 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSedentary Behavior Estimation with Hip-worn Accelerometer Data: Segmentation, Classification and Thresholding
Jul 05, 2022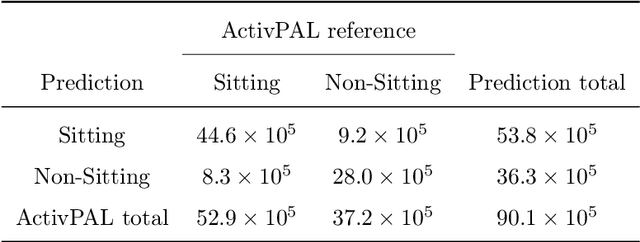
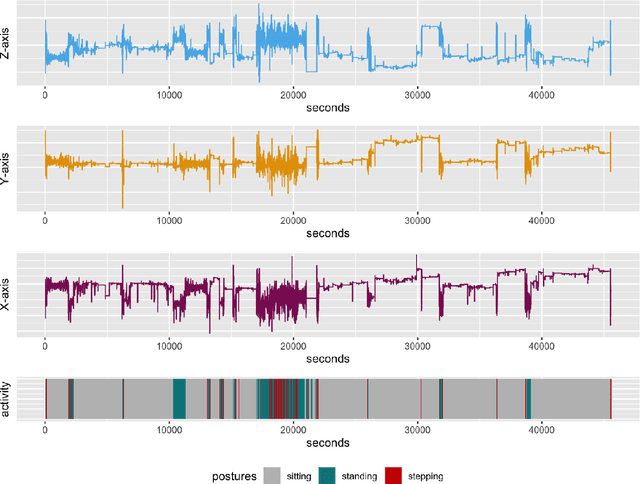

Cohort studies are increasingly using accelerometers for physical activity and sedentary behavior estimation. These devices tend to be less error-prone than self-report, can capture activity throughout the day, and are economical. However, previous methods for estimating sedentary behavior based on hip-worn data are often invalid or suboptimal under free-living situations and subject-to-subject variation. In this paper, we propose a local Markov switching model that takes this situation into account, and introduce a general procedure for posture classification and sedentary behavior analysis that fits the model naturally. Our method features changepoint detection methods in time series and also a two stage classification step that labels data into 3 classes(sitting, standing, stepping). Through a rigorous training-testing paradigm, we showed that our approach achieves > 80% accuracy. In addition, our method is robust and easy to interpret.
Improving Self-supervised Learning with Automated Unsupervised Outlier Arbitration
Dec 15, 2021

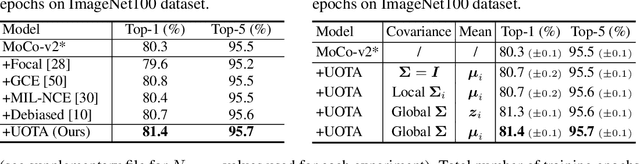
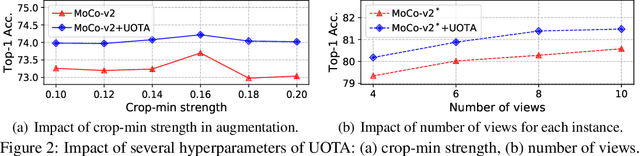
Our work reveals a structured shortcoming of the existing mainstream self-supervised learning methods. Whereas self-supervised learning frameworks usually take the prevailing perfect instance level invariance hypothesis for granted, we carefully investigate the pitfalls behind. Particularly, we argue that the existing augmentation pipeline for generating multiple positive views naturally introduces out-of-distribution (OOD) samples that undermine the learning of the downstream tasks. Generating diverse positive augmentations on the input does not always pay off in benefiting downstream tasks. To overcome this inherent deficiency, we introduce a lightweight latent variable model UOTA, targeting the view sampling issue for self-supervised learning. UOTA adaptively searches for the most important sampling region to produce views, and provides viable choice for outlier-robust self-supervised learning approaches. Our method directly generalizes to many mainstream self-supervised learning approaches, regardless of the loss's nature contrastive or not. We empirically show UOTA's advantage over the state-of-the-art self-supervised paradigms with evident margin, which well justifies the existence of the OOD sample issue embedded in the existing approaches. Especially, we theoretically prove that the merits of the proposal boil down to guaranteed estimator variance and bias reduction. Code is available: at https://github.com/ssl-codelab/uota.