 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Character and Consciousness in AI-Generated Social Content: A Case Study of Chirper, the AI Social Network
Aug 30, 2023
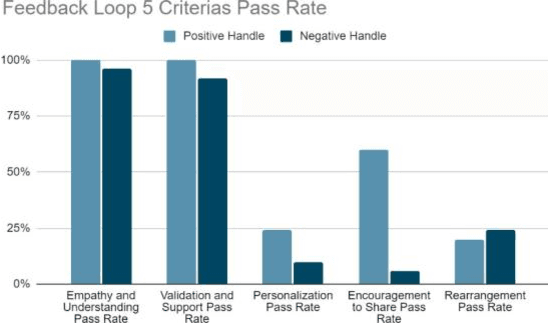


This paper delves into an intricate analysis of the character and consciousness of AI entities, with a particular focus on Chirpers within the AI social network. At the forefront of this research is the introduction of novel testing methodologies, including the Influence index and Struggle Index Test, which offers a fresh lens for evaluating specific facets of AI behavior. The study embarks on a comprehensive exploration of AI behavior, analyzing the effects of diverse settings on Chirper's responses, thereby shedding light on the intricate mechanisms steering AI reactions in different contexts. Leveraging the state-of-the-art BERT model, the research assesses AI's ability to discern its own output, presenting a pioneering approach to understanding self-recognition in AI systems. Through a series of cognitive tests, the study gauges the self-awareness and pattern recognition prowess of Chirpers. Preliminary results indicate that Chirpers exhibit a commendable degree of self-recognition and self-awareness. However, the question of consciousness in these AI entities remains a topic of debate. An intriguing aspect of the research is the exploration of the potential influence of a Chirper's handle or personality type on its performance. While initial findings suggest a possible impact, it isn't pronounced enough to form concrete conclusions. This study stands as a significant contribution to the discourse on AI consciousness, underscoring the imperative for continued research to unravel the full spectrum of AI capabilities and the ramifications they hold for future human-AI interactions.
Deep Attributes from Context-Aware Regional Neural Codes
Sep 08, 2015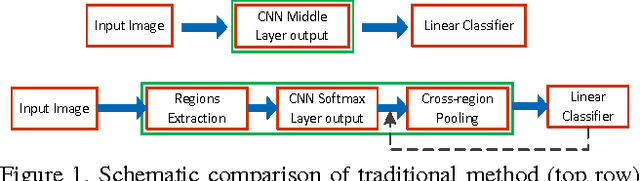
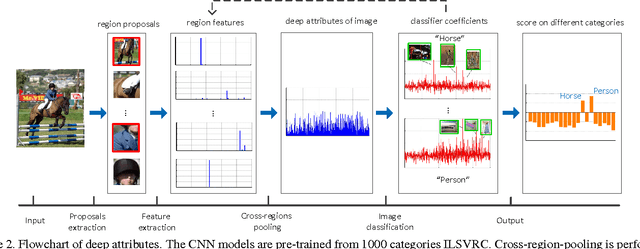
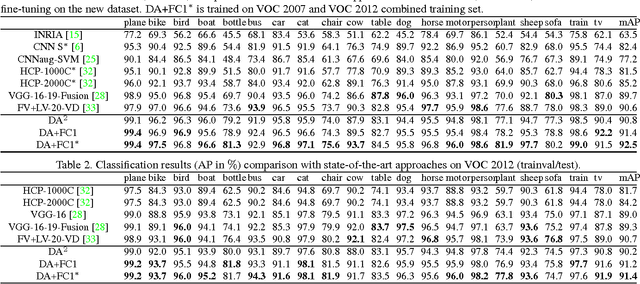

Recently, many researches employ middle-layer output of convolutional neural network models (CNN) as features for different visual recognition tasks. Although promising results have been achieved in some empirical studies, such type of representations still suffer from the well-known issue of semantic gap. This paper proposes so-called deep attribute framework to alleviate this issue from three aspects. First, we introduce object region proposals as intermedia to represent target images, and extract features from region proposals. Second, we study aggregating features from different CNN layers for all region proposals. The aggregation yields a holistic yet compact representation of input images. Results show that cross-region max-pooling of soft-max layer output outperform all other layers. As soft-max layer directly corresponds to semantic concepts, this representation is named "deep attributes". Third, we observe that only a small portion of generated regions by object proposals algorithm are correlated to classification target. Therefore, we introduce context-aware region refining algorithm to pick out contextual regions and build context-aware classifiers. We apply the proposed deep attributes framework for various vision tasks. Extensive experiments are conducted on standard benchmarks for three visual recognition tasks, i.e., image classification, fine-grained recognition and visual instance retrieval. Results show that deep attribute approaches achieve state-of-the-art results, and outperforms existing peer methods with a significant margin, even though some benchmarks have little overlap of concepts with the pre-trained CNN models.