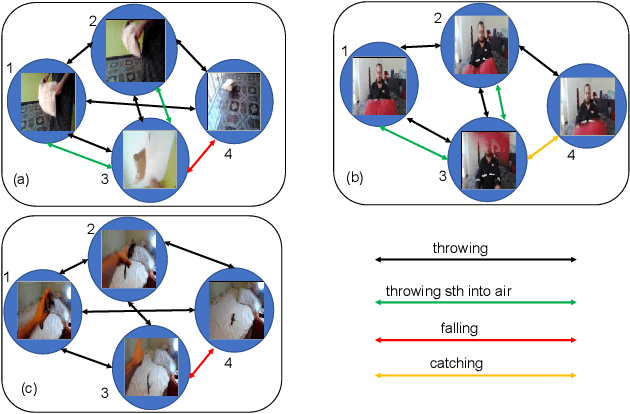


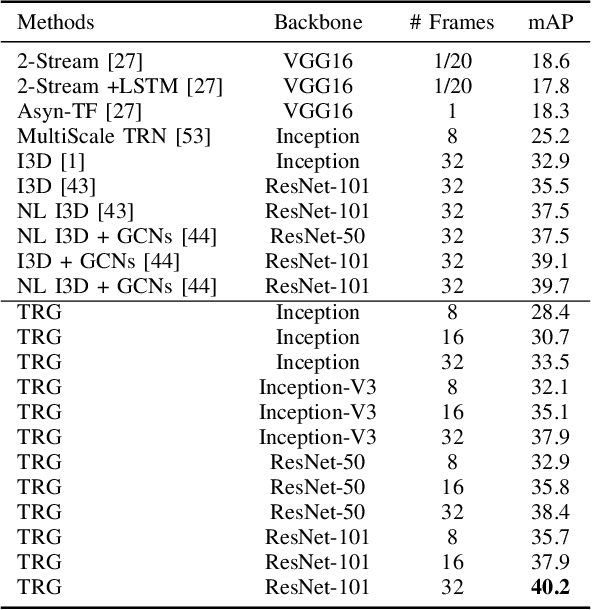
Despite great success has been achieved in activity analysis, it still has many challenges. Most existing work in activity recognition pay more attention to design efficient architecture or video sampling strategy. However, due to the property of fine-grained action and long term structure in video, activity recognition is expected to reason temporal relation between video sequences. In this paper, we propose an efficient temporal reasoning graph (TRG) to simultaneously capture the appearance features and temporal relation between video sequences at multiple time scales. Specifically, we construct learnable temporal relation graphs to explore temporal relation on the multi-scale range. Additionally, to facilitate multi-scale temporal relation extraction, we design a multi-head temporal adjacent matrix to represent multi-kinds of temporal relations. Eventually, a multi-head temporal relation aggregator is proposed to extract the semantic meaning of those features convolving through the graphs. Extensive experiments are performed on widely-used large-scale datasets, such as Something-Something and Charades, and the results show that our model can achieve state-of-the-art performance. Further analysis shows that temporal relation reasoning with our TRG can extract discriminative features for activity recognition.