 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Self-supervised Learning with Automated Unsupervised Outlier Arbitration
Paper and Code


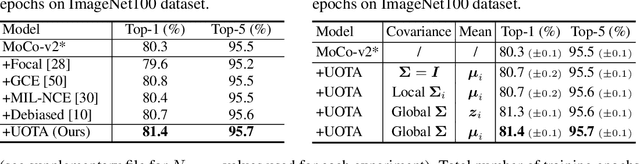
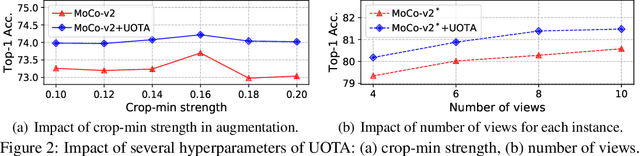
Our work reveals a structured shortcoming of the existing mainstream self-supervised learning methods. Whereas self-supervised learning frameworks usually take the prevailing perfect instance level invariance hypothesis for granted, we carefully investigate the pitfalls behind. Particularly, we argue that the existing augmentation pipeline for generating multiple positive views naturally introduces out-of-distribution (OOD) samples that undermine the learning of the downstream tasks. Generating diverse positive augmentations on the input does not always pay off in benefiting downstream tasks. To overcome this inherent deficiency, we introduce a lightweight latent variable model UOTA, targeting the view sampling issue for self-supervised learning. UOTA adaptively searches for the most important sampling region to produce views, and provides viable choice for outlier-robust self-supervised learning approaches. Our method directly generalizes to many mainstream self-supervised learning approaches, regardless of the loss's nature contrastive or not. We empirically show UOTA's advantage over the state-of-the-art self-supervised paradigms with evident margin, which well justifies the existence of the OOD sample issue embedded in the existing approaches. Especially, we theoretically prove that the merits of the proposal boil down to guaranteed estimator variance and bias reduction. Code is available: at https://github.com/ssl-codelab/uota.