 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZFusion: An Effective Fuser of Camera and 4D Radar for 3D Object Perception in Autonomous Driving
Apr 07, 2025
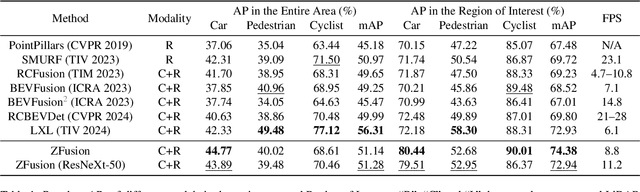
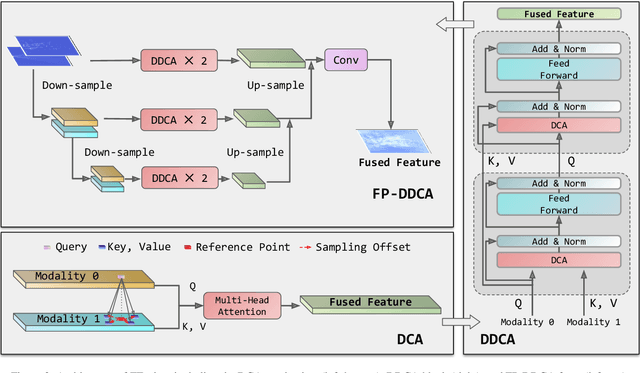
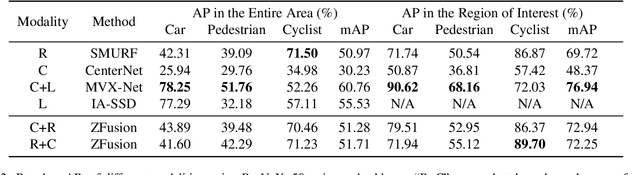
Reliable 3D object perception is essential in autonomous driving. Owing to its sensing capabilities in all weather conditions, 4D radar has recently received much attention. However, compared to LiDAR, 4D radar provides much sparser point cloud. In this paper, we propose a 3D object detection method, termed ZFusion, which fuses 4D radar and vision modality. As the core of ZFusion, our proposed FP-DDCA (Feature Pyramid-Double Deformable Cross Attention) fuser complements the (sparse) radar information and (dense) vision information, effectively. Specifically, with a feature-pyramid structure, the FP-DDCA fuser packs Transformer blocks to interactively fuse multi-modal features at different scales, thus enhancing perception accuracy. In addition, we utilize the Depth-Context-Split view transformation module due to the physical properties of 4D radar. Considering that 4D radar has a much lower cost than LiDAR, ZFusion is an attractive alternative to LiDAR-based methods. In typical traffic scenarios like the VoD (View-of-Delft) dataset, experiments show that with reasonable inference speed, ZFusion achieved the state-of-the-art mAP (mean average precision) in the region of interest, while having competitive mAP in the entire area compared to the baseline methods, which demonstrates performance close to LiDAR and greatly outperforms those camera-only methods.